Hasta ahora hemos visto que cuando queremos obtener información primero debemos abrir la aplicación cliente que nos da acceso a esa información. Para recibir algo antes tenemos que solicitarlo desde nuestra aplicación, esto es lo que se conoce como una conexión pull, en la que el cliente debe "tirar" de los datos para obtenerlos.
Para determinadas aplicaciones puede ser interesante poder recibir datos sin tener que solicitarlos. Por ejemplo pensemos en una aplicación de foro, en el que varios usuarios pueden publicar mensajes. Nosotros querremos visualizar en nuestro cliente la lista de mensajes publicados en el servidor, pero no sabemos cuando llega un mensaje al servidor, ya que puede haberlo enviado cualquier otro cliente, sólo el servidor sabe cuando llegan nuevos mensajes.
Cuando el usuario abra la aplicación del foro se descargarán todos los mensajes publicados y se mostrarán. Esto sigue un modelo pull, en el que el usuario tiene que abrir la aplicación para obtener los datos deseados, debe "tirar" de los datos.
Pero imaginemos que queremos implementar una función de avisos en el foro, con la cual un usuario puede programar un aviso, de forma que cuando alguien publique una contestación a un tema que sea de su interés, el usuario reciba una notificación. De esta forma se evita tener que estar entrando en la aplicación periódicamente para ver si alguien ha contestado. Esto es un modelo push, en el que es la aplicación la que "empuja" los datos hacia nosotros en el momento en el que llegan.
Para implementar este comportamiento podríamos utilizar una técnica conocida como polling, que consiste en interrogar al servidor cada cierto periodo de tiempo para comprobar si han llegado mensajes nuevos, y en tal caso recibirlos y mostrarlos al usuario. Esto nos obligará a estar continuamente realizando peticiones al servidor, aunque no se haya recibido ningún mensaje, con lo que se estará produciendo un tráfico innecesario en la red. Además deberemos tener la aplicación continuamente en funcionamiento, aunque sea en segundo plano, para que haga las comprobaciones.
Con un modelo de tipo push podremos solucionar este problema, ya que en este caso el servidor podrá enviarnos información sin tener que pedirla nosotros previamente. De esta forma cuando el servidor haya recibido nuevos mensajes nos los enviará mediante push, sin tener que estar interrogándolo nosotros continuamente.
Es decir, push es un mecanismo que nos va a permitir recibir información de forma asíncrona, sin tenerla que solicitar nosotros previamente, y evitando el elevado consumo de recursos que producen las técnicas de polling.
En MIDP 2.0 aparece el registro push, que nos permitirá utilizar este mecanismo de recepción de información de forma asíncrona en nuestro dispositivo.
El registro push nos permitirá que nuestras aplicaciones sean activadas automáticamente mediante push. Es decir, no hará falta que nosotros abramos la aplicación manualmente para que esta pueda realizar alguna función, sino que se podrá activar automáticamente cuando suceda algún evento externo.
Por ejemplo, una utilidad bastante clara de este mecanismo es la programación de alarmas. Imaginemos una agenda que deba hacer sonar una alarma cuando llegue la hora de una reunión. En MIDP 1.0 una aplicación sólo podrá programar una alarma si abrimos manualmente esa aplicación, y deberemos mantener esta aplicación abierta en segundo plano permanentemente, ya que si la cerrásemos también se cerraría la alarma programada. Esto hace que en MIDP 1.0 este tipo de aplicaciones sea poco útiles, ya que si se nos olvida abrir la aplicación cuando encendamos el móvil no sonará ninguna de las alarmas programadas.
Sin embargo, en MIDP 2.0 con el registro push podremos hacer que la aplicación se abra automáticamente cuando llegue la hora de la alarma, es decir, la aplicación se estará activando automáticamente mediante push. En este caso el evento externo que activa la aplicación será un temporizador.
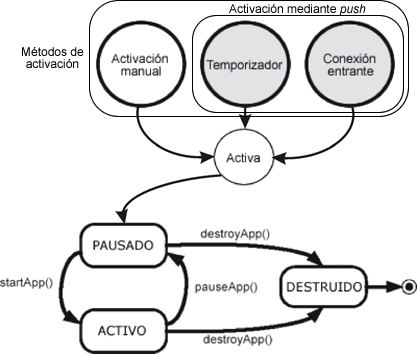
La activación mediante push puede suceder por dos tipos de eventos:
Figura 5. Métodos de activación de MIDlets
Deberemos tener en cuenta que el registro push sólo estará pendiente de estos eventos externos mientras nuestra aplicación esté cerrada. Cuando ejecutemos la aplicación, será responsabilidad suya escuchar las conexiones entrantes y registrar los temporizadores adecuados para que se disparen las alarmas.
Es decir, que la responsabilidad de la escucha y la gestión de los eventos push será compartida entre el MIDlet y el AMS:
La facilidad que nos proporciona el registro push es esta capacidad de ejecutar la aplicación automáticamente cuando se produzca un determinado evento externo, pero mientras nuestra aplicación se esté ejecutando este registro no realizará ninguna función.
A partir de WTK 2.0 se puede utilizar la activación push en los emuladores. Pero para disponer de esta funcionalidad deberemos cargar la aplicación utilizando provisionamiento OTA, instalando de esta forma la aplicación utilizando el AMS del emulador.
Vamos a ver cómo podemos registrar un temporizador push, para
que la aplicación se ejecute automáticamente a una determinada
hora. Para hacer esto deberemos utilizar la API de PushRegistry,
que nos permitirá registrar este tipo de eventos en el registro push.
Podremos registrar una alarma push con el siguiente método:
long t = PushRegistry.registerAlarm(String midletClassName, long hora);
Deberemos proporcionar como parámetros el nombre de la clase del MIDlet que queremos que se ejecute, y el tiempo del sistema en milisegundos del instante en el que queremos que se produzca la alarma.
Hemos de tener en cuenta que sólo podemos registrar una alarma por MIDlet, de forma que si hubiésemos registrado otra alarma previamente, al invocar este método de sobrescribirá.
Si hubiese una alarma registrada previamente, la llamada a esta función
nos devolverá como valor de tiempo t el instante en el que
estaba programada la alarma previa que ha sido sobrescrita. En caso contrario,
nos devolverá 0.
Si nuestra aplicación tuviese que programar varias alarmas, lo que deberíamos hacer es registrar mediante push la alarma que tenga la fecha más temprana, y una vez se haya producido esta alarma, se registrará la siguiente, y así consecutivamente.
Si queremos programar una alarma para que se produzca en una determinada fecha,
independientemente de la fecha actual, simplemente deberemos proporcionar al
método registerAlarm el tiempo del sistema en milisegundos
de la hora en la que queremos que se produzca.
Para hacer esto simplemente deberemos obtener un objeto Date que
represente dicha hora. Podemos o bien solicitar que el usuario introduzca la
fecha manualmente en un campo de fecha, y leer de ese campo el objeto Date
con la fecha introducida, o bien generar desde nuestra aplicaciones una determinada
fecha utilizando un objeto Calendar.
Una vez tengamos el objeto Date correspondiente a esta fecha,
obtendremos de él el tiempo en milisegundos de dicha fecha para proporcionárselo
a la función registerAlarm:
Date fecha = obtenerFecha(); long t = PushRegistry.registerAlarm(midlet.getClass().getName(), fecha.getTime());
Es posible que no queramos dar una fecha absoluta a la alarma, sino que queramos establecer una alarma que suene pasado cierto tiempo desde el instante actual. Por ejemplo, podemos querer poner una alarma para que suene dentro de 5 minutos.
Para hacer esto deberemos establecer la fecha de forma relativa a la fecha
actual. Primero obtendremos la fecha actual mediante un objeto Date,
y a esta fecha podremos sumarle el número de milisegundos del intervalo
de tiempo que queremos que tarde en sonar la alarma:
Date ahora = new Date(); // Obtiene la fecha actual
long t = PushRegistry.registerAlarm(midlet.getClass().getName(),
ahora.getTime() + intervalo);
Cuando el MIDlet esté en ejecución, los temporizadores registrados mediante push no tendrán efecto, estos temporizadores sólo servirán para activar la aplicación cuando esté cerrada.
Por lo tanto, normalmente durante la ejecución de la aplicación
crearemos temporizadores utilizando la clase Timer de Java. Como
estos temporizadores serán hilos de la aplicación, cuando ésta
se cierre los temporizadores también se anularán. Entonces será
este el momento en el que deberemos registrar el temporizador push.
El lugar adecuado para registrar los temporizadores push será
el método destroyApp del MIDlet. De esta forma, si al destruirse
la aplicación todavía tuviésemos algún temporizador
pendiente, los registraremos mediante push para que siga siendo efectivo.
Cuando el MIDlet se active vía push, debido a un temporizador, simplemente se pondrá en marcha la aplicación como si la hubiésemos abierto manualmente, y no tendrá constancia en ningún momento de que se ha abierto debido a un temporizador.
Si queremos que cuando se abra automáticamente se ejecute la alarma, deberemos implementar este comportamiento manualmente. Para hacer esto deberemos registrar las alarmas pendientes utilizando RMS.
Cuando queramos programar una alarma, los datos de esta alarma se registrarán
de forma persistente utilizando RMS, y se programará un Timer
para ella.
Si salimos de la aplicación, en el método destroyApp
se buscará la siguiente alarma pendiente, si hay alguna, y la registrará
mediante push.
Cuando la aplicación se active la próxima vez, podrá leer
las alarmas pendientes en RMS y programar un Timer para la siguiente.
De esta forma, si la aplicación se hubiese abierto de forma manual y
no correspondiese activar ninguna alarma, como en RMS no hay ninguna alarma
programada para este momento no sucederá nada. Si por el contrario, se
hubiese abierto debido al temporizador push, como tendremos en RMS una alarma
programada justo para el momento actual, se activará la alarma. Así,
aunque la aplicación no sepa cual ha sido la forma de activarse, mediante
la información almacenada en RMS podremos saber cuándo debemos
disparar las alarmas y cuando no.
