Las excepciones son eventos que ocurren durante la ejecución de un programa y hacen que éste salga de su flujo normal de instrucciones. Este mecanismo permite tratar los errores de una forma elegante, ya que separa el código para el tratamiento de errores del código normal del programa. Se dice que una excepción es lanzada cuando se produce un error, y esta excepción puede ser capturada para tratar dicho error.
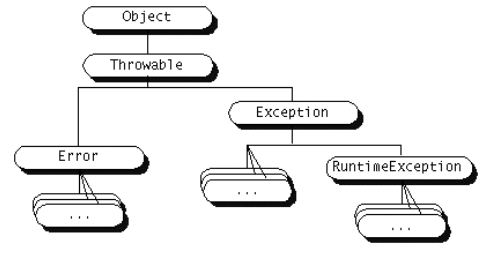
Tenemos diferentes tipos de excepciones dependiendo del tipo de error que representen. Todas ellas descienden de la clase Throwable, la cual tiene dos descendientes directos:
Dentro de Exception, cabe destacar una subclase especial de excepciones denominada RuntimeException, de la cual derivarán todas aquellas excepciones referidas a los errores que comúnmente se pueden producir dentro de cualquier fragmento de código, como por ejemplo hacer una referencia a un puntero null, o acceder fuera de los límites de un array.
Estas RuntimeException se diferencian del resto de excepciones en que no son de tipo checked. Una excepción de tipo checked debe ser capturada o bien especificar que puede ser lanzada de forma obligatoria, y si no lo hacemos obtendremos un error de compilación. Dado que las RuntimeException pueden producirse en cualquier fragmento de código, sería impensable tener que añadir manejadores de excepciones y declarar que éstas pueden ser lanzadas en todo nuestro código.
Figura 1. Tipos de excepciones
Dentro de estos grupos principales de excepciones podremos encontrar tipos concretos de excepciones o bien otros grupos que a su vez pueden contener más subgrupos de excepciones, hasta llegar a tipos concretos de ellas. Cada tipo de excepción guardará información relativa al tipo de error al que se refiera, además de la información común a todas las excepciones. Por ejemplo, una ParseException se suele utilizar al procesar un fichero. Además de almacenar un mensaje de error, guardará la línea en la que el parser encontró el error.
Cuando un fragmento de código sea susceptible de lanzar una excepción y queramos tratar el error producido o bien por ser una excepción de tipo checked debamos capturarla, podremos hacerlo mediante la estructura try-catch-finally, que consta de tres bloques de código:
Para el bloque catch además deberemos especificar el tipo o grupo de excepciones que tratamos en dicho bloque, pudiendo incluir varios bloques catch, cada uno de ellos para un tipo/grupo de excepciones distinto. La forma de hacer esto será la siguiente:
try { // Código regular del programa // Puede producir excepciones } catch(TipoDeExcepcion1 e1) { // Código que trata las excepciones de tipo // TipoDeExcepcion1 o subclases de ella. // Los datos sobre la excepción los encontraremos // en el objeto e1. } catch(TipoDeExcepcion2 e2) { // Código que trata las excepciones de tipo // TipoDeExcepcion2 o subclases de ella. // Los datos sobre la excepción los encontraremos // en el objeto e2. ... } catch(TipoDeExcepcionN eN) { // Código que trata las excepciones de tipo // TipoDeExcepcionN o subclases de ella. // Los datos sobre la excepción los encontraremos // en el objeto eN. } finally { // Código de finalización (opcional) }
Si como tipo de excepción especificamos un grupo de excepciones este bloque se encargará de la captura de todos los subtipos de excepciones de este grupo. Por lo tanto, si especificamos Exception capturaremos cualquier excepción, ya que está es la superclase común de todas las excepciones.
En el bloque catch pueden ser útiles algunos métodos de la excepción (que podemos ver en la API de la clase padre Exception):
String getMessage() void printStackTrace()
con getMessage() obtenemos una cadena descriptiva del error (si la hay). Con printStackTrace() se muestra por la salida estándar la traza de errores que se han producido (en ocasiones la traza es muy larga y no puede seguirse toda en pantalla con algunos sistemas operativos).
