Java es un lenguaje de programación creado por Sun Microsystems para poder funcionar en distintos tipos de procesadores. Su sintaxis es muy parecida a la de C o C++, e incorpora como propias algunas características que en otros lenguajes son extensiones: gestión de hilos, ejecución remota, etc.
El código Java, una vez compilado, puede llevarse sin modificación
alguna sobre cualquier máquina, y ejecutarlo. Esto se debe a que el código
se ejecuta sobre una máquina hipotética o virtual, la Java
Virtual Machine, que se encarga de interpretar el código (ficheros
compilados .class) y convertirlo a código particular
de la CPU que se esté utilizando (siempre que se soporte dicha máquina
virtual).
En el caso de los MIDs, este código intermedio Java se ejecutará sobre una versión reducida de la máquina virtual, la KVM (Kilobyte Virtual Machine).
Cuando se programa con Java, se dispone de antemano de un conjunto de clases ya implementadas. Estas clases (aparte de las que pueda hacer el usuario) forman parte del propio lenguaje (lo que se conoce como API (Application Programming Interface) de Java).
La API que se utilizará para programar las aplicaciones para MIDs será la API de MIDP, que contendrá un conjunto reducido de clases que nos permitan realizar las tareas fundamentales en estas aplicaciones. La implementación de esta API estará optimizada para ejecutarse en este tipo de dispositivos.
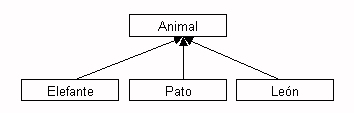
Con la herencia podemos definir una clase a partir de otra que ya exista, de forma que la nueva clase tendrá todas las variables y métodos de la clase a partir de la que se crea, más las variables y métodos nuevos que necesite. A la clase base a partir de la cual se crea la nueva clase se le llama superclase.
Figura 1. Ejemplo de herencia
Por ejemplo, tenemos una clase genérica Animal, y heredamos
de ella para formar clases más específicas, como Pato
, Elefante, o León. Si tenemos por ejemplo
el método dibuja(Animal a), podremos pasarle a este método
como parámetro tanto un Animal como un Pato, Elefante,
etc. Esto se conoce como polimorfismo .
Mediante las clases abstractas y los interfaces podemos definir
el esqueleto de una familia de clases, de forma que los subtipos de la clase
abstracta o la interfaz implementen ese esqueleto para dicho subtipo concreto.
Por ejemplo, podemos definir en la clase Animal el método
dibuja() y el método imprime(), y que Animal
sea una clase abstracta o un interfaz.
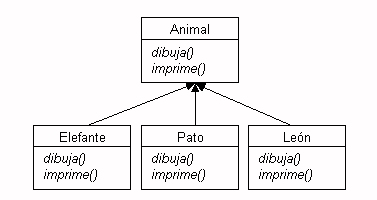
Figura 2. Ejemplo de interfaz y clase abstracta
Vemos la diferencia entre clase, clase abstracta e interfaz con este esquema:Animal tendríamos que
implementar los métodos dibuja() e imprime().
Las clases hijas no tendrían por qué implementar los métodos,
a no ser que quieran adaptarlos a sus propias necesidades.En un programa Java podemos distinguir varios elementos:
include" de C, permiten
utilizar clases en otras, y llamarlas de forma abreviada:import java.util.*;
public class
MiClase
{
...
public int a; Vector v;
return en la
función.public void imprimirA() public void insertarVector(String cadena)
public MiClase()
Así, podemos definir una instancia con new:
MiClase mc;
mc = new MiClase ();
mc.a++;
mc.insertarVector("hola");
No tenemos que preocuparnos de liberar la memoria del objeto al dejar de utilizarlo. Esto lo hace automáticamente el garbage collector. A diferencia de J2SE, en MIDP los objetos no tienen el método
finalize.
extends para decir
de qué clase se hereda. Para hacer que Pato herede de
Animal:class Pato extends Animal
this se usa para hacer referencia a los miembros de
la propia clase. Se utiliza cuando hay otros elementos con el mismo nombre,
para distinguir :public class MiClase {
int i;
public MiClase (int i) {
this.i = i; // i de la clase = parametro i
}
}
super se usa para llamar al mismo elemento en la clase
padre. Si la clase MiClase tiene un método Suma_a_i(...),
lo llamamos con:public class MiNuevaClase extends MiClase {
public void Suma_a_i (int j) {
i = i + (j / 2);
super.Suma_a_i (j);
}
}
public: cualquier objeto puede acceder al elementoprotected: sólo pueden acceder las subclases
de la clase.private: sólo pueden ser accedidos desde dentro
de la clase.abstract: elemento base para la herencia (los objetos
subtipo deberán definir este elemento).static: elemento compartido por todos los objetos
de la misma clase.final: objeto final, no modificable ni heredable.synchronized: para elementos a los que no se puede
acceder al mismo tiempo desde distintos hilos de ejecución.Animal), como clase abstracta o como interfaz, se declara
como sigue (respectivamente). También se indica cómo hacer una clase o interfaz
subtipo de la clase o interfaz padre (en este caso, la subclase es Pato): public interface Animal
{
void dibujar ();
void imprimir ();
}
|
public class Pato implements Animal
{
void dibujar() { codigo; }
void imprimir() { codigo; }
}
|
public abstract class Animal
{
abstract void dibujar ();
void imprimir () { codigo; }
}
|
public class Pato extends Animal
{
void dibujar() { codigo; }
} |
package permite agrupar
clases e interfaces. Los nombres de los paquetes son palabras separadas por
puntos, y se almacenan en directorios que coinciden con esos nombres. Así,
si definimos la clase:package paquete1.subpaquete1; public class MiClase1_1 ...
haremos que la clase
MiClase1_1pertenezca al subpaquetesubpaquete1del paquetepaquete1.Para utilizar las clases de un paquete utilizamos
import:
import java.Date; import paquete1.subpaquete1.*; import java.awt.*;
Para importar todas las clases del paquete se utiliza el asterisco*(aunque no vayamos a usarlas todas, si utilizamos varias de ellas puede ser útil simplificar con un asterisco). Si sólo queremos importar una o algunas pocas, se pone unimportpor cada una, terminando el paquete con el nombre de la clase en lugar del asterisco (como pasa conDateen el ejemplo).Al poner
importpodemos utilizar el nombre corto de la clase. Es decir, si ponemos:import java.Date; import java.util.*;Podemos hacer referencia a un objeto
Dateo a un objetoVector(una clase del paquetejava.util) con:Date d = ... Vector v = ...Si no pusiéramos los
import, deberíamos hacer referencia a los objetos con:java.Date d = ... java.util.Vector v = ...Es decir, cada vez que queramos poner el nombre de la clase, deberíamos colocar todo el nombre, con los paquetes y subpaquetes.
Cuando no especificamos el paquete al que pertenece una clase, esa clase será incluida en un paquete sin nombre. Al no tener nombre, no podremos importar este paquete desde otras clases pertenecientes a paquetes distintos, por lo que no podrán utilizar esta clase.
Cuando realicemos aplicaciones en Java es importante asignar un nombre de paquete a cada clase, de forma que puedan ser localizadas. El utilizar clases en paquetes sin nombre nos servirá únicamente si queremos hacer un programa de forma rápida para hacer alguna prueba, pero no se debe hacer en ningún otro caso.