Podemos hacer que las aplicaciones se activen mediante conexiones de red entrantes. Utilizando protocolo HTTP no tenemos este tipo de conexiones, ya que éste es un protocolo síncrono en el que debemos realizar una petición para obtener una respuesta.
Sin embargo, en MIDP 2.0 se definen otros tipos de conexiones a bajo nivel que si que soportan conexiones entrantes. Estas son las conexiones de sockets y datagramas. Podremos hacer que el dispositivo escuche en un determinado puerto conexiones entrantes mediante sockets o datagramas.
El problema de estos tipos de conexiones es que en la mayoría de los casos los operadores de telefonía móvil actuales utilizan IPs dinámicas, por lo que cada vez que se establezca una nueva conexión (por ejemplo mediante GPRS) se obtendrá una IP distinta. Esto complica la tarea de registrar nuestro móvil para recibir avisos, ya que si la IP cambia frecuentemente no se sabrá a qué dirección se debe enviar la información.
Otro tipo de conexión que tenemos disponible en un gran número de dispositivos y que nos resultará más útil es la conexión de mensajes que aporta la API WMA. Los mensajes de texto se envían a un número de teléfono que sabemos que no va a cambiar. De esta manera podremos tener identificado claramente el dispositivo en el cual queremos recibir notificaciones.
Tenemos dos formas de registrar conexiones push entrantes:
PushRegistry
para registrar las conexiones en tiempo de ejecución, de la misma forma
en la que se registran los temporizadores.Podremos utilizar registro estático cuando las direcciones de nuestras conexiones entrantes sean estáticas. Este será el caso de las conexiones de mensajes (SMS) en cualquier dispositivo, o de las conexiones de sockets y datagramas en aquellos dispositivos que tengan asignada una IP estática y su puerto se configure también de forma estática.
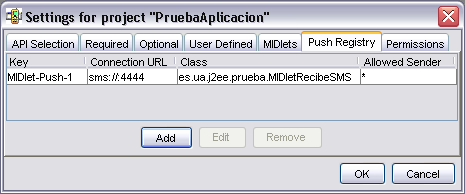
Para registrar una conexión push entrante añadiremos un atributo como el siguiente en el fichero JAD:
MIDlet-Push-<n>: <URL>, <NombreClaseMIDlet>, <RemitentesPermitidos>
Debemos especificar para cada conexión push que queramos permitir
la URL de la conexión entrante y el MIDlet que se ejecutará cuando
recibamos datos. Además como tercer elemento podemos indicar los remitentes
a los que les permitimos enviarnos datos. Con * indicamos que aceptamos
datos de cualquier remitente.
Estas conexiones se registrarán en el momento en que se instale la aplicación, y se eliminarán cuando se desinstale.
Este tipo de registro no es posible cuando tengamos asignación dinámica de IPs, ya que en tiempo de despliegue no podremos conocer cual será la IP que tenga el dispositivo cuando se utilice la aplicación. En este caso deberemos utilizar registro dinámico, como veremos más adelante.
Para configurar conexiones entrantes de sockets, datagramas y mensajes podremos utilizar URLs de los siguientes tipos:
socket://:<puerto> datagram://:<puerto>
sms://:<puerto>
Al utilizar registro estático siempre deberemos indicar explícitamente el puerto, ya que si dejamos que el puerto se asigne dinámicamente no sabremos a qué puerto del móvil hay que conectarse para activar la aplicación.
Por ejemplo, podemos registrar una conexión de mensajes entrantes de la siguiente forma:
MIDlet-Push-1: sms://:4444, es.ua.j2ee.sms.MIDletRecibirSMS, *
De esta forma se escuchará la llegada de SMSs en el puerto 4444, y en
el momento que llegue uno se ejecutará el MIDlet MIDletRecibirSMS,
permitiendo que lleguen desde cualquier remitente.
Cuando utilicemos registro dinámico podremos configurar, además de las conexiones anteriores, las conexiones de sockets y datagramas para las que se asigne el puerto de forma dinámica:
socket:// datagram://
Utilizaremos este tipo de registro cuando estemos utilizando direcciones dinámicas, o bien cuando utilizando direcciones estáticas queramos registrar la conexión sólo si se cumplen ciertas condiciones.
En este caso el registro lo realizaremos en tiempo de ejecución, utilizando
la API de PushRegistry. Podemos registrar una conexión entrante
dinámicamente de la siguiente forma:
PushRegistry.registerConnection(url,
nombreClaseMIDlet, remitentesPermitidos);
Si estamos utilizando una conexión entrante asignada dinámicamente, encontramos el problema de que el sistema externo no sabrá a qué dirección debe enviar la información para contactar con nuestra aplicación. Para solucionar este problema deberemos comunicar a este sistema externo la dirección en la que estamos escuchando. Esto podemos hacerlo de la siguiente forma:
// Creamos socket servidor asignando el puerto dinámicamente
ServerSocketConnection ssc = (ServerSocketConnection)Connector.open("socket://");
// Obtenemos el puerto que ha asignado el sistema
String url = "socket://:" + ssc.getLocalPort();
// Registramos en push una conexion entrante con este mismo puerto
PushRegistry.registerConnection(url, midletClassName, filter);
// Obtenemos la URL completa de nuestra aplicación
url = "socket://" + ssc.getLocalAddress() + ":" + ssc.getLocalPort();
// Publicamos la URL en el sistema externo
publicarURL(url);
De esta forma cada vez que el sistema asigne un nuevo puerto a nuestra aplicación deberemos publicar la nueva URL en el sistema externo.
Hemos visto que publicando la dirección en el sistema externo podemos utilizar direcciones en las que el puerto de asigna de forma dinámica por el sistema. Sin embargo, el caso en el que nuestro operador de telefonía asigne al dispositivo la IP de forma dinámica será más complicado, ya que cualquier pérdida de la conexión hará que la IP cambie y el sistema externo será incapaz de comunicarse con nuestra aplicación.
En este caso los cambios de dirección pueden ser muy frecuentes, y si la aplicación Java está cerrada no tendremos constancia del momento en el que esto ocurra, por lo que estos tipos de conexión push no serán de utilidad. En ese caso la solución será utilizar conexiones de mensajes, para las que si que tenemos una dirección (número de teléfono) asignada de forma estática.
Las conexiones entrantes push que registremos de forma dinámica podrán ser eliminadas. Para eliminar una conexión utilizaremos el siguiente método:
try {
boolean estado = PushRegistry.unregisterConnection(url);
} catch(SecurityException e) {
// Error de seguridad
}
El método unregisterConnection nos devolverá true
si ha podido eliminar la conexión push correctamente, y false
en caso contrario.
Cuando la aplicación haya sido activada mediante una conexión entrante push, a diferencia de la activación mediante temporizador, si que tendremos constancia de la forma en la que se ha activado.
Para esto utilizaremos el método listConnections, que nos
devuelve la lista de conexiones push registradas para el MIDlet. Si a este método
le pasamos true como parámetro, nos devolverá sólo
aquellas conexiones en las que tengamos datos disponibles para ser leidos.
De esta forma, si al ejecutarse la aplicación existe alguna conexión push con datos disponibles sabremos que la aplicación se ha activado mediante push debido a la recepción de datos en dichas conexiones.
public boolean isPushActivated() {
String [] conexiones = PushRegistry.listConnections(true);
if (conexiones != null && conexiones.length > 0) {
for (int i=0; i < conexiones.length; i++) {
leerDatos(conexiones[i]);
}
return true ;
} else {
return false;
}
}
Cuando hayamos recibido datos en una de estas conexiones será responsabilidad de nuestro MIDlet abrir esta conexión y leer los datos.
Hemos de tener en cuenta que en conexiones como los sockets el AMS no creará ningún buffer con los datos, sino que será el MIDlet activado el que los lea directamente de la red. Por lo tanto, deberemos leerlos lo más rápidamente posible, ya que si demorásemos la lectura de datos se podría producir un timeout.
Vamos a estudiar la seguridad de las aplicaciones MIDP. Nos referiremos a seguridad en cuanto a que las aplicaciones que se instale el usuario en el móvil no puedan realizar actividades dañinas para él. Otros tipos de seguridad dependientes de la aplicación, como son la autentificación y la confidencialidad de la información transmitida por la red los estudiaremos en el tema de aplicaciones corporativas.
El usuario navegando por la red puede encontrar aplicaciones MIDP que para utilizarlas deberán ser instaladas de forma local en su móvil. Si permitiésemos que estas aplicaciones, una vez instaladas, pudiesen realizar cualquier acción, sería bastante peligroso utilizar este tipo de aplicaciones. El usuario debería estar muy seguro que la aplicación que se instala es de su confianza, porque de no serlo la aplicación podría realizar tareas como por ejemplo:
Por lo tanto, es importante garantizar que las aplicaciones MIDP son seguras y no pueden realizar ninguna acción dañina, para que de esta forma los usuarios puedan confiar en ellas y descargárselas sin ningún temor. A continuación veremos cómo se garantiza esta seguridad en las aplicaciones MIDP.
La seguridad de las aplicaciones MIDP se debe a que estás aplicaciones se debe a que éstas se ejecutan en un entorno restringido y controlado. Al ejecutarse sobre una máquina virtual, y no directamente sobre el dispositivo, se puede limitar el número de acciones que estas aplicaciones pueden realizar, evitando de esta forma que se realicen acciones que puedan resultar dañinas.
Las aplicaciones se ejecutan dentro de lo que se conoce como un cajón de arena (sandbox), como los que existen en los parques para que los niños jueguen de forma segura. Este cajón de arena es un entorno limitado y cerrado en el que podrá trabajar la aplicación, y en el que no se tendrá acceso a nada que pudiera resultar dañino.
En el caso de las aplicaciones MIDP, este sandbox será la suite de MIDlets. Es decir, ninguna aplicación podrá acceder a nada externo a su suite:
Como las aplicaciones MIDP no permiten acceder al sistema de ficheros del dispositivo, ni tampoco permiten utilizar su API nativa, no tendremos problemas de seguridad en este aspecto.