Un ejemplo de uso:
try
{
... // Aqui va el codigo que puede lanzar una excepcion
} catch (Exception e) {
System.out.println ("El error es: " + e.getMessage());
e.printStackTrace();
}
Hemos visto cómo capturar excepciones que se produzcan en el código, pero en lugar de capturarlas también podemos hacer que se propaguen al método de nivel superior (desde el cual se ha llamado al método actual). Para esto, en el método donde se vaya a lanzar la excepción, se siguen 2 pasos:
public void lee_fichero() throws IOException, FileNotFoundException { // Cuerpo de la función }Podremos indicar tantos tipos de excepciones como queramos en la claúsula throws. Si alguna de estas clases de excepciones tiene subclases, también se considerará que puede lanzar todas estas subclases.
throw new IOException(mensaje_error);
public void lee_fichero()
throws IOException, FileNotFoundException
{
...
throw new IOException(mensaje_error);
...
}
Podremos lanzar así excepciones en nuestras funciones para indicar que algo no es como debiera ser a las funciones llamadoras. Por ejemplo, si estamos procesando un fichero que debe tener un determinado formato, sería buena idea lanzar excepciones de tipo ParseException en caso de que la sintaxis del fichero de entrada no sea correcta.
public void leeFich()
throws ParseException
{
...
throw new ParseException("Error al procesar el fichero");
...
}
...
public void otroMetodo()
{
try
{
leeFich();
} catch (ParseException e) {
System.out.println ("Se ha producido un error al leer el fichero");
System.out.println ("El mensaje es: " + e.getMessage());
}
}
NOTA: para las excepciones que no son de tipo checked no hará falta la cláusula throws en la declaración del método, pero seguirán el mismo comportamiento que el resto, si no son capturadas pasarán al método de nivel superior, y seguirán así hasta llegar a la función principal, momento en el que si no se captura provocará el error correspondiente.
Además de utilizar los tipos de excepciones contenidos en la distribución de Java, podremos crear nuevos tipos que se adapten a nuestros problemas.
Para crear un nuevo tipo de excepciones simplemente deberemos crear una clase que herede de Exception o cualquier otro subgrupo de excepciones existente. En esta clase podremos añadir métodos y propiedades para almacenar información relativa a nuestro tipo de error. Por ejemplo:
public class MiExcepcion extends Exception
{
public MiExcepcion (String mensaje)
{
super(mensaje);
}
}
Además podremos crear subclases de nuestro nuevo tipo de excepción, creando de esta forma grupos de excepciones. Para utilizar estas excepciones (capturarlas y/o lanzarlas) hacemos lo mismo que lo explicado antes para las excepciones que se tienen definidas en Java. Por ejemplo:
public void unMetodo()
throws MiException
{
...
throw new MiException("Error en el metodo");
...
}
...
public void otroMetodo()
{
try
{
unMetodo();
} catch (MiException e) {
...
}
}
Un hilo es un flujo de control dentro de un programa que permite realizar una tarea separada. Es decir, creando varios hilos podremos realizar varias tareas simultáneamente. Cada hilo tendrá sólo un contexto de ejecución (contador de programa, pila de ejecución). Es decir, a diferencia de los procesos UNIX, no tienen su propio espacio de memoria sino que acceden todos al mismo espacio de memoria común, por lo que será importante su sincronización cuando tengamos varios hilos accediendo a los mismos objetos.
En Java los hilos están encapsulados en la clase Thread. Para crear un hilo tenemos dos posibilidades:
En ambos casos debemos definir un método run() que será el que contenga el código del hilo. Desde dentro de este método podremos llamar a cualquier otro método de cualquier objeto, pero este método run() será el método que se invoque cuando iniciemos la ejecución de un hilo. El hilo terminará su ejecución cuando termine de ejecutarse este método run().
Para crear nuestro hilo mediante herencia haremos lo siguiente:
public class EjemploHilo extends Thread
{
public void run() {
// Código del hilo
}
}
Una vez definida la clase de nuestro hilo deberemos instanciarlo y ejecutarlo de la siguiente forma:
Thread t = new EjemploHilo(); t.start();
Al llamar al método start del hilo, comenzará ejecutarse su método run. Crear un hilo heredando de Thread tiene el problema de que al no haber herencia múltiple en Java, si heredamos de Thread no podremos heredar de ninguna otra clase, y por lo tanto un hilo no podría heredar de ninguna otra clase.