La forma recomendada de asignar nombre a los paquetes de las aplicaciones que desarrollemos será similar a las DNS de Internet pero al revés, es decir, comenzaremos por el dominio, compañía, subunidad y nombre de la aplicación. Por ejemplo, si tenemos la URL
j2ee.ua.esy vamos a realizar una aplicación llamadaprueba, pondremos las clases en un paquetees.ua.j2ee.pruebao subpaquetes del mismo.
Tipos de datos
Se tienen los siguientes tipos de datos simples. Además, se pueden crear complejos, todos los cuales serán subtipos de
Object
Tipo Tamaño/Formato Descripción Ejemplos byte 8 bits, complemento a 2 Entero de 1 byte 210, 0x456 short 16 bits, complemento a 2 Entero corto " int 32 bits, complemento a 2 Entero " long 64 bits, complemento a 2 Entero largo " char 16 bits, carácter Carácter simple 'a' boolean true / false verdadero / falso true, false Aquí desaparecen los tipos
floatydoubleque podíamos usar en otras ediciones de Java. Esto es debido a que la KVM no tiene soporte para estos tipos, ya que las operaciones con números reales son complejas y estos dispositivos muchas veces no tienen unidad de punto flotante.Las aplicaciones J2ME para dispositivos CDC si que podrán usar estos tipos de datos, ya que funcionarán con la máquina virtual CVM que si que soporta estos tipos. Por lo tanto la limitación no es de J2ME, sino de la máquina virtual KVM en la que se basan las aplicaciones CLDC.
NOTA: En CLDC 1.1 se incorporan los tipos de datos
doubleyfloat. En los dispositivos que soporten esta versión de la API podremos utilizar estos tipos de datos.Cadenas
Para trabajar con cadenas de caracteres se utiliza la clase
String. Un valor posible para este tipo de datos es"Hola mundo". Cuando escribamos una cadena de este tipo dentro del código Java, se creará un objetoStringencapsulando dicha cadena.Si trabajamos con cadenas largas, o vamos a realizar bastantes operaciones que modifiquen la cadena, será conveniente utilizar
StringBuffer, ya que se trata de una implementación más eficiente. La claseStringno permite modificar el contenido de la cadena, por lo que cualquier modificación implicará reservar más memoria.StringBuffersi que nos permite modificar el buffer interno donde almacena la cadena, de forma que podremos hacer modificaciones sin tener que instanciar nuevos objetos.Arrays
Se definen arrays o conjuntos de elementos de forma similar a como se hace en C. Hay 2 métodos:
int a[] = new int [10]; String s[] = {"Hola", "Adios"};No pueden crearse arrays estáticos en tiempo de compilación (int a[8];), ni rellenar un array sin definir previamente su tamaño con el operadornew. La función miembrolengthse puede utilizar para conocer la longitud del array:int a [][] = new int [10] [3]; a.length; // Devolvería 10 a[0].length; // Devolvería 3Los arrays empiezan a numerarse desde 0, hasta el tope definido menos uno (como en C).Identificadores
Nombran variables, funciones, clases y objetos. Comienzan por una letra, carácter de subrayado
_o símbolo$. El resto de caracteres pueden ser letras o dígitos (o_). Se distinguen mayúsculas de minúsculas, y no hay longitud máxima. Las variables en Java sólo son válidas desde el punto donde se declaran hasta el final de la sentencia compuesta (las llaves) que la engloba. No se puede declarar una variable con igual nombre que una del mismo ámbito.En Java se tiene también un término NULL, pero si bien el de C es con mayúsculas (
NULL), éste es con minúsculas (null):String a = null; ... if (a == null)...Referencias
En Java no existen punteros, simplemente se crea otro objeto que referencie al que queremos "apuntar".
mc2ymcapuntan a la misma variable (al cambiar una cambiará la otra).Tendremos dos objetos apuntando a elementos diferentes en memoria. Comentarios
// comentarios para una sola línea /* comentarios de una o más líneas */ /** comentarios de documentación para javadoc, de una o más líneas */OperadoresSe muestra una tabla con los operadores en orden de precedencia
Operador Ejemplo Descripción . a.length Campo o método de objeto [ ] a[6] Referencia a elemento de array ( ) (a + b) Agrupación de operaciones ++ , -- a++; b-- Autoincremento / Autodecremento de 1 unidad !, ~ !a ; ~b Negación / Complemento instanceof a instanceof TipoDato Indica si a es del tipo TipoDato *, /, % a*b; b/c; c%a Multiplicación, división y resto de división entera +, - a+b; b-c Suma y resta <<, >> a>>2; b<<1 Desplazamiento de bits a izquierda y derecha <, >, <=, >=, ==, != a>b; b==c; c!=a Comparaciones (mayor, menor, igual, distinto...) &, |, ^ a&b; b|c AND, OR y XOR lógicas &&, || a&&b; b||c AND y OR condicionales ?: a?b:c Condicional: si a entonces b , si no c =, +=, -=, *=, /= ... a=b; b*=c Asignación. a += b equivale a (a = a + b) Puesto que con la KVM no tenemos soporte para números reales, la operación de división será entera. Nos devolverá un valor entero.
Control de flujo
TOMA DE DECISIONES
Este tipo de sentencias definen el código que debe ejecutarse si se cumple una determinada condición. Se dispone de sentencias
ify de sentenciasswitch:
Sintaxis Ejemplos if (condicion1) { sentencias; } else if (condicion2) { sentencias; ... } else if(condicionN) { sentencias; } else { sentencias; }if (a == 1) { b++; } else if (b == 1) { c++; } else if (c == 1) { d++; }switch (condicion) { case caso1: sentencias; case caso2: sentencias; case casoN: sentencias; default: sentencias; }switch (a) { case 1: b++; break; case 2: c++; break; default:b--; break; }BUCLES
Para repetir un conjunto de sentencias durante un determinado número de iteraciones se tienen las sentencias
for,whileydo...while:
Sintaxis Ejemplo for(inicio;condicion; incremento) { sentencias; }for (i=1;i<10;i++) { b = b+i; }while (condicion){ sentencias; }while (i < 10) { b += i; i++; }do{ sentencias; } while (condicion);do { b += i; i++; } while (i < 10);SENTENCIAS DE RUPTURA
Se tienen las sentencias
break(para terminar la ejecución de un bloque o saltar a una etiqueta),continue(para forzar una ejecución más de un bloque o saltar a una etiqueta) yreturn(para salir de una función devolviendo o sin devolver un valor):public int miFuncion(int n) { int i = 0; while (i < n) { i++; if (i > 10) // Sale del while break; if (i < 5) // Fuerza una iteracion mas continue; } // Devuelve lo que valga i al llegar aquí return i; }
Números reales
En CLDC 1.0 echamos en falta el soporte para número de coma flotante
(float y double). En principio podemos pensar que
esto es una gran limitación, sobretodo para aplicaciones que necesiten
trabajar con valores de este tipo. Por ejemplo, si estamos trabajando con información
monetaria para mostrar el precio de los productos necesitaremos utilizar números
como 13.95€.
Sin embargo, en muchos casos podremos valernos de los números enteros
para representar estos números reales. Vamos a ver un truco con el que
implementar soporte para números reales de coma fija mediante datos de
tipo entero (int).
Este truco consiste en considerar un número N fijo de decimales, por ejemplo en el caso de los precios podemos considerar que van a tener 2 decimales. Entonces lo que haremos será trabajar con números enteros, considerando que las N últimas cifras son los decimales. Por ejemplo, si un producto cuesta 13.95€, lo guardaremos en una variable entera con valor 1395, es decir, en este caso es como si estuviésemos guardando la información en céntimos.