La única funcionalidad que podría resultar peligrosa es la capacidad que tienen estas aplicaciones de establecer conexiones de red. Una aplicación podría estar intercambiando información por la red, lo cual le costará dinero al usuario, sin que éste se diese cuenta. Sin embargo, esta es una funcionalidad imprescindible de las aplicaciones MIDP, por lo que no podemos privar a estas aplicaciones de su API de red. Por esta razón, a partir de MIDP 2.0 surge un modelo de seguridad que limitará la utilización de estas funciones a las aplicaciones que obtengan permiso para hacerlo.
En la API de MIDP 2.0 existen diferentes permisos para cada tipo de conexión que pueda realizar el dispositivo. Estos permisos son los siguientes:
javax.microedition.io.Connector.http javax.microedition.io.Connector.socket javax.microedition.io.Connector.https javax.microedition.io.Connector.ssl javax.microedition.io.Connector.datagram javax.microedition.io.Connector.serversocket javax.microedition.io.Connector.datagramreceiver javax.microedition.io.Connector.comm javax.microedition.io.PushRegistry
Cuando en nuestra aplicación necesitemos utilizar alguna conexión
de cualquiera de estos tipos, deberemos solicitar el permiso para poder hacerlo.
Solicitaremos los permisos en el fichero JAD, mediante las propiedades MIDlet-Permissions
y MIDlet-Permissions-Opt, en las que especificaremos todos los
permisos solicitados separados por comas:
MIDlet-Permissions: javax.microedition.io.Connector.http,javax.microedition.io.PushRegistry MIDlet-Permissions-Opt: javax.microedition.io.Connector.https
El atributo MIDlet-Permissions indicará aquellos permisos
que son esenciales para que nuestra aplicación pueda funcionar. Si el
dispositivo en el que se va a instalar la aplicación no pudiese conceder
estos permisos a nuestra aplicación, debido a que no confía en
ella, se producirá un error en la instalación ya que la aplicación
no funcionará sin estos permisos.
En el caso de MIDlet-Permissions-Opt, especificamos permisos que
solicitamos, pero que son opcionales. Si no se pudiesen obtener estos permisos
la aplicación podría funcionar.
En WTK podremos introducir esta información en la pestaña Permissions de la ventana Settings... de nuestra aplicación:
Desde esta ventana, pulsando sobre Add podremos añadir permisos de forma visual:
Aquí podremos seleccionar los permisos deseados entre todos los permisos proporcionados por la API que estemos utilizando.
Los permisos que se le otorguen a cada aplicación MIDP dependerán del dominio en el que se encuentre dicha aplicación. Un dominio comprende:
Podemos distinguir distintos tipos de dominios según lo restrictivos que sean:
SecurityException. SecurityException.Hemos visto tres casos de dominios extremos como ejemplo, pero podemos tener muchos más tipos de dominios distintos. Un dominio se definirá otorgando a cada operación sensible un determinado tipo de permiso. En un dominio se pueden conceder permisos de dos formas distintas:
allow): Se concede el permiso para que
la aplicación pueda realizar la correspondiente operación sin
tener que obtener la confirmación del usuario.oneshot: Se pedirá confirmación al usuario
cada vez que se vaya a realizar la operación.session: Se pedirá confirmación al usuario
sólo la primera vez que se vaya a realizar la operación
en cada sesión. Cuando se cierre la aplicación y vuelva
a abrirse, se volverá a realizar la pregunta.blanket: Se pedirá confirmación sólo
la primera vez que se vaya a realizar la operación. La aplicación
recordará la opción que tomó el usuario en las sucesivas
sesiones, hasta que sea desinstalada.Esta definición de los dominios será responsabilidad del fabricante del dispositivo, por lo que no deberemos ocuparnos de ello. Nuestras aplicaciones simplemente serán asignadas a uno de los dominios disponibles en el dispositivo que las instalemos.
Normalmente, los dispositivos reales incluyen a las aplicaciones por defecto en un dominio como el último. Es decir, cualquier aplicación que instalemos se considera que no es de confianza, y se le preguntará al usuario cada vez que la aplicación vaya a realizar una operación restringida.
Además, en el caso de los dispositivos reales, también se suele poder cambiar la configuración de este dominio por defecto en la pantalla de configuración del AMS de nuestro móvil. Por ejemplo, en el caso del Nokia 6600, podremos cambiar los permisos que se le otorgan a cada aplicación manualmente. Para cada operación restringida nos dará 4 posibilidades:
Deberemos tener cuidado de no asignarle permisos a una aplicación que no sea de nuestra confianza.
La forma en la que el dispositivo decide en qué dominio se debe incluir la aplicación no está especificada en MIDP, sin embargo se recomienda la utilización de firmas criptográficas y certificados.
De esta forma, si la aplicación instalada no lleva una firma de confianza, la aplicación se incluirá en el dominio definido por defecto de aplicaciones que no son de confianza. Si por el contrario, contiene una firma reconocida por el dispositivo, la aplicación se añadirá a un dominio de confianza correspondiente a dicha firma, que nos otorgará un determinado conjunto de permisos para los cuales no será necesaria la confirmación del usuario.
Según la firma se puede añadir la aplicación a diferentes dominios, y en cada uno de ellos se pueden conceder o denegar distintas operaciones. De esta forma, puede ocurrir que una aplicación firmada por A tenga sólo permiso para utilizar conexiones HTTP, una aplicación firmada por B tenga sólo permiso para utilizar sockets, y una firmada por C tenga permiso para utilizar cualquier tipo de conexión. Los distintos tipos de dominios definidos y la asignación de permisos a cada uno de ellos dependerá del fabricante del dispositivo.
Los emuladores incluidos en WTK definen un conjunto de 4 dominios en los que se podrán incluir las aplicaciones. Estos dominios son:
SecurityException directamente.
Podemos indicar en la configuración de WTK cual será el dominio por defecto en el que se ejecutarán las aplicaciones cuando las carguemos directamente en el emulador (sin utilizar OTA). Podemos cambiar este dominio por defecto en la ventana de preferencias (Preferences...) del WTK.
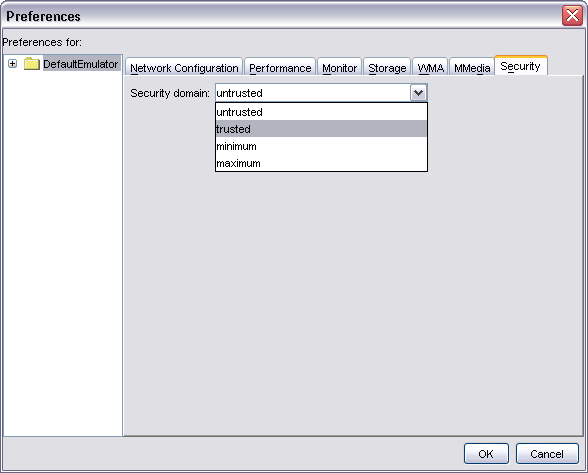
Cuando se utilice provisionamiento OTA, el emulador se comportará como un dispositivo real, asignando a la aplicación un dominio según su firma.
En la especificación de MIDP no se establece ningún método para decidir a qué dominio corresponde cada MIDlet, pero se recomienda que para tomar esta decisión se utilicen firmas y certificados.
Cada dispositivo contendrá una serie de certificados de confianza. Cada uno de estos certificados estará asociado a un determinado dominio. Es responsabilidad del fabricante decidir qué certificados se incluyen en el dispositivo y a qué dominio se asocia cada uno.
Para que a un MIDlet se le otorguen ciertos permisos, deberá estar firmado por un certificado que sea conocido por el dispositivo donde se instala. Al instalar el MIDlet en el dispositivo, si está firmado se comprobará si el dispositivo contiene el certificado que se ha utilizado para firmarlo. De ser así, se comprobará la autenticidad de la aplicación descargada mediante este certificado, y de ser correcta se instalará la aplicación en el dominio que el dispositivo tuviese asociado a dicho certificado.
Si el certificado con el que se ha firmado la aplicación no fuese conocido por el dispositivo, simplemente instalará la aplicación en el dominio de aplicaciones que no son de confianza. Normalmente en este dominio se preguntará al usuario cada vez que se va a realizar una operación restringida.
Por lo tanto, para conseguir que a nuestro MIDlet se le otorguen permisos deberemos firmarlo por un certificado que esté incluido en el dispositivo.
La especificación de MIDP 2.0 recomienda que se incluyan 3 tipos de certificados:
Si el certificado con el que hemos firmado nuestra aplicación no está entre los anteriores, o bien no hemos firmado la aplicación, ésta se instalará en el dominio de aplicaciones no fiables que existirá en cualquier dispositivo.
Para que nuestra aplicación obtenga permisos en un dispositivo móvil real deberíamos tenerla firmada por un certificado incorporado en el dispositivo en el que la instalamos. Sin embargo, cuando la probemos en emuladores podremos crear nuestros propios certificados y añadirlos al emulador, sin necesidad de obtenerlos a partir de una Autoridad Certificadora. De esta forma en el emulador las aplicaciones firmadas por nosotros podrán obtener los permisos que solicitemos.