Este problema desaparece si utilizamos la interfaz Runnable para crear el hilo, ya que una clase puede implementar varios interfaces. Definiremos la clase que contenga el hilo como se muestra a continuación:
public class EjemploHilo implements Runnable
{
public void run() {
// Código del hilo
}
}
Para instanciar y ejecutar un hilo de este tipo deberemos hacer lo siguiente:
Thread t = new Thread(new EjemploHilo()); t.start();
Esto es así debido a que en este caso EjemploHilo no deriva de una clase Thread, por lo que no se puede considerar un hilo, lo único que estamos haciendo implementando la interfaz es asegurar que vamos a tener definido el método run(). Con esto lo que haremos será proporcionar esta clase al constructor de la clase Thread, para que el objeto Thread que creemos llame al método run() de la clase que hemos definido al iniciarse la ejecución del hilo, ya que implementando la interfaz le aseguramos que esta función existe.
Un hilo pasará por varios estados durante su ciclo de vida.
Thread t = new Thread(this);
Una vez se ha instanciado el objeto del hilo, diremos que está en estado de Nuevo hilo.
t.start();
Cuando invoquemos su método start() el hilo pasará a ser un hilo vivo, comenzándose a ejecutar su método run(). Una vez haya salido de este método pasará a ser un hilo muerto.
La única forma de parar un hilo es hacer que salga del método run() de forma natural. Podremos conseguir esto haciendo que se cumpla una condición de salida de run() (lógicamente, la condición que se nos ocurra dependerá del tipo de programa que estemos haciendo). Las funciones para parar, pausar y reanudar hilos están desaprobadas en las versiones actuales de Java.
Mientras el hilo esté vivo, podrá encontrarse en dos estados: Ejecutable y No ejecutable. El hilo pasará de Ejecutable a No ejecutable en los siguientes casos:
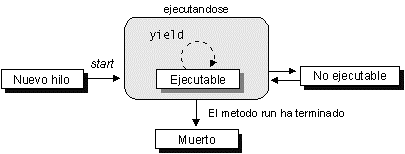
Figura 2. Ciclo de vida de los hilos
Lo único que podremos saber es si un hilo se encuentra vivo o no, llamando a su método isAlive().
Prioridades de los hilos
Además, una propiedad importante de los hilos será su prioridad. Mientras el hilo se encuentre vivo, el scheduler de la máquina virtual Java le asignará o lo sacará de la CPU, coordinando así el uso de la CPU por parte de todos los hilos activos basándose en su prioridad. Se puede forzar la salida de un hilo de la CPU llamando a su método yield(). También se sacará un hilo de la CPU cuando un hilo de mayor prioridad se haga Ejecutable, o cuando el tiempo que se le haya asignado expire.
Para cambiar la prioridad de un hilo se utiliza el método setPriority(), al que deberemos proporcionar un valor de prioridad entre MIN_PRIORITY y MAX_PRIORITY (tenéis constantes de prioridad disponibles dentro de la clase Thread, consultad el API de Java para ver qué valores de constantes hay).
Hilo actual
En cualquier parte de nuestro código Java podemos llamar al método currentThread de la clase Thread, que nos devuelve un objeto hilo con el hilo que se encuentra actualmente ejecutando el código donde está introducido ese método. Por ejemplo, si tenemos un código como:
public class EjemploHilo implements Runnable
{
public EjemploHilo()
{
...
int i = 0;
Thread t = Thread.currentThread();
t.sleep(1000);
}
}
La llamada a currentThread dentro del constructor de la clase nos devolverá el hilo que corresponde con el programa principal (puesto que no hemos creado ningún otro hilo, y si lo creáramos, no ejecutaría nada que no estuviese dentro de un método run.
Sin embargo, en este otro caso:
public class EjemploHilo implements Runnable
{
public EjemploHilo()
{
Thread t1 = new Thread(this);
Thread t2 = new Thread(this);
t1.start();
t2.start();
}
public void run()
{
int i = 0;
Thread t = Thread.currentThread();
t.sleep(1000);
}
}
Lo que hacemos es crear dos hilos auxiliares, y la llamada a currentThread se produce dentro del run, con lo que se aplica a los hilos auxiliares, que son los que ejecutan el run: primero devolverá un hilo auxiliar (el que primero entre, t1 o t2), y luego el otro (t2 o t1).