Cuando queramos mostrar este valor, deberemos separar la parte entera y la fraccionaria para imprimirlo con el formato correspondiente a un número real. Haremos la siguiente transformación:
public String imprimeReal(int numero) {
int entero = numero / 100;
int fraccion = numero % 100;
return entero + "." + fraccion;
}
Cuando el usuario introduzca un número con formato real, y queramos
leerlo y guardarlo en una variable de tipo entero (int) deberemos
hacer la transformación contraria:
public int leeReal(String numero) {
int pos_coma = numero.indexOf('.');
String entero = numero.substring(0, pos_coma - 1);
String fraccion = numero.substring(pos_coma + 1, pos_coma + 2);
return Integer.parseInt(entero)*100 + Integer.parseInt(fraccion);
}
Es posible que necesitemos realizar operaciones básicas con estos números reales. Podremos realizar operaciones como suma, resta, multiplicación y división utilizando la representación como enteros de estos números.
El caso de la suma y de la resta es sencillo. Si sumamos o restamos dos números con N decimales cada uno, podremos sumarlos como si fuesen enteros y sabremos que las últimas N cifras del resultado son decimales. Por ejemplo, si queremos añadir dos productos a la cesta de la compra, cuyos precios son 13.95€ y 5.20€ respectivamente, deberemos sumar estas cantidades para obtener el importe total. Para ello las trataremos como enteros y hacemos la siguiente suma:
1395 + 520 = 1915
Por lo tanto, el resultado de la suma de los números reales será 19.15€.
El caso de la multiplicación es algo más complejo. Si queremos multiplicar dos números, con N y M decimales respectivamente, podremos hacer la multiplicación como si fuesen enteros sabiendo que el resultado tendrá N+M decimales. Por ejemplo, si al importe anterior de 19.15€ queremos añadirle el IVA, tendremos que multiplicarlo por 1.16. Haremos la siguiente operación entera:
1915 * 116 = 222140
El resultado real será 22.2140€, ya que si cada operando tenía 2 decimales, el resultado tendrá 4.
Si estas operaciones básicas no son suficiente podemos utilizar una
librería como MathFP, que nos permitirá realizar
operaciones más complejas con números de coma fija representados
como enteros. Entre ellas tenemos disponibles operaciones trigonométricas,
logarítmicas, exponenciales, potencias, etc. Podemos descargar esta librería
de http://www.jscience.net/ e incluirla libremente en nuestra aplicaciones
J2ME.
Vamos a ver las características básicas del lenguaje Java (plataforma J2SE) que tenemos disponibles en la API CLDC de los dispositivos móviles. Dentro de esta API tenemos la parte básica del lenguaje que debe estar disponible en cualquier dispositivo conectado limitado.
Esta API básica se ha tomado directamente de J2SE, de forma que los programadores que conozcan el lenguaje Java podrán programar de forma sencilla aplicaciones para dispositivos móviles sin tener que aprender a manejar una API totalmente distinta. Sólo tendrán que aprender a utilizar la parte de la API propia de estos dispositivos móviles, que se utiliza para características que sólo están presentes en estos dispositivos.
Dado que estos dispositivos tienen una capacidad muy limitada, en CLDC sólo está disponible una parte reducida de esta API de Java. Vamos a ver en este punto qué características de las que ya conocemos del lenguaje Java están presentes en CLDC para programar en dispositivos móviles.
Las excepciones son eventos que ocurren durante la ejecución de un programa y hacen que éste salga de su flujo normal de instrucciones. Este mecanismo permite tratar los errores de una forma elegante, ya que separa el código para el tratamiento de errores del código normal del programa. Se dice que una excepción es lanzada cuando se produce un error, y esta excepción puede ser capturada para tratar dicho error.
Tipos de excepciones
Tenemos diferentes tipos de excepciones dependiendo del tipo de error que representen.
Todas ellas descienden de la clase Throwable, la cual tiene dos
descendientes directos:
Error: Se refiere a errores graves en la máquina
virtual de Java, como por ejemplo fallos al enlazar con alguna librería.
Normalmente en los programas Java no se tratarán este tipo de errores.Exception: Representa errores que no son críticos y
por lo tanto pueden ser tratados y continuar la ejecución de la aplicación.
La mayoría de los programas Java utilizan estas excepciones para el
tratamiento de los errores que puedan ocurrir durante la ejecución
del código.Dentro de Exception, cabe destacar una subclase especial de excepciones
denominada RuntimeException, de la cual derivarán todas
aquellas excepciones referidas a los errores que comúnmente se pueden
producir dentro de cualquier fragmento de código, como por ejemplo hacer
una referencia a un puntero null, o acceder fuera de los límites
de un array.
Estas RuntimeException se diferencian del resto de excepciones en que no son
de tipo checked. Una excepción de tipo checked debe ser
capturada o bien especificar que puede ser lanzada de forma obligatoria, y si
no lo hacemos obtendremos un error de compilación. Dado que las RuntimeException
pueden producirse en cualquier fragmento de código, sería impensable
tener que añadir manejadores de excepciones y declarar que éstas
pueden ser lanzadas en todo nuestro código.
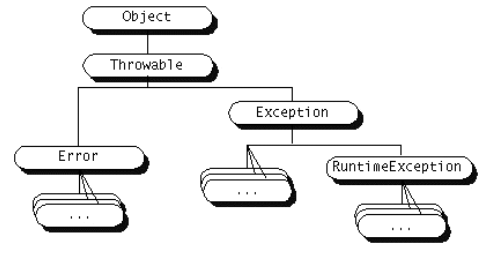
Figura 3. Tipos de excepciones
Dentro de estos grupos principales de excepciones podremos encontrar tipos concretos de excepciones o bien otros grupos que a su vez pueden contener más subgrupos de excepciones, hasta llegar a tipos concretos de ellas. Cada tipo de excepción guardará información relativa al tipo de error al que se refiera, además de la información común a todas las excepciones.
Captura de excepciones
Cuando un fragmento de código sea susceptible de lanzar una excepción
y queramos tratar el error producido o bien por ser una excepción de
tipo checked debamos capturarla, podremos hacerlo mediante la estructura
try-catch-finally, que consta de tres bloques de código:
try: Contiene el código regular de nuestro programa
que puede producir una excepción en caso de error.catch: Contiene el código con el que trataremos
el error en caso de producirse.finally: Este bloque contiene el código que se
ejecutará al final tanto si se ha producido una excepción como
si no lo ha hecho. Este bloque se utiliza para, por ejemplo, cerrar algún
flujo que haya podido ser abierto dentro del código regular del programa,
de manera que nos aseguremos que tanto si se ha producido un error como si
no este flujo se cierre. El bloque finally no es obligatorio
ponerlo.Para el bloque catch además deberemos especificar el tipo
o grupo de excepciones que tratamos en dicho bloque, pudiendo incluir varios
bloques catch, cada uno de ellos para un tipo/grupo de excepciones
distinto. La forma de hacer esto será la siguiente:
try { // Código regular del programa // Puede producir excepciones } catch(TipoDeExcepcion1 e1) { // Código que trata las excepciones de tipo // TipoDeExcepcion1 o subclases de ella. // Los datos sobre la excepción los encontraremos // en el objeto e1. } catch(TipoDeExcepcion2 e2) { // Código que trata las excepciones de tipo // TipoDeExcepcion2 o subclases de ella. // Los datos sobre la excepción los encontraremos // en el objeto e2. ... } catch(TipoDeExcepcionN eN) { // Código que trata las excepciones de tipo // TipoDeExcepcionN o subclases de ella. // Los datos sobre la excepción los encontraremos // en el objeto eN. } finally { // Código de finalización (opcional) }
Si como tipo de excepción especificamos un grupo de excepciones este
bloque se encargará de la captura de todos los subtipos de excepciones
de este grupo. Por lo tanto, si especificamos Exception capturaremos
cualquier excepción, ya que está es la superclase común
de todas las excepciones.