Vamos a ver como firmar aplicaciones MIDP utilizando WTK. Para firmar una aplicación, lo primero que deberemos hacer es crear el paquete con la aplicación, ya que es necesario contar con el fichero JAR para obtener su digest. Una vez creado el paquete utilizaremos la opción Project > Sign para firmar la aplicación. Aparecerá la siguiente ventana:
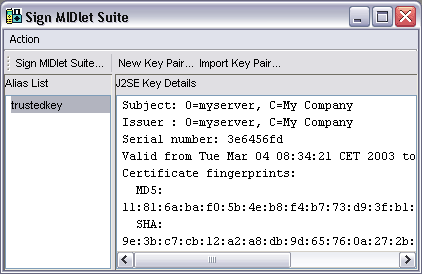
Aquí podremos utilizar alguna de las claves disponibles para firmar nuestra aplicación, o bien crear un nuevo par de claves. Pulsaremos sobre New Key Pair... para crear nuestras propias claves:
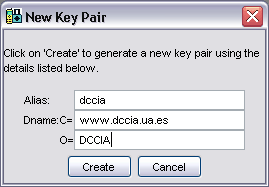
Aquí introducimos información sobre nuestra compañía, para crear un certificado correspondiente a esta compañía. Cuando pulsemos sobre Create se creará este certificado asignándole su correspondiente par de claves, y nos mostrará la siguiente ventana para indicar a qué dominio se asignarán las aplicaciones firmadas por nosotros:
De esta forma, nuestro certificado será instalado en el emulador. Cuando instalemos una aplicación firmada por nosotros en el emulador, esta aplicación se instalará en el dominio que hayamos indicado aquí. Si elegimos trusted, nuestras aplicaciones dispondrán de todos los permisos sin tener que pedir la confirmación del usuario.
El último paso que debemos realizar es firmar nuestra aplicación utilizando el certificado que acabamos de crear. Para esto simplemente seleccionaremos en la ventana Sign MIDlet Suite el certificado que queremos utilizar, y pulsaremos sobre el botón Sign MIDlet Suite...
Una vez firmada, podremos probarla en el emulador para comprobar que se le otorgan los permisos correspondientes. Para que esto sea así, deberemos probarla utilizando provisionamiento OTA, ya que si lo hacemos de otra forma la firma no se tendría en cuenta.
Recordemos que si ejecutamos la aplicación directamente se tiene en cuenta el dominio que se haya configurado por defecto para los emuladores. Cuando utilizamos OTA se comportará como un dispositivo real, utilizando los certificados de los que dispone para asignar un dominio a nuestra aplicación.
El poder establecer conexiones en red nos permitirá acceder a aplicaciones web corporativas desde el móvil. De esta forma, podremos hacer que estos dispositivos móviles se comporten como front-end de estas aplicaciones corporativas.
Desde los PCs de sobremesa normalmente accedemos a las aplicaciones corporativas utilizando un navegador web. La aplicación web genera de forma dinámica la presentación en el servidor en forma de un documento HTML que será mostrado en los navegadores de los clientes. Podemos aplicar este mismo sistema al caso de los móviles, generando nuestra aplicación web la respuesta en forma de algún tipo de documento que pueda ser interpretado y mostrado en un navegador de teléfono móvil. Por ejemplo estos documentos pueden estar en formato WML, cHTML o XHTML. Esto puede ser suficiente para acceder a algunas aplicaciones desde los móviles.
Utilizar J2ME para realizar este front-end aporta una serie de ventajas sobre el paradigma anterior, como por ejemplo las siguientes:
Normalmente será preferible utilizar HTTP a sockets o datagramas porque esto nos aportará una serie de ventajas. Por un lado, HTTP está soportado por todos los dispositivos MIDP. Al utilizar HTTP tampoco tendremos problema con firewalls intermedios, cosa que puede ocurrir si conectamos por sockets mediante un puerto que esté cerrado. Además las APIs de Java incluyen facilidades para trabajar con HTTP, por lo que será sencillo realizar la comunicación tanto en el cliente como en el servidor.
La conexión de red en los móviles normalmente tiene una alta latencia, un reducido ancho de banda y es posible que se produzcan interrupciones cuando la cobertura es baja. Deberemos tener en cuenta todos estos factores cuando diseñemos nuestra aplicación. Por esta razón deberemos minimizar la cantidad de datos que se intercambian a través de la red, y permitir que la aplicación pueda continuar trabajando correctamente sin conexión.
Para reducir el número de datos que se envían por la red, evitando que se hagan conexiones innecesarias, es conveniente realizar una validación de los datos introducidos por el usuario en el cliente.
Normalmente no podremos validarlos de la misma forma en que se validan en el servidor, ya que por ejemplo no tenemos acceso a las bases de datos de la aplicación, por lo que deberá volverse a validar por el servidor para realizar la validación completa. No obstante, es conveniente realizar esta validación en el cliente como una prevalidación, de forma que detecte siempre que sea posible los datos erróneos en el lado del cliente evitando así realizar una conexión innecesaria con el servidor.
Deberemos envíar y recibir sólo la información necesaria por la red. Podemos reducir este tráfico manteniendo en RMS una copia de los datos remotos que obtengamos (caché), para no tener que volver a solicitarlos si queremos volver a visualizarlos.
Dado que la red es lenta, las operaciones que necesiten conectarse a la red serán costosas. Estas operaciones será conveniente que sean ejecutadas por hilos en segundo plano, y nunca deberemos establecer una conexión desde un callback. Otro tipo de operaciones que normalmente son de larga duración son las consultas de datos en RMS.
Cualquier operación que sea costosa temporalmente deberá ser ejecutada de esta forma, para evitar que bloquee la aplicación.
Además siempre que sea posible deberemos mostrar una barra de progreso mientras se realiza la operación, de forma que el usuario tenga constancia de que se está haciendo algo. También será conveniente permitir al usuario que interrumpa estas largas operaciones, siempre que la interrupción pueda hacerse y no cause inconsistencias en los datos.
Un aspecto interesante en los clientes J2ME es la posibilidad de incorporar personalización. La personalización consiste en recordar los datos y las preferencias del usuario, de forma que la aplicación se adapte a estas preferencias y el usuario no tenga que introducir estos datos en cada sesión. Podremos pedir esta información de personalización la primera vez que ejecuta la aplicación y almacenar esta información utilizando RMS o bien registrarla en el servidor de forma remota. Si tuviésemos esta información por duplicado, en local y en remoto, deberemos proporcionar mecanismos para sincronizar ambos registros.
Normalmente los dispositivos móviles son personales, por lo que las aplicaciones instaladas en un móvil sólo va a utilizarlas una persona. Por este motivo puede ser conveniente guardar la información del usuario para que no tenga que volver a introducirla cada vez que utilice la aplicación. Podemos hacer que la aplicación recuerde el login y el password del usuario.
Podemos incluir en la ficha de datos del usuario información sobre sus preferencias, de forma que la aplicación se adapte a sus gustos y resulte más cómoda de manejar.
Vamos a considerar que en el servidor tenemos una aplicación J2EE. En
este caso accederemos a la aplicación corporativa a través de
un Servlet. Los servlets son componentes Java en el servidor
que encapsulan el mecanismo petición/respuesta. Es decir, podemos enviar
una petición HTTP a un servlet, y éste la analizará
y nos devolverá una respuesta.
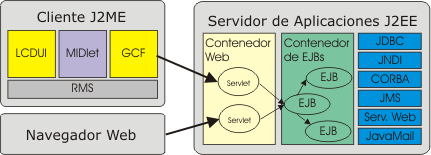
Figura 30. Integración de J2ME y J2EE
La aplicación J2ME se comunicará con un servlet. Dentro de la aplicación J2EE en el servidor este servlet utilizará EJBs para realizar las tareas necesarias. Los EJBs son componentes reutilizables que implementan la lógica de negocio de la aplicación. Estos EJBs podrán utilizar otras APIs para realizar sus funciones, como por ejemplo JMS para enviar o recibir mensajes, JDBC para acceder a bases de datos, CORBA para acceder a objetos distribuidos, o bien acceder a Servicios Web utilizando las APIs de XML.
Normalmente tendremos servlets que se encarguen de generar una respuesta para navegadores web HTML. Para las aplicaciones móviles esta respuesta no es adecuada, por lo que deberemos crear otra versión de estos servlets que devuelvan una respuesta adaptada a las necesidades de los móviles. La arquitectura de capas de J2EE nos permitirá crear servlets para distintos tipos de clientes minimizando la cantidad de código redundante, ya que la lógica de negocio está implementada en los EJBs y estos componentes pueden ser reutilizados desde los diferentes servlets.
El proceso de comunicación entre nuestra aplicación y un servlet será el siguiente:
Content-Type al tipo correcto de datos
que estemos enviando para que el mensaje sea procesado de forma correcta por
los gateways intermedios por los que pase. Si enviamos el contenido
del mensaje codificado como texto, deberemos establecer este tipo a
text/plain, mientras que si los datos se envían en binario deberemos
utilizar como tipo application/octet-stream.Content-Type y Content-Length para
asegurarnos de que el mensaje sea procesado correctamente por los gateways
intermedios igual que en el caso del envío de la petición. En
este caso como tipo podremos utilizar por ejemplo text/plain
para texto image/png para devolver una imagen PNG al cliente,
y application/octet-stream para devolver un mensaje codificado
en binario.Hemos visto que la aplicación J2ME y el servlet de la aplicación J2EE intercambian datos con una determinada codificación. En J2ME no tenemos disponibles mecanismos de alto nivel para intercambiar información con componentes remotos, como por ejemplo RMI para la invocación de métodos de objetos Java remotos, o las API de análisis de XML para intercambiar información en este formato. Por lo tanto deberemos codificar la información con formatos propios. Seremos nosotros los que decidamos qué formato y codificación deben tener estos datos.
Podemos movernos entre dos extremos: la codificación de los datos en binario y la codificación en XML.
La codificación binaria de los datos será eficiente y compacta.
Será sencillo codificar información en este formato utilizando
los objetos DataOutputStream y ByteArrayOutputStream.
Tiene el inconveniente de que tanto el cliente como el servidor deberán
conocer cómo está codificada la información dentro del
array de bytes, por lo que estos componentes estarán
altamente acoplados.
Si hemos definido una serialización para los objetos, podemos aprovechar esta serialización para enviarlos a través de la red. En este caso la serialización la hemos definido manualmente nosotros en un método del objeto, y no se hace automáticamente como en el caso de J2SE, por lo que deberemos tener cuidado de que en el objeto del cliente y en el del servidor se serialice y deserialice de la misma forma. Además, al transferir un objeto entre J2ME y J2EE deberemos asegurarnos de que este objeto utiliza solamente la parte común de la API de Java en ambas plataformas.