Dormir hilos
Como hemos visto en los ejemplos anteriores, una vez obtenemos el hilo que queremos, el método sleep nos sirve para dormirlo, durante los milisegundos que le pasemos como parámetro (en los casos anteriores, dormían durante 1 segundo). El tiempo que duerme el hilo, deja libre el procesador para que lo ocupen otros hilos. Es una forma de no sobrecargar mucho de trabajo a la CPU con muchos hilos intentando entrar sin descanso.
Muchas veces los hilos deberán trabajar de forma coordinada, por lo que es necesario un mecanismo de sincronización entre ellos.
Un primer mecanismo de comunicación es la variable cerrojo incluida en todo objeto Object, que permitirá evitar que más de un hilo entre en la sección crítica para un objeto determinado. Los métodos declarados como synchronized utilizan el cerrojo del objeto al que pertenecen evitando que más de un hilo entre en ellos al mismo tiempo.
public synchronized void seccion_critica()
{
// Código sección crítica
}
Todos los métodos synchronized de un mismo objeto (no clase, sino objeto de esa clase), comparten el mismo cerrojo, y es distinto al cerrojo de otros objetos (de la misma clase, o de otras).
También podemos utilizar cualquier otro objeto para la sincronización dentro de nuestro método de la siguiente forma:
synchronized (objeto_con_cerrojo)
{
// Código sección crítica
}
de esta forma sincronizaríamos el código que escribiésemos dentro, con el código synchronized del objeto objeto_con_cerrojo.
Además podemos hacer que un hilo quede bloqueado a la espera de que otro hilo lo desbloquee cuando suceda un determinado evento. Para bloquear un hilo usaremos la función wait(), para lo cual el hilo que llama a esta función debe estar en posesión del monitor, cosa que ocurre dentro de un método synchronized, por lo que sólo podremos bloquear a un proceso dentro de estos métodos.
Para desbloquear a los hilos que haya bloqueados se utilizará notifyAll(), o bien notify() para desbloquear sólo uno de ellos aleatoriamente. Para invocar estos métodos ocurrirá lo mismo, el hilo deberá estar en posesión del monitor.
Cuando un hilo queda bloqueado liberará el cerrojo para que otro hilo pueda entrar en la sección crítica del objeto y desbloquearlo.
Por último, puede ser necesario esperar a que un determinado hilo haya finalizado su tarea para continuar. Esto lo podremos hacer llamando al método join() de dicho hilo, que nos bloqueará hasta que el hilo haya finalizado.
Los grupos de hilos nos permitirán crear una serie de hilos y manejarlos todos a la vez como un único objeto. Si al crear un hilo no se especifica ningún grupo de hilos, el hilo creado pertenecerá al grupo de hilos por defecto.
Podemos crearnos nuestro propio grupo de hilos instanciando un objeto de la clase ThreadGroup. Para crear hilos dentro de este grupo deberemos pasar este grupo al constructor de los hilos que creemos.
ThreadGroup grupo = new ThreadGroup("Grupo de hilos");
Thread t = new Thread(grupo,new EjemploHilo());
Los programas muy a menudo necesitan enviar datos a un determinado destino, o bien leerlos de una determinada fuente externa, como por ejemplo puede ser un fichero para almacenar datos de forma permanente, o bien enviar datos a través de la red, a memoria, o a otros programas. Esta entrada/salida de datos en Java la realizaremos por medio de flujos (streams) de datos, a través de los cuales un programa podrá recibir o enviar datos en serie.