En el bloque catch pueden ser útiles algunos métodos de la excepción
(que podemos ver en la API de la clase padre Exception):
String getMessage() void printStackTrace()
con getMessage obtenemos una cadena descriptiva del error (si
la hay). Con printStackTrace se muestra por la salida estándar
la traza de errores que se han producido (en ocasiones la traza es muy larga
y no puede seguirse toda en pantalla con algunos sistemas operativos).
Normalmente en los dispositivos móviles cuando imprimimos por la salida estándar se ignorará lo que estamos imprimiendo (se envía a un dispositivo null), por lo que imprimir esta traza en el dispositivo no tiene mucho sentido. Puede resultar útil para depurar la aplicación mientras la estemos probando en emuladores, ya que en este caso cuando imprimamos por la salida estándar veremos los mensajes en la consola.
Un ejemplo de uso:
try
{
... // Aqui va el codigo que puede lanzar una excepcion
} catch (Exception e) {
muestraAlerta("El error es: " + e.getMessage());
e.printStackTrace();
}
Lanzamiento de excepciones
Hemos visto cómo capturar excepciones que se produzcan en el código, pero en lugar de capturarlas también podemos hacer que se propaguen al método de nivel superior (desde el cual se ha llamado al método actual). Para esto, en el método donde se vaya a lanzar la excepción, se siguen 2 pasos:
public void lee_datos()
throws IOException, ClassNotFoundException
{
// Cuerpo de la función
}
Podremos indicar tantos tipos de excepciones como queramos en la cláusula
throws. Si alguna de estas clases de excepciones tiene subclases, también se considerará que puede lanzar todas estas subclases.
throw,
proporcionándole un objeto correspondiente al tipo de excepción
que deseamos lanzar. Por ejemplo:throw new ClassNotFoundException(mensaje_error);
public void lee_datos()
throws IOException, ClassNotFoundException
{
...
throw new ClassNotFoundException(mensaje_error);
...
}
Podremos lanzar así excepciones en nuestras funciones para indicar que algo no es como debiera ser a las funciones llamadoras.
NOTA: para las excepciones que no son de tipo checked no hará
falta la cláusula throws en la declaración del método, pero seguirán
el mismo comportamiento que el resto, si no son capturadas pasarán al
método de nivel superior, y seguirán así hasta llegar a la función
principal, momento en el que si no se captura provocará la salida de
nuestro programa mostrando el error correspondiente.
Creación de nuevas excepciones
Además de utilizar los tipos de excepciones contenidos en la distribución de Java, podremos crear nuevos tipos que se adapten a nuestros problemas.
Para crear un nuevo tipo de excepciones simplemente deberemos crear una clase
que herede de Exception o cualquier otro subgrupo de excepciones
existente. En esta clase podremos añadir métodos y propiedades
para almacenar información relativa a nuestro tipo de error. Por ejemplo:
public class MiExcepcion extends Exception
{
public MiExcepcion (String mensaje)
{
super(mensaje);
}
}
Además podremos crear subclases de nuestro nuevo tipo de excepción, creando de esta forma grupos de excepciones. Para utilizar estas excepciones (capturarlas y/o lanzarlas) hacemos lo mismo que lo explicado antes para las excepciones que se tienen definidas en Java.
Un hilo es un flujo de control dentro de un programa. Creando varios hilos podremos realizar varias tareas simultáneamente. Cada hilo tendrá sólo un contexto de ejecución (contador de programa, pila de ejecución). Es decir, a diferencia de los procesos UNIX, no tienen su propio espacio de memoria sino que acceden todos al mismo espacio de memoria común, por lo que será importante su sincronización cuando tengamos varios hilos accediendo a los mismos objetos.
Creación de hilos
En Java los hilos están encapsulados en la clase Thread.
Para crear un hilo tenemos dos posibilidades:
Thread redefiniendo el método run.Runnable que nos
obliga a definir el método run.En ambos casos debemos definir un método run que será
el que contenga el código del hilo. Desde dentro de este método
podremos llamar a cualquier otro método de cualquier objeto, pero este
método run será el método que se invoque cuando
iniciemos la ejecución de un hilo. El hilo terminará su ejecución
cuando termine de ejecutarse este método run.
Para crear nuestro hilo mediante herencia haremos lo siguiente:
public class EjemploHilo extends Thread
{
public void run() {
// Código del hilo
}
}
Una vez definida la clase de nuestro hilo deberemos instanciarlo y ejecutarlo de la siguiente forma:
Thread t = new EjemploHilo(); t.start();
Crear un hilo heredando de Thread tiene el problema de que al
no haber herencia múltiple en Java, si heredamos de Thread
no podremos heredar de ninguna otra clase, y por lo tanto un hilo no podría
heredar de ninguna otra clase.
Este problema desaparece si utilizamos la interfaz Runnable para
crear el hilo, ya que una clase puede implementar varios interfaces. Definiremos
la clase que contenga el hilo como se muestra a continuación:
public class EjemploHilo implements Runnable
{
public void run() {
// Código del hilo
}
}
Para instanciar y ejecutar un hilo de este tipo deberemos hacer lo siguiente:
Thread t = new Thread(new EjemploHilo()); t.start();
Esto es así debido a que en este caso EjemploHilo no deriva
de una clase Thread, por lo que no se puede considerar un hilo,
lo único que estamos haciendo implementando la interfaz es asegurar que
vamos a tener definido el método run. Con esto lo que haremos
será proporcionar esta clase al constructor de la clase Thread,
para que el objeto Thread que creemos llame al método run
de la clase que hemos definido al iniciarse la ejecución del hilo, ya
que implementando la interfaz aseguramos que esta función existe.
Estado y propiedades de los hilos
Un hilo pasará por varios estados durante su ciclo de vida.
Thread t = new Thread(this);
Una vez se ha instanciado el objeto del hilo, diremos que está en estado de Nuevo hilo.
t.start();
Cuando invoquemos su método start el hilo pasará
a ser un hilo vivo, comenzándose a ejecutar su método run.
Una vez haya salido de este método pasará a ser un hilo muerto.
La única forma de parar un hilo es hacer que salga del método
run de forma natural. Podremos conseguir esto haciendo que se cumpla
la condición de salida del bucle principal definido dentro del run.
Las funciones para parar, pausar y reanudar hilos estás desaprobadas
en las versiones actuales de Java.
Mientras el hilo esté vivo, podrá encontrarse en dos estados: Ejecutable y No ejecutable. El hilo pasará de Ejecutable a No ejecutable en los siguientes casos:
sleep,
permanecerá No ejecutable hasta haber transcurrido el número
de milisegundos especificados.wait
esperando que otro hilo lo desbloquee llamando a notify o notifyAll.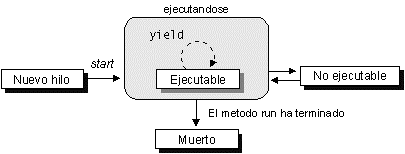
Figura 4. Ciclo de vida de los hilos
Lo único que podremos saber es si un hilo se encuentra vivo o no, llamando
a su método isAlive.
Además, una propiedad importante de los hilos será su prioridad.