Por ejemplo, si definimos los métodos de serialización para la
clase Cita de la siguiente forma:
public class Cita {
Date fecha;
String asunto;
String lugar;
String contacto;
boolean alarma;
public void serialize(DataOutputStream dos) throws IOException {
dos.writeLong(fecha.getTime());
dos.writeUTF(asunto);
dos.writeUTF(lugar);
dos.writeUTF(contacto);
dos.writeBoolean(alarma);
}
public static Cita deserialize(DataInputStream dis) throws IOException {
Cita cita = new Cita();
cita.setFecha(new Date(dis.readLong()));
cita.setAsunto(dis.readUTF());
cita.setLugar(dis.readUTF());
cita.setContacto(dis.readUTF());
cita.setAlarma(dis.readBoolean());
return cita;
}
}
Podremos intercambiar objetos de este tipo mediante HTTP como se muestra a continuación:
HttpConnection con = (HttpConnection) Connector.open(URL_SERVLET);
// Envia datos al servidor DataOutputStream dos = con.openDataOutputStream(); Cita[] citasCliente = datosCliente.getCitas(); if (citasCliente == null) { dos.writeInt(0); } else { dos.writeInt(citasCliente.length); for (int i = 0; i < citasCliente.length; i++) { citasCliente[i].serialize(dos); } }
// Recibe datos del servidor DataInputStream dis = con.openDataInputStream(); int nCitasServidor = dis.readInt(); Cita[] citasServidor = new Cita[nCitasServidor]; for (int i = 0; i < nCitasServidor; i++) { citasServidor[i] = Cita.deserialize(dis); }
En el otro extremo, XML es un lenguaje complejo de analizar y la información ocupa más espacio. Como ventaja tenemos que XML es un lenguaje estándar y autodescriptivo, por lo que reduciremos el acoplamiento de cliente y servidor. Aunque en MIDP no se incluyen librerías para procesar XML, diversos fabricantes proporcionan sus propias implementaciones de las librerías de XML para J2ME. Podemos utilizar estas librerías para crear y analizar estos documentos en los clientes móviles.
Podemos encontrar incluso implementaciones de librerías de XML orientado a RPC para invocar Servicios Web SOAP directamente desde el móvil. Debemos tener cuidado al invocar Servicios Web directamente desde los móviles, ya que la construcción y el análisis de los mensajes SOAP es una tarea demasiado costosa para estos dispositivos. Para optimizar la aplicación, en lugar de invocarlos desde el mismo móvil, podemos hacer que sea la aplicación J2EE la que invoque el servicio, y que el móvil se comunique con esta aplicación a través de mensajes sencillos.
El protocolo HTTP sigue un mecanismo de petición/respuesta, no mantiene información de sesión. Es decir, si realizamos varias peticiones HTTP a un servidor desde nuestro cliente, cada una de estas peticiones será tratada independientemente por el servidor, sin identificar que se trata de un mismo usuario. Para implementar sesiones sobre protocolo HTTP tendremos que recurrir a mecanismos como la reescritura de URLs o las cookies.
Normalmente cuando accedamos a una aplicación web necesitaremos mantener una sesión para que en todas las peticiones que hagamos al servidor, éste nos identifique como un mismo usuario. De esta forma por ejemplo podremos ir añadiendo con cada petición productos a un carrito de la compra en el lado del servidor, sin perder la información sobre los productos añadidos de una petición a otra.
Para mantener las sesiones lo que se hará es obtener en el cliente un identificador de la sesión, de forma que en cada petición que se haga al servidor se envíe este identificador para que el servidor sepa a qué sesión pertenece dicha petición. Este identificador puede ser obtenido mediante cookies, o bien incluirlo como parte de las URLs utilizando la técnica de reescritura de URLs.
Los navegadores web normalmente implementan las sesiones mediante cookies. Estas cookies son información que el servidor nos envía en la respuesta y que el navegador almacena de forma local en nuestra máquina. En la primera petición el servidor enviará una cookie al cliente con el identificador de la sesión, y el navegador almacenará esta cookie de forma local en el cliente. Cuando se vaya a hacer otra petición al servidor, el navegador envía esta cookie para identificarnos ante el servidor como el mismo cliente. De esta forma el servidor podrá utilizar el valor de la cookie recibida para determinar la sesión correspondiente a dicho cliente, y de esta forma poder acceder a los datos que hubiese almacenado en peticiones anteriores dentro de la misma sesión.
Sin embargo, cuando conectamos desde un cliente J2ME estamos estableciendo una conexión con la URL del servlet desde nuestra propia aplicación, no desde un navegador que gestione automáticamente estas cookies. Por lo tanto será tarea nuestra implementar los mecanismos necesarios para mantener esta sesión desde el cliente.
Vamos a ver como implementar los mecanismos para mantenimiento de sesiones en las aplicaciones J2ME. Será más fiable utilizar reescritura de URLs, ya que algunos gateways podrían filtrar las cookies y por lo tanto este mecanismo fallaría.
Estos mecanismos de cookies y reescritura de URLs se utilizan para que los navegadores mantengan las sesiones de una forma estándar para todas las aplicaciones. Pero lo que pretendemos en última instancia es tener un identificador de la sesión en el cliente que pueda ser enviado al servidor en cada petición. Si nos conectamos desde nuestra propia aplicación podremos utilizar nuestro propio identificador y enviarlo al servidor de la forma que queramos (como cabecera, parámetro, en el post, etc). Por ejemplo, podríamos hacer que en cada petición que haga nuestra aplicación J2ME envíe nuestro login al servidor, de forma que esta información le sirva al servidor para identificarnos en cada momento.
Sin embargo, será conveniente que nuestra aplicación implemente alguno de los mecanismos estándar para el mantenimiento de sesiones, ya que así podremos aprovechar las facilidades que ofrecen los componentes del servidor para mantener las sesiones. Ahora veremos como implementar las técnicas de reescritura de URLs y cookies en nuestras aplicaciones J2ME.
Reescritura de URLs
Algunos navegadores no soportan cookies. Para mantener sesiones en este caso podemos utilizar la técnica de reescritura de URLs. Esta técnica consiste en modificar las URLs a las que accederá el cliente incluyendo en ellas el identificador de sesión como parámetro.
Para utilizar esta técnica deberemos codificar la URL en el servidor
y devolverla de alguna forma al cliente. Por ejemplo, podemos devolver esta
URL modificada como una cabecera HTTP propia. Supongamos que devolvemos esta
URL reescrita como una cabecera URL-Reescrita. Podremos obtenerla
en la aplicación cliente de la siguiente forma:
String url_con_ID = con.getHeaderField("URL-Reescrita");
En la próxima petición que hagamos al servidor deberemos utilizar la URL que hemos obtenido, en lugar de la URL básica a la que conectamos inicialmente:
HttpConnection con = (HttpConnection)Connector.open(url_con_ID);
De esta forma cuando establezcamos esta segunda conexión el servlet al que conectamos sabrá que se trata de la misma sesión y podremos acceder a la información de la sesión dentro del servidor.
En el código del servlet que atiende nuestra petición en el servidor deberemos rescribir la URL y devolvérsela al cliente como la cabecera que hemos visto anteriormente. Esto podemos hacerlo de la siguiente forma:
String url = request.getRequestURL().toString();
String url_con_ID = response.encodeURL(url);
response.setHeader("URL-Reescrita", url_con_ID);
Manejo de cookies
Los servlets utilizan las cookies para mantener la sesión siempre que detecten que el cliente soporta cookies. Para el caso de estas aplicaciones J2ME el servlet detectará que el cliente no soporta cookies, por lo que utilizará únicamente reescritura de URLs. Sin embargo, si que podremos crear cookies manualmente en el servlet para permitir mantener la información del usuario en el cliente durante el tiempo que dure la sesión o incluso durante más tiempo.
Desde las aplicaciones J2ME podremos implementar las sesiones utilizando cookies. Además con las cookies podremos mantener información del usuario de forma persistente, no únicamente durante una sola sesión. Por ejemplo, podemos utilizar RMS para almacenar las cookies con información sobre el usuario, de forma que cuando se vuelve a utilizar la aplicación en otro momento sigamos teniendo esta información. Con esto podemos por ejemplo evitar que el usuario tenga que autentificarse cada vez que entra a la aplicación.
Estas cookies consisten en una pareja <nombre, valor> y una fecha de caducidad. Con esta fecha de caducidad podemos indicar si la cookie debe mantenerse sólo durante la sesión actual, o por más tiempo.
Podemos recibir las cookies que nos envía el servidor leyendo
la cabecera set-cookie de la respuesta desde nuestra aplicación
J2ME:
String cookie = con.getHeaderField("set-cookie");
Una vez tengamos la cookie podemos guardárnosla en memoria,
o bien en RMS si queremos almacenar persistentemente esta información.
En las siguientes peticiones que hagamos al servidor deberemos enviarle esta
cookie en la cabecera cookie:
con.setRequestProperty("cookie", cookie);
Vamos a ver como crear aplicaciones seguras en cuando a la autentificación de los usuarios y a la confidencialidad de los datos que circulan por la red.
Confidencialidad
Para proteger los datos que circulan por la red, y evitar que alguien pueda interceptarlos, podemos enviarlos codificados mediante SSL.
Podemos establecer una conexión segura con el servidor mediante SSL
(Secure Sockets Layer) simplemente indicando como protocolo en la URL
de la conexión https en lugar de http.
El problema es que la mayoría de móviles con MIDP 1.0 no soportan
este tipo de protocolo. Si intentamos utilizar HTTPS desde un dispositivo que
no lo soporta, obtendremos una excepción de tipo ConnectionNotFoundException.
Además de tener que se soportada por el móvil, este tipo de conexión
deberá ser soportada por el servidor.
Autentificación
En muchas aplicaciones necesitaremos que el usuario se autentifique para que de esa forma pueda acceder a determinados datos privados alojados en el servidor, o pueda realizar determinadas acciones para las que no todos los usuarios tienen permiso.