Existen varios objetos que hacen de flujos de datos, y que se distinguen por la finalidad del flujo de datos y por el tipo de datos que viajen a través de ellos. Según el tipo de datos que transporten podemos distinguir:
Dentro de cada uno de estos grupos tenemos varios pares de objetos, de los cuales uno nos servirá para leer del flujo y el otro para escribir en él. Cada par de objetos será utilizado para comunicarse con distintos elementos (memoria, ficheros, red u otros programas). Estas clases, según sean de entrada o salida y según sean de caracteres o de bytes llevarán distintos sufijos, según se muestra en la siguiente tabla:
| Flujo de entrada / lector | Flujo de salida / escritor | |
| Caracteres | XXXXReader | XXXXWriter |
| Bytes | XXXXInputStream | XXXXOutputStream |
Donde XXXX se referirá a la fuente o sumidero de los datos. Puede tomar valores como los que se muestran a continuación:
| File | Acceso a ficheros |
| Piped | Comunicación entre programas mediante tuberías (pipes) |
| String | Acceso a una cadena en memoria (solo caracteres) |
| CharArray | Acceso a un array de caracteres en memoria (solo caracteres) |
| ByteArray | Acceso a un array de bytes en memoria (solo bytes) |
Además podemos distinguir los flujos de datos según su propósito, pudiendo ser:
Un tipo de filtros de procesamiento a destacar son aquellos que nos permiten convertir un flujo de bytes a flujo de caracteres. Estos objetos son InputStreamReader y OutputStreamWriter. Como podemos ver en su sufijo, son flujos de caracteres, pero se construyen a partir de flujos de bytes, permitiendo de esta manera acceder a nuestro flujo de bytes como si fuese un flujo de caracteres.
Para cada uno de los tipos básicos de flujo que hemos visto existe una superclase, de la que heredaran todos sus subtipos, y que contienen una serie de métodos que serán comunes a todos ellos. Entre estos métodos encontramos los métodos básicos para leer o escribir caracteres o bytes en el flujo a bajo nivel. En la siguiente tabla se muestran los métodos más importantes de cada objeto:
| InputStream | read(), reset(), available(), close() |
| OutputStream | write(int b), flush(), close() |
| Reader | read(), reset(), close() |
| Writer | write(int c), flush(), close() |
Aparte de estos métodos podemos encontrar variantes de los métodos de lectura y escritura, otros métodos, y además cada tipo específico de flujo contendrá sus propios métodos. Todas estas clases se encuentran en el paquete java.io. Para más detalles sobre ellas se puede consultar la especificación de la API de Java.
Al igual que en C, en Java también existen los conceptos de entrada, salida, y salida de error estándar. La entrada estándar normalmente se refiere a lo que el usuario escribe en la consola, aunque el sistema operativo puede hacer que se tome de otra fuente. De la misma forma la salida y la salida de error estándar lo que hacen normalmente es mostrar los mensajes y los errores del programa respectivamente en la consola, aunque el sistema operativo también podrá redirigirlas a otro destino.
En Java esta entrada, salida y salida de error estándar se tratan de la misma forma que cualquier otro flujo de datos, estando estos tres elementos encapsulados en tres objetos de flujo de datos que se encuentran como propiedades estáticas de la clase System:
| Tipo | Objeto | |
| Entrada estándar | InputStream | System.in |
| Salida estándar | PrintStream | System.out |
| Salida de error estándar | PrintStream | System.err |
Para la entrada estándar vemos que se utiliza un objeto InputStream básico, sin embargo para la salida se utilizan objetos PrintWriter que facilitan la impresión de texto ofreciendo a parte del método común de bajo nivel write(int b) para escribir bytes, dos métodos más: print(s) y println(s). Estas funciones nos permitirán escribir cualquier cadena, tipo básico, o bien cualquier objeto que defina el método toString() que devuelva una representación del objeto en forma de cadena. La única diferencia entre los dos métodos es que el segundo añade automáticamente un salto de línea al final del texto impreso, mientras que en el primero deberemos especificar explícitamente este salto.
Para escribir texto en la consola normalmente utilizaremos:
System.out.println("Hola mundo");
En el caso de la impresión de errores por la salida de error de estándar, deberemos utilizar:
System.err.println("Error: Se ha producido un error");
Además la clase System nos permite sustituir estos flujos por defecto por otros flujos, cambiando de esta forma la entrada, salida y salida de error estándar.
Podremos acceder a ficheros bien por caracteres, o bien de forma binaria (por bytes). Las clases que utilizaremos en cada caso son:
| Lectura | Escritura | |
| Caracteres | FileReader | FileWriter |
| Binarios | FileInputStream | FileOutputStream |
Para crear un lector o escritor de ficheros deberemos proporcionar al constructor el fichero del que queremos leer o en el que queramos escribir. Podremos proporcionar esta información bien como una cadena de texto con el nombre del fichero, o bien construyendo un objeto File representando al fichero al que queremos acceder. Este objeto nos permitirá obtener información adicional sobre el fichero, a parte de permitirnos realizar operaciones sobre el sistema de ficheros.