Mientras el hilo se encuentre vivo, el scheduler de la máquina
virtual Java le asignará o lo sacará de la CPU, coordinando así
el uso de la CPU por parte de todos los hilos activos basándose en su
prioridad. Se puede forzar la salida de un hilo de la CPU llamando a su método
yield. También se sacará un hilo de la CPU cuando
un hilo de mayor prioridad se haga Ejecutable, o cuando el tiempo que
se le haya asignado expire.
Para cambiar la prioridad de un hilo se utiliza el método setPriority,
al que deberemos proporcionar un valor de prioridad entre MIN_PRIORITY
y MAX_PRIORITY.
Sincronización de hilos
Muchas veces los hilos deberán trabajar de forma coordinada, por lo que es necesario un mecanismo de sincronización entre ellos.
Un primer mecanismo de comunicación es la variable cerrojo incluida
en todo objeto Object, que permitirá evitar que más
de un hilo entre en la sección crítica. Los métodos declarados
como synchronized utilizan el cerrojo de la clase a la que pertenecen
evitando que más de un hilo entre en ellos al mismo tiempo.
public synchronized void seccion_critica()
{
// Código sección crítica
}
También podemos utilizar cualquier otro objeto para la sincronización dentro de nuestro método de la siguiente forma:
synchronized (objeto_con_cerrojo)
{
// Código sección crítica
}
Además podemos hacer que un hilo quede bloqueado a la espera de que
otro hilo lo desbloquee cuando suceda un determinado evento. Para bloquear un
hilo usaremos la función wait, para lo cual el hilo que
llama a esta función debe estar en posesión del monitor, cosa
que ocurre dentro de un método synchronized, por lo que
sólo podremos bloquear a un proceso dentro de estos métodos.
Para desbloquear a los hilos que haya bloqueados se utilizará notifyAll,
o bien notify para desbloquear sólo uno de ellos aleatoriamente.
Para invocar estos métodos ocurrirá lo mismo, el hilo deberá
estar en posesión del monitor.
Cuando un hilo queda bloqueado liberará el cerrojo para que otro hilo pueda entrar en la sección crítica y desbloquearlo.
Por último, puede ser necesario esperar a que un determinado hilo haya
finalizado su tarea para continuar. Esto lo podremos hacer llamando al método
join de dicho hilo, que nos bloqueará hasta que el hilo
haya finalizado.
En la API de CLDC no están presentes los grupos de hilos. La clase ThreadGroup
de la API de J2SE no existe en la API de CLDC, por lo que no podremos utilizar
esta característica desde los MIDs. Tampoco podemos ejecutar hilos como
demonios (daemon).
En J2SE existe lo que se conoce como marco de colecciones, que comprende una serie de tipos de datos. Estos tipos de datos se denominan colecciones por ser una colección de elementos, tenemos distintos subtipos de colecciones como las listas (secuencias de elementos), conjuntos (colecciones sin elementos repetidos) y mapas (conjunto de parejas <clave, valor>). Tendremos varias implementaciones de estos tipos de datos, siendo sus operadores polimórficos, es decir, se utilizan los mismos operadores para distintos tipos de datos. Para ello se definen interfaces que deben implementar estos tipos de datos, una serie de implementaciones de estas interfaces y algoritmos para trabajar con ellos.
Sin embargo, en CLDC no tenemos este marco de colecciones. Al tener que utilizar
una API tan reducida como sea posible, tenemos solamente las clases Vector
(tipo lista), Stack (tipo pila) y Hashtable (mapa)
tal como ocurría en las primeras versiones de Java. Estas clases son
independientes, no implementan ninguna interfaz común.
Enumeraciones
Para consultar las colecciones de elementos que contienen estos tipos de datos,
podemos utilizar las enumeraciones. En J2SE teníamos la posibilidad de
utilizar también iteradores, pero la clase Iterator no está
disponible en CLDC.
Las enumeraciones, definidas mediante la interfaz Enumeration,
nos permiten consultar los elementos que contiene una colección de datos.
Muchos métodos de clases Java que deben devolver múltiples valores,
lo que hacen es devolvernos una enumeración que podremos consultar mediante
los métodos que ofrece dicha interfaz.
La enumeración irá recorriendo secuencialmente los elementos de la colección. Para leer cada elemento de la enumeración deberemos llamar al método:
Object item = enum.nextElement();
Que nos proporcionará en cada momento el siguiente elemento de la enumeración a leer. Además necesitaremos saber si quedan elementos por leer, para ello tenemos el método:
enum.hasMoreElements()
Normalmente, el bucle para la lectura de una enumeración será el siguiente:
while (enum.hasMoreElements()) {
Object item = enum.nextElement();
// Hacer algo con el item leido
}
Vemos como en este bucle se van leyendo y procesando elementos de la enumeración uno a uno mientras queden elementos por leer en ella.
Vector
Implementa una lista de elementos mediante un array de tamaño variable. Conforme se añaden elementos el tamaño del array irá creciendo si es necesario. El array tendrá una capacidad inicial, y en el momento en el que se rebase dicha capacidad, se aumentará el tamaño del array.
Las operaciones de añadir un elemento al final del array (add), y de establecer u obtener el elemento en una determinada posición (get/set) tienen un coste temporal constante. Las inserciones y borrados tienen un coste lineal O(n), donde n es el número de elementos del array.
Los métodos que tenemos para trabajar con el Vector son
los métodos que tenía en las primeras versiones de Java:
void addElement(Object obj)
Añade un elemento al final del vector.
Object elementAt(int indice)
Devuelve el elemento de la posición del vector indicada por el índice.
void insertElementAt(Object obj, int indice)
Inserta un elemento en la posición indicada.
boolean removeElement(Object obj)
Elimina el elemento indicado del vector, devolviendo true si dicho
elemento estaba contenido en el vector, y false en caso contrario.
void removeElementAt(int indice)
Elimina el elemento de la posición indicada en el índice.
void setElementAt(Object obj, int indice)
Sobrescribe el elemento de la posición indicada con el objeto especificado.
int size()
Devuelve el número de elementos del vector.
Stack
Sobre el vector se construye el tipo pila (Stack), que apoyándose
en el tipo vector ofrece métodos para trabajar con dicho vector como
si se tratase de una pila, apilando y desapilando elementos (operaciones push
y pop respectivamente). La clase Stack hereda
de Vector, por lo que en realidad será un vector que ofrece
métodos adicionales para trabajar con él como si fuese una pila.
Hashtable
Relaciona una clave (key) con un valor. Contendrá un conjunto de claves, y a cada clave se le asociará un determinado valor. Tanto la clave como el valor puede ser cualquier objeto. Lo que contendrá este tipo de dato será una colección de parejas <clave, valor>.
Los métodos básicos para trabajar con estos elementos son los siguientes:
Object get(Object clave)
Nos devuelve el valor asociado a la clave indicada
Object put(Object clave, Object valor)
Inserta una nueva clave con el valor especificado. Nos devuelve el valor que
tenía antes dicha clave, o null si la clave no estaba en
la tabla todavía.
Object remove(Object clave)
Elimina una clave, devolviéndonos el valor que tenía dicha clave.
Enumeration keys()
Este método nos devolverá una enumeración de todas las claves registradas en la tabla.
int size()
Nos devuelve el número de parejas <clave,valor> registradas.
Wrappers de tipos básicos
Hemos visto que en Java cualquier tipo de datos es un objeto, excepto los tipos
de datos básicos: boolean, int, long,
byte, short, char.