Para autentificar a los usuarios que se conectan desde el móvil a las aplicaciones corporativas, normalmente utilizaremos seguridad a nivel de la aplicación. Es decir, enviaremos nuestros credenciales (login y password) a un servlet para que los verifique en la base de datos de usuarios que haya en el servidor.
Una vez autentificados, podremos mantener esta información de registro en la sesión del usuario, de forma que en sucesivas peticiones podamos obtener la información sin necesidad de volvernos a autentificar en cada una de ellas.
Cada petición HTTP que se haga el servidor será una transacción independiente. Todas las operaciones de la transacción se deben realizar dentro de esa conexión en el servidor, ya que las peticiones HTTP son independientes entre si y el dispositivo cliente móvil no realiza ninguna gestión de transacciones. Por lo tanto las transacciones nunca supondrán más de una petición HTTP.
En el caso en el que la inserción de unos datos en la memoria local dependa de que los datos sean aceptados por el servidor remoto, siempre realizaremos antes la petición al servidor remoto, y una vez hayamos enviados estos datos correctamente, haremos la inserción local. Esto se da por ejemplo en el caso en que queremos mantener una copia local de los datos que enviamos al servidor. Sólo insertaremos los datos en la copia local una vez hayan sido insertados en el servidor.
Cuando estemos accediendo al lado del servidor de nuestra aplicación mediante HTTP, si la petición que hemos hecho produce un error no podremos gestionar este error mediante excepciones ya que lo único que vamos a recibir es una respuesta HTTP.
Para gestionar los errores del servidor deberemos almacenarlos de alguna forma en el mensaje de respuesta HTTP.
Podemos utilizar el código de estado de la respuesta para indicar la presencia de algún error. Si necesitamos una mayor flexibilidad podemos establecer nuestra propia codificación para los errores dentro del contenido de la respuesta, y hacer que nuestro cliente sea capaz de interpretar dicha codificación.
El patrón de diseño MVC (Modelo-Vista-Controlador) suele aplicarse para diseñar las aplicaciones web J2EE. Podemos aplicar este mismo patrón a las aplicaciones cliente J2ME. En una aplicación cliente tendremos los siguientes elementos:
De esta forma con esta arquitectura estamos aislando datos, presentación y flujo de control. Es especialmente interesante el haber aislado los datos del resto de componentes. De esta forma la capa de datos podrá decidir si trabajar con datos de forma local con RMS o de forma remota a través de HTTP, sin afectar con ello al resto de la aplicación. Este diseño nos facilitará cambiar de modo remoto a modo local cuando no queramos tener que establecer una conexión de red.
Normalmente en las aplicaciones para dispositivos móviles vamos a trabajar tanto con datos locales como con datos remotos. Por lo tanto, podemos ver el modelo dividido en dos subsistemas: modelo local y modelo remoto.
Modelo local
El modelo local normalmente utilizará un adaptador RMS para acceder a los datos almacenados de forma persistente en el móvil. Por ejemplo, en nuestra aplicación de agenda para la gestión de citas podemos crear la siguiente clase para acceder a los datos locales:
public class ModeloLocal {
AdaptadorRMS rms;
public ModeloLocal() throws RecordStoreException {
rms = new AdaptadorRMS();
}
/*
* Agrega una cita indicando si esta pendiente de ser enviada al servidor
*/
public void addCita(Cita cita, boolean pendiente) throws IOException,
RecordStoreException {
int id = rms.addCita(cita);
IndiceCita indice = new IndiceCita();
indice.setId(id);
indice.setFecha(cita.getFecha());
indice.setAlarma(cita.isAlarma());
indice.setPendiente(pendiente);
rms.addIndice(indice);
}
/*
* Obtiene todas las citas
*/
public Cita[] listaCitas() throws RecordStoreException, IOException {
return rms.listaCitas();
}
/*
* Obtiene las citas correspondientes a los indices indicados
*/
public Cita[] listaCitas(IndiceCita[] indices) throws RecordStoreException,
IOException {
Cita[] citas = new Cita[indices.length];
for (int i = 0; i < indices.length; i++) {
citas[i] = rms.getCita(indices[i].getId());
}
return citas;
}
/*
* Busca las citas con alarmas pendientes
*/
public IndiceCita[] listaAlarmasPendientes() throws RecordStoreException,
IOException {
IndiceCita[] indices = rms.buscaCitas(new Date(), true);
return indices;
}
/*
* Busca las citas pendientes de ser enviadas al servidor
*/
public IndiceCita[] listaCitasPendientes() throws RecordStoreException,
IOException {
IndiceCita[] indices = rms.listaCitasPendientes();
return indices;
}
/*
* Marca las citas indicada como enviadas al servidor
*/
public void marcaEnviados(IndiceCita[] indices) throws IOException,
RecordStoreException {
for (int i = 0; i < indices.length; i++) {
indices[i].setPendiente(false);
rms.updateIndice(indices[i]);
}
}
/*
* Obtiene la configuracion local
*/
public InfoLocal getInfoLocal() throws RecordStoreException, IOException {
try {
InfoLocal info = rms.getInfoLocal();
return info;
} catch (Exception e) { }
InfoLocal info = new InfoLocal();
rms.setInfoLocal(info);
return info;
}
/*
* Modifica la configuracion local
*/
public void setInfoLocal(InfoLocal info) throws RecordStoreException,
IOException {
rms.setInfoLocal(info);
}
/*
* Libera recursos del modelo
*/
public void destroy() throws RecordStoreException {
rms.cerrar();
}
}
En esta clase definiremos métodos para acceder a todos los datos locales que nuestra aplicación necesite utilizar.
Modelo remoto
Además de la información local que almacenamos en el móvil, será importante tener acceso a los datos remotos de nuestra aplicación corporativa. Esta parte del modelo normalmente utilizará HTTP para acceder a estos datos.
Para implementar este subsistema del modelo podemos utilizar el patrón de diseño proxy. Este patrón se utiliza cuando accedemos a componentes remotos, encapsulando dentro de la clase proxy todo el mecanismo de comunicación necesario para acceder a las funcionalidades del servidor.
De esta forma, cuando utilizamos un proxy para acceder a componentes remotos, el que estos componentes se estén utilizando de forma remota es transparente para nosotros. El proxy implementa todo el mecanismo de comunicación necesario (por ejemplo HTTP), aislando al resto de la aplicación de él. Invocaremos los métodos del proxy directamente para utilizar funcionalidades de nuestro servidor como si se tratase de un acceso a un objeto local, sin preocuparnos de que realmente el proxy esté realizando una conexión remota.
Por ejemplo, en el caso de nuestra agenda, el servidor nos proporcionará la funcionalidad de sincronizar las citas almacenadas en el móvil con las notas almacenadas en el servidor, para hacer que en ambos lados se tenga el mismo conjunto de citas. Podemos encapsular esta operación en una clase proxy como la siguiente:
public class ProxyRemoto {
public ProxyRemoto() {
}
public SyncItem sincroniza(SyncItem datosCliente) throws IOException {
HttpConnection con = (HttpConnection) Connector.open(URL_SERVLET);
// Envia datos al servidor
DataOutputStream dos = con.openDataOutputStream();
Cita[] citasCliente = datosCliente.getCitas();
dos.writeLong(datosCliente.getTimeStamp());
if (citasCliente == null) {
dos.writeInt(0);
} else {
dos.writeInt(citasCliente.length);
for (int i = 0; i < citasCliente.length; i++) {
citasCliente[i].serialize(dos);
}
}
// Recibe datos del servidor
DataInputStream dis = con.openDataInputStream();
long tsServidor = dis.readLong();
int nCitasServidor = dis.readInt();
Cita[] citasServidor = new Cita[nCitasServidor];
for (int i = 0; i < nCitasServidor; i++) {
citasServidor[i] = Cita.deserialize(dis);
}
SyncItem datosServidor = new SyncItem();
datosServidor.setTimeStamp(tsServidor);
datosServidor.setCitas(citasServidor);
return datosServidor;
}
}
De esta forma desde el resto de la aplicación simplemente tendremos
que invocar el método sincroniza del proxy para
utilizar esta funcionalidad del servidor.
Patrón de diseño fachada
Hasta ahora hemos visto que tenemos dos subsistemas en el modelo. Esta división podría causar que el acceso al modelo desde nuestra aplicación fuese demasiado complejo.
Para evitar esto podemos utilizar el patrón de diseño fachada (facade). Este patrón consiste un implementar una interfaz única que integre varios subsistemas, proporcionando de esta forma una interfaz sencilla para el acceso al modelo.
Desde el resto de la aplicación accederemos al modelo siempre a través de la fachada, y ésta será quien se encargue de coordinar los subsistemas local y remoto. Estos dos subsistemas se mantendrán independientes, pero accederemos a ellos mediante una interfaz única.