Cuando trabajamos con estos tipos de datos los elementos que contienen éstos
son siempre objetos, por lo que en un principio no podríamos insertar
elementos de estos tipos básicos. Para hacer esto posible tenemos una
serie de objetos que se encargarán de envolver a estos tipos básicos,
permitiéndonos tratarlos como objetos y por lo tanto insertarlos como
elementos de colecciones. Estos objetos son los llamados wrappers,
y las clases en las que se definen tienen nombres similares al del tipo básico
que encapsulan, con la diferencia de que comienzan con mayúscula: Boolean,
Integer, Long, Byte, Short,
Character.
Estas clases, además de servirnos para encapsular estos datos básicos en forma de objetos, nos proporcionan una serie de métodos e información útiles para trabajar con estos datos. Nos proporcionarán métodos por ejemplo para convertir cadenas a datos numéricos de distintos tipos y viceversa, así como información acerca del valor mínimo y máximo que se puede representar con cada tipo numérico.
NOTA: Dado que a partir de CLDC 1.1 se incorporan los tipos de datos float
y double, aparecerán también sus correspondientes
wrappers: Float y Double.
Vamos a ver ahora una serie de clases básicas del lenguaje Java que siguen estando en CLDC. La versión de CLDC de estas clases estará normalmente más limitada, a continuación veremos las diferencias existentes entre la versión de J2SE y la de CLDC.
Object
Esta es la clase base de todas las clases en Java, toda clase hereda en última
instancia de la clase Object, por lo que los métodos que
ofrece estarán disponibles en cualquier objeto Java, sea de la clase
que sea.
En Java es importante distinguir claramente entre lo que es una variable, y lo que es un objeto. Las variables simplemente son referencias a objetos, mientras que los objetos son las entidades instanciadas en memoria que podrán ser manipulados mediante las referencias que tenemos a ellos (mediante variable que apunten a ellos) dentro de nuestro programa. Cuando hacemos lo siguiente:
new MiClase()
Se está instanciando en memoria un nuevo objeto de clase MiClase
y nos devuelve una referencia a dicho objeto. Nosotros deberemos guardarnos
dicha referencia en alguna variable con el fin de poder acceder al objeto creado
desde nuestro programa:
MiClase mc = new MiClase();
Es importante declarar la referencia del tipo adecuado (en este caso tipo MiClase)
para manipular el objeto, ya que el tipo de la referencia será el que
indicará al compilador las operaciones que podremos realizar con dicho
objeto. El tipo de esta referencia podrá ser tanto el mismo tipo del
objeto al que vayamos a apuntar, o bien el de cualquier clase de la que herede
o interfaz que implemente nuestro objeto. Por ejemplo, si MiClase
se define de la siguiente forma:
public class MiClase extends Thread implements List {
...
}
Podremos hacer referencia a ella de diferentes formas:
MiClase mc = new MiClase(); Thread t = new MiClase(); List l = new MiClase(); Object o = new MiClase();
Esto es así ya que al heredar tanto de Thread como de Object,
sabemos que el objeto tendrá todo lo que tienen estas clases más
lo que añada MiClase, por lo que podrá comportarse
como cualquiera de las clases anteriores. Lo mismo ocurre al implementar una
interfaz, al forzar a que se implementen sus métodos podremos hacer referencia
al objeto mediante la interfaz ya que sabemos que va a contener todos esos métodos.
Siempre vamos a poder hacer esta asignación 'ascendente' a clases o interfaces
de las que deriva nuestro objeto.
Si hacemos referencia a un objeto MiClase mediante una referencia
Object por ejemplo, sólo podremos acceder a los métodos
de Object, aunque el objeto contenga métodos adicionales
definidos en MiClase. Si conocemos que nuestro objeto es de tipo
MiClase, y queremos poder utilizarlo como tal, podremos hacer una
asignación 'descendente' aplicando una conversión cast
al tipo concreto de objeto:
Object o = new MiClase(); ... MiClase mc = (MiClase) o;
Si resultase que nuestro objeto no es de la clase a la que hacemos cast,
ni hereda de ella ni la implementa, esta llamada resultará en un ClassCastException
indicando que no podemos hacer referencia a dicho objeto mediante esa interfaz
debido a que el objeto no la cumple, y por lo tanto podrán no estar disponibles
los métodos que se definen en ella.
Una vez hemos visto la diferencia entre las variables (referencias) y objetos (entidades) vamos a ver como se hará la asignación y comparación de objetos. Si hiciésemos lo siguiente:
MiClase mc1 = new MiClase(); MiClase mc2 = mc1;
Puesto que hemos dicho que las variables simplemente son referencias a objetos,
la asignación estará copiando una referencia, no el objeto. Es
decir, tanto la variable mc1 como mc2 apuntarán
a un mismo objeto.
En J2SE la clase Object tiene un método clone
que podemos utilizar para realizar una copia del objeto, de forma que tengamos
dos objetos independientes en memoria con el mismo contenido. Este método
no existe en CLDC, por lo que si queremos realizar una copia de un objeto deberemos
definir un constructor de copia, es decir, un constructor que construya un nuevo
objeto copiando todas las propiedades de otro objeto de la misma clase.
Por ejemplo, si tenemos una clase Punto2D, cuyas propiedades sean
las coordenadas (x,y) del punto, podemos definir un constructor de
copia como se muestra a continuación:
public class Punto2D {
public int x, y;
...
public Punto2D(Punto2D p) {
this.x = p.x;
this.y = p.y
}
}
Por otro lado, para la comparación, si hacemos lo siguiente:
mc1 == mc2
Estaremos comparando referencias, por lo que estaremos viendo si las dos referencias apuntan a un mismo objeto, y no si los objetos a los que apuntan son iguales. Para ver si los objetos son iguales, aunque sean entidades distintas, tenemos:
mc1.equals(mc2)
Este método también es propio de la clase Object,
y será el que se utilice para comparar internamente los objetos.
El método equals, deberá ser redefinido en nuestras
clases para adaptarse a éstas. Deberemos especificar dentro de él
como se compara si dos objetos de esta clase son iguales:
public class Punto2D {
public int x, y;
...
public boolean equals(Object o) {
Punto2D p = (Punto2D)o;
// Compara objeto this con objeto p
return (x == p.x && y == p.y);
}
}
Un último método interesante de la clase Object
es toString. Este método nos devuelve una cadena (String)
que representa dicho objeto. Por defecto nos dará un identificador del
objeto, pero nosotros podemos sobrescribirla en nuestras propias clases para
que genere la cadena que queramos. De esta manera podremos imprimir el objeto
en forma de cadena de texto, mostrándose los datos con el formato que
nosotros les hayamos dado en toString. Por ejemplo, si tenemos
una clase Punto2D, sería buena idea hacer que su conversión
a cadena muestre las coordenadas (x,y) del punto:
public class Punto2D {
public int x,y;
...
public String toString() {
String s = "(" + x + "," + y + ")";
return s;
}
}
System
Esta clase nos ofrece una serie de métodos y campos útiles del sistema. Esta clase no se debe instanciar, todos estos métodos y campos son estáticos.
Podemos encontrar los objetos que encapsulan la salida y salida de error estándar como veremos con más detalle en el apartado de entrada/salida. A diferencia de J2SE, en CLDC no tenemos entrada estándar.
Tampoco nos permite instalar un gestor de seguridad para la aplicación. La API de CLDC y MIDP ya cuenta con las limitaciones suficientes para que las aplicaciones sean seguras.