Por ejemplo, para nuestra agenda podemos definir una fachada como la siguiente para el modelo:
public class FachadaModelo {
boolean online;
ModeloLocal mLocal;
ProxyRemoto mRemoto;
public FachadaModelo() throws RecordStoreException, IOException {
mLocal = new ModeloLocal();
mRemoto = new ProxyRemoto();
InfoLocal info = getConfig();
online = info.isOnline();
}
/*
* Crea una nueva cita
*/
public void nuevaCita(Cita cita) throws IOException, RecordStoreException {
mLocal.addCita(cita, true);
if (online) {
sincroniza();
}
}
/*
* Obtiene la lista de todas las citas
*/
public Cita[] listaCitas() throws RecordStoreException, IOException {
if (online) {
sincroniza();
}
return mLocal.listaCitas();
}
/*
* Obtiene la lista de citas con alarmas pendientes
*/
public Cita[] listaAlarmasPendientes() throws RecordStoreException,
IOException {
if (online) {
sincroniza();
}
IndiceCita[] indices = mLocal.listaAlarmasPendientes();
return mLocal.listaCitas(indices);
}
/*
* Obtiene la configuracion local
*/
public InfoLocal getConfig() throws RecordStoreException, IOException {
return mLocal.getInfoLocal();
}
/*
* Actualiza la configuracion local
*/
public void updateConfig(InfoLocal config) throws RecordStoreException,
IOException {
InfoLocal info = mLocal.getInfoLocal();
info.setOnline(config.isOnline());
this.online = config.isOnline();
mLocal.setInfoLocal(info);
}
/*
* Sincroniza la lista de citas con el servidor
*/
public void sincroniza() throws RecordStoreException, IOException {
// Obtiene datos del cliente
InfoLocal info = mLocal.getInfoLocal();
IndiceCita[] indices = mLocal.listaCitasPendientes();
Cita[] citas = mLocal.listaCitas(indices);
SyncItem datosCliente = new SyncItem();
datosCliente.setCitas(citas);
datosCliente.setTimeStamp(info.getTimeStamp());
// Envia y recibe
SyncItem datosServidor = mRemoto.sincroniza(datosCliente);
mLocal.marcaEnviados(indices);
// Agrega los datos recibidos del servidor
Cita[] citasServidor = datosServidor.getCitas();
if (citasServidor != null) {
for (int i = 0; i < citasServidor.length; i++) {
mLocal.addCita(citasServidor[i], false);
}
}
info.setTimeStamp(datosServidor.getTimeStamp());
mLocal.setInfoLocal(info);
}
public void destroy() throws RecordStoreException {
mLocal.destroy();
}
}
Podemos ver en este ejemplo como este modelo nos permite trabajar de forma online u offline. Según el modo de conexión, se utilizarán las funciones de uno u otro subsistema. En modo online siempre que se haga una operación se accederá al servidor para leer o almacenar las novedades que haya. En modo offline sólo se leerán o almacenarán los datos de forma local, excepto cuando solicitemos de forma explícita sincronizar los datos con el servidor.
En el caso del método sincroniza, que será el método
encargado de coordinar información local con información remota,
podemos ver que la transacción de sincronización se realiza en
una única petición HTTP. Además, los mensajes que se hayan
enviado al servidor no se marcan como enviados hasta después de haber
completado el envío (se llama a marcaEnviados después
de llamar a sincroniza).
Para la vista crearemos una clase para cada pantalla de nuestra aplicación, como hemos visto en temas anteriores. La clase correspondiente a una pantalla heredará del tipo de displayable correspondiente y encapsulará la creación de la interfaz y la respuesta a los comandos.
Por ejemplo, para la edición de datos de las citas en nuestra aplicación podemos utilizar la siguiente pantalla:
public class EditaCitaUI extends Form implements CommandListener {
ControladorUI controlador;
DateField iFecha;
TextField iAsunto;
TextField iLugar;
TextField iContacto;
ChoiceGroup iAlarma;
int itemAlarmaOn;
int itemAlarmaOff;
Command cmdAceptar;
Command cmdCancelar;
int eventoAceptar = ControladorUI.EVENTO_AGREGA_CITA;
int eventoCancelar = ControladorUI.EVENTO_MUESTRA_MENU;
Cita cita;
public EditaCitaUI(ControladorUI controlador) {
super(controlador.getString(Recursos.STR_DATOS_TITULO));
this.controlador = controlador;
iFecha = new DateField(
controlador.getString(Recursos.STR_DATOS_ITEM_FECHA),
DateField.DATE_TIME);
iAsunto = new TextField(
controlador.getString(Recursos.STR_DATOS_ITEM_ASUNTO),
"", MAX_LENGHT, TextField.ANY);
iLugar = new TextField(
controlador.getString(Recursos.STR_DATOS_ITEM_LUGAR),
"", MAX_LENGHT, TextField.ANY);
iContacto = new TextField(
controlador.getString(Recursos.STR_DATOS_ITEM_CONTACTO),
"", MAX_LENGHT, TextField.ANY);
iAlarma = new ChoiceGroup(
controlador.getString(Recursos.STR_DATOS_ITEM_ALARMA),
ChoiceGroup.EXCLUSIVE);
itemAlarmaOn = iAlarma.append(
controlador.getString(Recursos.STR_DATOS_ITEM_ALARMA_ON), null);
itemAlarmaOff = iAlarma.append(
controlador.getString(Recursos.STR_DATOS_ITEM_ALARMA_OFF), null);
this.append(iFecha);
this.append(iAsunto);
this.append(iLugar);
this.append(iContacto);
this.append(iAlarma);
cmdAceptar = new Command(
controlador.getString(Recursos.STR_CMD_ACEPTAR), Command.OK, 1);
cmdCancelar = new Command(
controlador.getString(Recursos.STR_CMD_CANCELAR), Command.CANCEL, 1);
this.addCommand(cmdAceptar);
this.addCommand(cmdCancelar);
this.setCommandListener(this);
}
private void setCita(Cita cita) {
if (cita == null) {
this.cita = new Cita();
iFecha.setDate(new Date());
iAsunto.setString(null);
iLugar.setString(null);
iContacto.setString(null);
iAlarma.setSelectedIndex(itemAlarmaOff, true);
} else {
this.cita = cita;
iFecha.setDate(cita.getFecha());
iAsunto.setString(cita.getAsunto());
iLugar.setString(cita.getLugar());
iContacto.setString(cita.getContacto());
if (cita.isAlarma()) {
iAlarma.setSelectedIndex(itemAlarmaOn, true);
} else {
iAlarma.setSelectedIndex(itemAlarmaOff, true);
}
}
}
private Cita getCita() {
if(cita==null) {
this.cita = new Cita();
}
if(iFecha.getDate()==null) {
cita.setFecha(new Date());
} else {
cita.setFecha(iFecha.getDate());
}
cita.setAsunto(iAsunto.getString());
cita.setLugar(iLugar.getString());
cita.setContacto(iContacto.getString());
cita.setAlarma(iAlarma.getSelectedIndex() == itemAlarmaOn);
return cita;
}
public void reset(Cita cita, int eventoAceptar, int eventoCancelar) {
this.setCita(cita);
this.eventoAceptar = eventoAceptar;
this.eventoCancelar = eventoCancelar;
}
public void commandAction(Command cmd, Displayable disp) {
if (cmd == cmdAceptar) {
controlador.procesaEvento(eventoAceptar, this.getCita());
} else if (cmd == cmdCancelar) {
controlador.procesaEvento(eventoCancelar, null);
}
}
}
Intentaremos llevar la mayor parte de la gestión de eventos al controlador,
para así aislar lo más posible la vista del controlador. En la
vista implementaremos la interfaz commandAction, pero el procesamiento
de los eventos lo hará el controlador mediante el método procesaEvento
que veremos a continuación.
El controlador será el encargado de controlar el flujo de la aplicación. Según las acciones realizadas, el controlador mostrará distintas pantalla y realizará diferentes operaciones en el modelo.
Por ejemplo, el controlador para nuestra agenda será el siguiente:
public class ControladorUI {
/*
* Tipos de eventos
*/
public final static int EVENTO_MUESTRA_MENU = 0;
public final static int EVENTO_MUESTRA_NUEVA_CITA = 1;
public final static int EVENTO_MUESTRA_LISTA_CITAS = 2;
public final static int EVENTO_MUESTRA_DATOS_CITA = 3;
public final static int EVENTO_MUESTRA_LISTA_ALARMAS_PENDIENTES = 4;
public final static int EVENTO_MUESTRA_DATOS_ALARMA_PENDIENTE = 5;
public final static int EVENTO_AGREGA_CITA = 6;
public final static int EVENTO_SALIR = 8;
public final static int EVENTO_SINCRONIZAR = 9;
public final static int EVENTO_MUESTRA_CONFIG =10;
public final static int EVENTO_APLICA_CONFIG = 11;
/*
* Componentes de la UI
*/
DatosCitaUI uiDatosCita;
EditaCitaUI uiEditaCita;
ListaCitasUI uiListaCitas;
EditaConfigUI uiEditaConfig;
MenuPrincipalUI uiMenuPrincipal;
BarraProgresoUI uiBarraProgreso;
/*
* Gestor de recursos
*/
Recursos recursos;
/*
* Modelo
*/
FachadaModelo modelo;
MIDletAgenda midlet;
Display display;
public ControladorUI(MIDletAgenda midlet) {
this.midlet = midlet;
display = Display.getDisplay(midlet);
init();
}
/*
* Inicializacion de los componentes de la UI
*/
public void init() {
// Crea gestor de recursos
recursos = new Recursos();
// Crea UI
uiDatosCita = new DatosCitaUI(this);
uiEditaCita = new EditaCitaUI(this);
uiListaCitas = new ListaCitasUI(this);
uiEditaConfig = new EditaConfigUI(this);
uiMenuPrincipal = new MenuPrincipalUI(this);
uiBarraProgreso = new BarraProgresoUI(this);
try {
// Crea modelo
modelo = new FachadaModelo(alarmas);
} catch (Exception e) {
e.printStackTrace();
}
}
public void destroy() throws RecordStoreException {
modelo.destroy();
}
public void showMenu() {
display.setCurrent(uiMenuPrincipal);
}
public String getString(int cod) {
return recursos.getString(cod);
}
/*
* Lanza el procesamiento de un evento
*/
public void procesaEvento(int evento, Object param) {
HiloEventos he = new HiloEventos(evento, param);
he.start();
}
/*
* Hilo para el procesamiento de eventos
*/
class HiloEventos extends Thread {
int evento;
Object param;
public HiloEventos(int evento, Object param) {
this.evento = evento;
this.param = param;
}
public void run() {
Cita cita;
Cita [] citas;
InfoLocal info;
try {
switch(evento) {
case EVENTO_MUESTRA_MENU:
showMenu();
break;
case EVENTO_MUESTRA_NUEVA_CITA:
uiEditaCita.reset(null,
ControladorUI.EVENTO_AGREGA_CITA,
ControladorUI.EVENTO_MUESTRA_MENU);
display.setCurrent(uiEditaCita);
break;
case EVENTO_AGREGA_CITA:
cita = (Cita)param;
modelo.nuevaCita(cita);
showMenu();
break;
case EVENTO_MUESTRA_LISTA_CITAS:
uiBarraProgreso.reset(
getString(Recursos.STR_PROGRESO_CARGA_LISTA),
10, 0, true);
display.setCurrent(uiBarraProgreso);
citas = modelo.listaCitas();
uiListaCitas.reset(citas,
ControladorUI.EVENTO_MUESTRA_DATOS_CITA,
ControladorUI.EVENTO_MUESTRA_MENU);
display.setCurrent(uiListaCitas);
break;
case EVENTO_MUESTRA_DATOS_CITA:
cita = (Cita)param;
uiDatosCita.reset(cita,
ControladorUI.EVENTO_MUESTRA_LISTA_CITAS);
display.setCurrent(uiDatosCita);
break;
case EVENTO_MUESTRA_LISTA_ALARMAS_PENDIENTES:
uiBarraProgreso.reset(
getString(Recursos.STR_PROGRESO_CARGA_LISTA),
10, 0, true);
display.setCurrent(uiBarraProgreso);
citas = modelo.listaAlarmasPendientes();
uiListaCitas.reset(citas,
ControladorUI.EVENTO_MUESTRA_DATOS_ALARMA_PENDIENTE,
ControladorUI.EVENTO_MUESTRA_MENU);
display.setCurrent(uiListaCitas);
break;
case EVENTO_MUESTRA_DATOS_ALARMA_PENDIENTE:
cita = (Cita)param;
uiDatosCita.reset(cita,
ControladorUI.EVENTO_MUESTRA_LISTA_ALARMAS_PENDIENTES);
display.setCurrent(uiDatosCita);
break;
case EVENTO_SINCRONIZAR:
uiBarraProgreso.reset(
getString(Recursos.STR_PROGRESO_SINCRONIZA),
10, 0, true);
display.setCurrent(uiBarraProgreso);
modelo.sincroniza();
display.setCurrent(uiMenuPrincipal);
break;
case EVENTO_MUESTRA_CONFIG:
info = modelo.getConfig();
uiEditaConfig.reset(info,
ControladorUI.EVENTO_APLICA_CONFIG,
ControladorUI.EVENTO_MUESTRA_MENU);
display.setCurrent(uiEditaConfig);
break;
case EVENTO_APLICA_CONFIG:
info = (InfoLocal)param;
modelo.updateConfig(info);
display.setCurrent(uiMenuPrincipal);
break;
case EVENTO_SALIR:
midlet.salir();
break;
}
} catch(Exception e) {
e.printStackTrace();
}
}
}
}
Vemos en este ejemplo que el controlador tiene acceso al modelo a través de la fachada, y también tiene acceso a las diferentes pantallas de la interfaz de usuario (UI). A través de estos elementos controlará la presentación de la aplicación y la lógica de negocio de la misma.