Otros métodos útiles que encontramos son:
void exit(int estado)
Finaliza la ejecución de la aplicación, devolviendo un código
de estado. Normalmente el código 0 significa que ha salido
de forma normal, mientras que con otros códigos indicaremos que se ha
producido algún error. Este método produce que se cierre la máquina
virtual de Java, normalmente no utilizaremos este método directamente
en las aplicaciones MIDP, haremos que el AMS sea quien cierre la aplicación,
como veremos más adelante.
void gc()
Fuerza una llamada al colector de basura para limpiar la memoria. Esta es una operación costosa. Normalmente no lo llamaremos explícitamente, sino que dejaremos que Java lo invoque cuando sea necesario.
long currentTimeMillis()
Nos devuelve el tiempo medido en el número de milisegundos transcurridos desde el 1 de Enero de 1970 a las 0:00.
void arraycopy(Object fuente, int pos_fuente, Object destino, int pos_dest, int n)
Copia n elementos del array fuente, desde la
posición pos_fuente, al array destino
a partir de la posición pos_dest.
String getProperty(String key)
En CLDC no tenemos una clase Properties con una colección
de propiedades. Por esta razón, cuando leamos propiedades del sistema
no podremos obtenerlas en un objeto Properties, sino que tendremos
que leerlas individualmente. Estas son propiedades del sistema, no son los propiedades
del usuario que aparecen en el fichero JAD. En el próximo tema veremos
cómo leer estas propiedades del usuario.
Runtime
Toda aplicación Java tiene una instancia de la clase Runtime
que se encargará de hacer de interfaz con el entorno en el que se está
ejecutando. Para obtener este objeto debemos utilizar el siguiente método
estático:
Runtime rt = Runtime.getRuntime();
En J2SE podemos utilizar esta clase para ejecutar comandos del sistema con
exec. En CLDC no disponemos de esta característica. Lo que
si podremos hacer con este objeto es obtener la memoria del sistema, y la memoria
libre.
Math
La clase Math nos será de gran utilidad cuando necesitemos
realizar operaciones matemáticas. Esta clase no necesita ser instanciada,
ya que todos sus métodos son estáticos. En CLDC 1.0, al no contar
con soporte para números reales, esta clase contendrá muy pocos
métodos, sólo tendrá aquellas operaciones que trabajan
con números enteros, como las operaciones de valor absoluto, máximo
y mínimo.
Random
La clase Random nos permitirá generar números aleatorios.
En CLDC 1.0 sólo nos permitirá generar números enteros
de forma aleatoria, ya que no tenemos soporte para reales.
Fechas y horas
Si miramos dentro del paquete java.util, podremos encontrar una
serie de clases que nos podrán resultar útiles para determinadas
aplicaciones.
Entre ellas tenemos la clase Calendar, que junto a Date
nos servirá cuando trabajemos con fechas y horas. La clase Date
representará un determinado instante de tiempo, en tiempo absoluto. Esta
clase trabaja con el tiempo medido en milisegundos desde el desde el 1 de enero
de 1970 a las 0:00, por lo que será difícil trabajar con esta
información directamente.
Podremos utilizar la clase Calendar para obtener un determinado
instante de tiempo encapsulado en un objeto Date, proporcionando
información de alto nivel como el año, mes, día, hora,
minuto y segundo.
Con TimeZone podemos representar una determinada zona horaria,
con lo que podremos utilizarla junto a las clases anteriores para obtener diferencias
horarias.
Temporizadores
Los temporizadores nos permitirán planificar tareas para ser ejecutadas
por un hilo en segundo plano. Para trabajar con temporizadores tenemos las clases
Timer y TimerTask.
Lo primero que deberemos hacer es crear las tareas que queramos planificar.
Para crear una tarea crearemos una clase que herede de TimerTask,
y que defina un método run donde incluiremos el código
que implemente la tarea.
public class MiTarea extends TimerTask {
public void run() {
// Código de la tarea
}
}
Una vez definida la tarea, utilizaremos un objeto Timer para planificarla.
Para ello deberemos establecer el tiempo de comienzo de dicha tarea, cosa que
puede hacerse de dos formas diferentes:
Tenemos diferentes formas de planificación de tareas, según el número de veces y la periodicidad con la que se ejecutan:
Deberemos como primer paso crear el temporizador y la tarea que vamos a planificar:
Timer t = new Timer(); TimerTask tarea = new MiTarea();
Ahora podemos planificarla para comenzar con un retardo, o bien a una determinada fecha y hora. Si vamos a hacerlo por retardo, utilizaremos uno de los siguientes métodos, según la periodicidad:
t.schedule(tarea, retardo); // Una vez t.schedule(tarea, retardo, periodo); // Retardo fijo t.scheduleAtFixedRate(tarea, retardo, periodo); // Frecuencia constante
Si queremos comenzar a una determinada fecha y hora, deberemos utilizar un
objeto Date para especificar este tiempo de comienzo:
Calendar calendario = Calendar.getInstance(); calendario.set(Calendar.HOUR_OF_DAY, 8); calendario.set(Calendar.MINUTE, 0); calendario.set(Calendar.SECOND, 0); calendario.set(Calendar.MONTH, Calendar.SEPTEMBER); calendario.set(Calendar.DAY_OF_MONTH, 22); Date fecha = calendario.getTime();
Una vez obtenido este objeto con la fecha a la que queremos comenzar la tarea (en nuestro ejemplo el día 22 de septiembre a las 8:00), podemos planificarla con el temporizador igual que en el caso anterior:
t.schedule(tarea, retardo); // Una vez t.schedule(tarea, retardo, periodo); // Retardo fijo t.scheduleAtFixedRate(tarea, retardo, periodo); // Frecuencia constante
Los temporizadores nos serán útiles en las aplicaciones móviles para realizar aplicaciones como por ejemplo agendas o alarmas. La planificación por retardo nos permitirá mostrar ventanas de transición en nuestras aplicaciones durante un número determinado de segundos.
Si queremos que un temporizador no vuelva a ejecutar la tarea planificada, utilizaremos su método cancel para cancelarlo.
t.cancel();
Una vez cancelado el temporizador, no podrá volverse a poner en marcha de nuevo. Si queremos volver a planificar la tarea deberemos crear un temporizador nuevo.
Los programas muy a menudo necesitan enviar datos a un determinado destino, o bien leerlos de una determinada fuente externa, como por ejemplo puede ser un fichero para almacenar datos de forma permanente, o bien enviar datos a través de la red, a memoria, o a otros programas. Esta entrada/salida de datos en Java la realizaremos por medio de flujos (streams) de datos, a través de los cuales un programa podrá recibir o enviar datos en serie.
En las aplicaciones CLDC, normalmente utilizaremos flujos para enviar o recibir datos a través de la red, o para leer o escribir datos en algún buffer de memoria.
Existen varios objetos que hacen de flujos de datos, y que se distinguen por la finalidad del flujo de datos y por el tipo de datos que viajen a través de ellos. Según el tipo de datos que transporten podemos distinguir:
Dentro de cada uno de estos grupos tenemos varios pares de objetos, de los cuales uno nos servirá para leer del flujo y el otro para escribir en él. Cada par de objetos será utilizado para comunicarse con distintos elementos (memoria, red, etc). Estas clases, según sean de entrada o salida y según sean de caracteres o de bytes llevarán distintos sufijos, según se muestra en la siguiente tabla:
| Flujo de entrada / lector | Flujo de salida / escritor | |
| Caractéres | _Reader |
_Writer |
| Bytes | _InputStream |
_OutputStream |
Además podemos distinguir los flujos de datos según su propósito, pudiendo ser:
Data) que permiten escribir distintos tipos de datos
(numéricos, booleanos, bytes, caracteres), y flujos
preparados para la impresión de elementos (con prefijo Print)
que ofrecen métodos para imprimir distintos tipos de datos en forma
de cadena de texto.Un tipo de filtros de procesamiento a destacar son aquellos que nos permiten
convertir un flujo de bytes a flujo de caracteres. Estos objetos son
InputStreamReader y OutputStreamWriter. Como podemos
ver en su sufijo, son flujos de caracteres, pero se construyen a partir de flujos
de bytes, permitiendo de esta manera acceder a nuestro flujo de bytes
como si fuese un flujo de caracteres.
Para cada uno de los tipos básicos de flujo que hemos visto existe una superclase, de la que heredaran todos sus subtipos, y que contienen una serie de métodos que serán comunes a todos ellos. Entre estos métodos encontramos los métodos básicos para leer o escribir caracteres o bytes en el flujo a bajo nivel. En la siguiente tabla se muestran los métodos más importantes de cada objeto:
InputStream |
read(), reset(), available(), close() |
OutputStream |
write(int b), flush(), close() |
Reader |
read(), reset(), close() |
Writer |
write(int c), flush(), close() |
En CLDC no encontramos flujos para acceder directamente a ficheros, ya que no podemos contar con poder acceder al sistema de ficheros de los dispositivos móviles, esta característica será opcional. Tampoco tenemos disponible ningún tokenizer, por lo que la lectura y escritura deberá hacerse a bajo nivel como acabamos de ver, e implementar nuestro propio analizador léxico en caso necesario.
Serialización de objetos
Otra característica que no está disponible en CLDC es la serialización automática de objetos, por lo que no podremos enviar directamente objetos a través de los flujos de datos. No existe ninguna forma de serializar cualquier objeto arbitrario automáticamente en CLDC, ya que no soporta reflection.
Sin embargo, podemos hacerlo de una forma más sencilla, y es haciendo que cada objeto particular proporcione métodos para serializarse y deserializarse. Estos métodos los deberemos escribir nosotros, adaptándolos a las características de los objetos.
Por ejemplo, supongamos que tenemos una clase Punto2D como la
siguiente:
public class Punto2D {
int x;
int y;
String etiqueta;
...
}
Los datos que contiene cada objeto de esta clase son las coordenadas (x,y) del punto y una etiqueta para identificar este punto. Si queremos serializar un objeto de esta clase esta será la información que deberemos codificar en forma de serie de bytes.
Podemos crear dos métodos manualmente para codificar y descodificar esta información en forma de array de bytes, como se muestra a continuación:
public class Punto2D {
int x;
int y;
String etiqueta;
...
public void serialize(OutputStream out) throws IOException {
DataOutputStream dos = new DataOutputStream( out );
dos.writeInt(x);
dos.writeInt(y);
dos.writeUTF(etiqueta);
dos.flush();
}
public static Punto2D deserialize(InputStream in)
throws IOException {
DataInputStream dis = new DataInputStream( in );
Punto2D p = new Punto2D();
p.x = dis.readInt();
p.y = dis.readInt();
p.etiqueta = dis.readUTF();
return p;
}
}
Hemos visto como los flujos de procesamiento DataOutputStream
y DataInputStream nos facilitan la codificación de distintos
tipos de datos para ser enviados a través de un flujo de datos.
Acceso a los recursos
Hemos visto que no podemos acceder al sistema de ficheros directamente como hacíamos en J2SE. Sin embargo, con las aplicaciones MIDP podemos incluir una serie de recursos a los que deberemos poder acceder. Estos recursos son ficheros incluidos en el fichero JAR de la aplicación, como por ejemplo sonidos, imágenes o ficheros de datos.
Para acceder a estos recursos deberemos abrir un flujo de entrada que se encargue
de leer su contenido. Para ello utilizaremos el método getResourceAsStream
de la clase Class:
InputStream in = getClass().getResourceAsStream("datos.txt");
De esta forma podremos utilizar el flujo de entrada obtenido para leer el contenido del fichero que hayamos indicado. Este fichero deberá estar contenido en el JAR de la aplicación.
Salida y salida de error estándar
Al igual que en C, en Java también existen los conceptos de entrada, salida, y salida de error estándar. En J2SE la entrada estándar normalmente se refiere a lo que el usuario escribe en la consola, aunque el sistema operativo puede hacer que se tome de otra fuente. De la misma forma la salida y la salida de error estándar lo que hacen normalmente es mostrar los mensajes y los errores del programa respectivamente en la consola, aunque el sistema operativo también podrá redirigirlas a otro destino.
En los MIDs no tenemos consola, por lo que los mensajes que imprimamos por la salida estándar normalmente serán ignorados. Esta salida estará dirigida a un dispositivo null en los teléfonos móviles. Sin embargo, imprimir por la salida estándar puede resultarnos útil mientras estemos probando la aplicaciones en emuladores, ya que al ejecutarse en el ordenador estos emuladores, estos mensajes si que se mostrarán por la consola, por lo que podremos imprimir en ellos información que nos sirva para depurar las aplicaciones.
En MIDP no existe la entrada estándar. La salida y salida de error estándar
se tratan de la misma forma que cualquier otro flujo de datos, estando estos
dos elementos encapsulados en dos objetos de flujo de datos que se encuentran
como propiedades estáticas de la clase System:
| Tipo | Objeto | |
| Salida estándar | PrintStream |
System.out |
| Salida de error estándar | PrintStream |
System.err |
Se utilizan objetos PrintWriter que facilitan la impresión de
texto ofreciendo a parte del método común de bajo nivel write(int b)
para escribir bytes, dos métodos más: print(s) y println(s).
Estas funciones nos permitirán escribir cualquier cadena, tipo básico, o bien
cualquier objeto que defina el método toString() que devuelva una
representación del objeto en forma de cadena. La única diferencia entre los
dos métodos es que el segundo añade automáticamente un salto de línea al final
del texto impreso, mientras que en el primero deberemos especificar explícitamente
este salto.
Para escribir texto en la consola normalmente utilizaremos:
System.out.println("Hola mundo");
En el caso de la impresión de errores por la salida de error de estándar, deberemos utilizar:
System.err.println("Error: Se ha producido un error");
Además de las diferencias que hemos visto en los puntos anteriores, tenemos APIs que han desaparecido en su totalidad, o prácticamente en su totalidad.
Reflection
En CLDC no está presente la API de reflection. Sólo
está presente la clase Class con la que podremos cargar
clases dinámicamente y comprobar la clase a la que pertenece un objeto
en tiempo de ejecución. Tenemos además en esta clase el método
getResourceAsStream que hemos visto anteriormente, que nos servirá
para acceder a los recursos dentro del JAR de la aplicación.
Red
La API para el acceso a la red de J2SE es demasiado compleja para los MIDs.
Por esta razón se ha sustituido por una nueva API totalmente distinta,
adaptada a las necesidades de conectividad de estos dispositivos. Desaparece
la API java.net, para acceder a la red ahora deberemos utilizar
la API javax.microedition.io incluida en CLDC que veremos en detalle
en el próximo tema.
AWT/Swing
Las librerías para la creación de interfaces gráficas,
AWT y Swing, desaparecen totalmente ya que estas interfaces no son adecuadas
para las pantallas de los MIDs. Para crear la interfaz gráfica de las
aplicaciones para móviles tendremos la API javax.microedition.lcdui
perteneciente a MIDP.