Este controlador se encargará de dar respuesta a los eventos que se
produzcan en la aplicación. Vemos que para hacer esto se utiliza un método
procesaEvento que a su vez utiliza un hilo para procesar el evento
solicitado. Esto se hace así para no bloquear el hilo de la aplicación
al realizar operaciones que normalmente serán de larga duración.
Tenemos varios tipos de eventos definidos como constantes, y para cada uno de ellos especificaremos las operaciones a realizar y los componentes de la UI que se deben mostrar. Se puede observar en el ejemplo que en las operaciones que son de más larga duración, el controlador mientras la realiza muestra en pantalla una barra de progreso.
También se puede observar que todas las cadenas de texto se encuentran
centralizadas en la clase Recursos. Todos los componentes de la
aplicación obtendrán el texto de esta clase. Esto nos facilitará
tareas como la traducción de nuestra aplicación a otros idiomas.
Para la internacionalización de la aplicación, podríamos
hacer que la clase Recursos cargase todas las cadenas de texto
de un fichero externo. De esta forma, cambiando este fichero podremos cambiar
el idioma de nuestra aplicación. Podríamos permitir que el usuario
se descargase ficheros con otros idiomas.
Hemos visto que en las aplicaciones MIDP es conveniente permitir trabajar sin conexión, trabajando con datos locales. También hemos visto como con el patrón MVC podemos dividir el modelo en dos subsistemas para permitir los dos modos de funcionamiento: con y sin conexión.
Vamos ahora a estudiar más a fondo el funcionamiento de este tipo de aplicaciones.
Podemos distinguir varios tipos de aplicaciones:
Nos centraremos en el estudio de las aplicaciones de tipo thick. Estas aplicaciones deberán trabajar de forma coordinada con el servidor, pero podremos permitir trabajar sin conexión. El permitir trabajar en este modo nos trae la ventaja de que minimiza el trafico en la red, sin embargo aumentará el coste de procesamiento, memoria y almacenamiento en el dispositivo local. Deberemos por lo tanto buscar un compromiso entre estos dos factores.
Para poder trabajar sin conexión es imprescindible replicar en nuestro dispositivo datos del servidor. Por lo tanto tendremos dos tipos de datos en el cliente:
Además, dentro de los datos replicados del servidor podemos distinguir:
El modelo de réplica de datos que utilicemos se caracterizará por los siguientes factores:
Según estos factores deberemos decidir el modelo de sincronización adecuado para nuestra aplicación.
Para facilitar la sincronización es conveniente reducir la granularidad de los datos en el almacenamiento, es decir, reducir la cantidad de datos que se almacenen juntos en el mismo registro.
Los datos de nuestra aplicación se pueden transferir de diferentes formas:
Descarga de datos del servidor
Este caso se puede resolver de forma sencilla. Las actualizaciones de los datos se pueden hacer de varias formas:
En muchas aplicaciones necesitaremos identificar qué datos no descargados todavía hay en el servidor. Por ejemplo, imaginemos nuestra aplicación de agenda. Podemos crear nuevas citas utilizando un navegador web en nuestro PC o desde otro dispositivo. Cuando ejecutemos la aplicación en nuestro móvil, para actualizar la agenda deberá descargar las nuevas citas que se hayan creado en el servidor.
Pero, ¿cómo podemos saber qué citas son nuevas? Podemos utilizar estampas de tiempo (timestamps) para etiquetar cada cita, de forma que cada nueva cita que añadamos al servidor tenga una estampa de tiempo superior a la de la anterior cita.
public void sincroniza() throws RecordStoreException, IOException {
// Obtiene datos del cliente
InfoLocal info = mLocal.getInfoLocal();
IndiceCita[] indices = mLocal.listaCitasPendientes();
Cita[] citas = mLocal.listaCitas(indices);
SyncItem datosCliente = new SyncItem();
datosCliente.setCitas(citas);
datosCliente.setTimeStamp(info.getTimeStamp());
// Envia y recibe
SyncItem datosServidor = mRemoto.sincroniza(datosCliente);
mLocal.marcaEnviados(indices);
// Agrega los datos recibidos del servidor
Cita[] citasServidor = datosServidor.getCitas();
if (citasServidor != null) {
for (int i = 0; i < citasServidor.length; i++) {
mLocal.addCita(citasServidor[i], false);
}
}
info.setTimeStamp(datosServidor.getTimeStamp());
mLocal.setInfoLocal(info);
}
En nuestro dispositivo nos guardaremos el número de la última estampa de tiempo obtenida. Cuando solicitemos los nuevos datos al servidor, le proporcionaremos esta estampa de tiempo para que nos devuelva sólo aquellas citas que sean posteriores. Junto a estas citas nos devolverá una nueva estampa de tiempo correspondiente al último dato que hayamos recibido. El cliente tendrá la responsabilidad de almacenar esta estampa de tiempo para poder utilizarla en la próxima petición.
Envío de datos no compartidos al servidor
En este caso deberemos actualizar cada cierto período en el servidor los datos que hayamos modificado en nuestro dispositivo. La actualización podemos hacer que sea automática, cada cierto período de tiempo, o manual, a petición del usuario.
Para actualizar los datos deberemos conocer qué datos han cambiado desde la última actualización. Para ello podremos añadir a los datos almacenados en RMS un atributo que nos diga si hay cambios pendientes de actualizar en dicho dato.
Si hemos creado índices para nuestros registros de RMS, podremos añadir este atributo a los índices, para facilitar de esta forma la búsqueda de estos datos.
public class IndiceCita {
int rmsID;
int id;
Date fecha;
boolean alarma;
boolean pendiente;
}
Podemos ver aquí la razón por la que preferimos una granularidad fina de los datos almacenados. Si tuviésemos almacenados muchos datos en un mismo registro, y modificamos una pequeña parte de estos datos, tendremos que marcar todo el registro como modificado, por lo que habrá que subir al servidor un mayor volumen de datos. Si estos datos hubiesen estado repartidos en varios registros, sólo hubiese hecho falta actualizar la parte que hubiese cambiado.
Envío de datos compartidos al servidor
Este caso es el más complejo. Existe una copia maestra de los datos almacenada en el servidor, y varias copias locales, conocidas como copias legales, que se descargan los usuarios a sus dispositivos.
Si varios clientes han descargado los datos en sus móviles, y modifican su copia legal, cuando actualicen los datos en la copia maestra del servidor podrían sobrescribir el trabajo de otros usuarios.
Para poder corregir estos conflictos de la mejor forma posible, deberemos tener una granularidad muy fina de los datos, de forma que los usuarios sólo modifiquen las porciones de los datos que hayan modificado. De esta forma, si nosotros hemos modificado una parte de los datos que otro usuario no ha tocado, cuando el otro usuario actualice los datos no sobrescribirá dicha parte.
Para decidir qué versión de los datos mantener en la copia maestra podemos tomar diferentes criterios:
Deberemos intentar solucionar los conflictos sin necesidad de solicitar la intervención del usuario, aunque en ciertas ocasiones la mejor solución puede ser preguntar qué copia de los datos desea que se mantenga.