A continuación vemos un ejemplo simple de la copia de un fichero carácter a carácter:
public void copia_fichero() {
int c;
try {
FileReader in = new FileReader("fuente.txt");
FileWriter out = new FileWriter("destino.txt");
while( (c = in.read()) != -1)
{
out.write(c);
}
in.close();
out.close();
} catch(FileNotFoundException e1) {
System.err.println("Error: No se encuentra el fichero");
} catch(IOException e2) {
System.err.println("Error leyendo/escribiendo fichero");
}
}
En el ejemplo podemos ver que para el acceso a un fichero es necesario capturar dos excepciones, para el caso de que no exista el fichero al que queramos acceder y por si se produce un error en la E/S.
Para la escritura podemos utilizar el método anterior, aunque muchas veces nos resultará mucho más cómodo utilizar un objeto PrintWriter con el que podamos escribir directamente líneas de texto:
public void escribe_fichero() {
FileWriter out = null;
PrintWriter p_out = null;
try {
out = new FileWriter("result.txt");
p_out = new PrintWriter(out);
p_out.println("Este texto será escrito en el fichero de salida");
} catch(IOException e) {
System.err.println("Error al escribir en el fichero");
} finally {
p_out.close();
}
}
Observad también el uso del bloque finally, para cerrar el fichero tanto si se produce un error al escribir en él como si no.
Un caso particular: ficheros de propiedades
La clase java.util.Properties permite manejar de forma muy sencilla lo que se conoce como ficheros de propiedades. Dichos ficheros permiten almacenar una serie de pares nombre=valor, de forma que tendría una apariencia como esta:
#Comentarios elemento1=valor1 elemento2=valor2 ... elementoN=valorN
Para leer un fichero de este tipo, basta con crear un objeto Properties, y llamar a su método load(), pasándole como parámetro el fichero que queremos leer, en forma de flujo de entrada (InputStream):
Properties p = new Properties();
p.load(new FileInputStream("datos.txt");
Una vez leído, podemos acceder a todos los elementos del fichero desde el objeto Properties cargado. Tenemos los métodos getProperty y setProperty para acceder a y modificar valores:
String valorElem1 = p.getProperty("elemento1");
p.setProperty("elemento2", "otrovalor");
También podemos obtener todos los nombres de elementos que hay, y recorrerlos, mediante el método propertyNames(), que nos devuelve una Enumeration para ir recorriendo:
Enumeration en = p.propertyNames();
while (en.hasMoreElements())
{
String nombre = (String)(en.nextElement());
String valor = p.getProperty(nombre);
}
Una vez hayamos leído o modificado lo que quisiéramos, podemos volver a guardar el fichero de propiedades, con el método store de Properties, al que se le pasa un flujo de salida (OutputStream) y una cabecera para el fichero:
p.store(new FileOutputStream("datos.txt"), "Fichero de propiedades");
Hemos visto como leer un fichero carácter a carácter, pero en el caso de ficheros con una gramática medianamente compleja, esta lectura a bajo nivel hará muy difícil el análisis de este fichero de entrada. Necesitaremos leer del fichero elementos de la gramática utilizada, los llamados tokens, como pueden ser palabras, número y otros símbolos.
La clase StreamTokenizer se encarga de partir la entrada en tokens y nos permitirá realizar la lectura del fichero directamente como una secuencia de tokens. Esta clase tiene una serie de constantes identificando los tipos de tokens que puede leer:
| StreamTokenizer.TT_WORD | Palabra |
| StreamTokenizer.TT_NUMBER | Número real o entero |
| StreamTokenizer.TT_EOL | Fin de línea |
| StreamTokenizer.TT_EOF | Fin de fichero |
| Carácter de comillas establecido | Cadena de texto encerrada entre comillas |
| Símbolos | Vendrán representados por el código del carácter ASCII del símbolo |
Dado que un StreamTokenizer se utiliza para analizar un fichero de texto, siempre habrá que crearlo a partir de un objeto Reader (o derivados).
StreamTokenizer st = new StreamTokenizer(reader);
El método nextToken() leerá el siguiente token que encuentre en el fichero y nos devolverá el tipo de token del que se trata. Según este tipo podremos consultar las propiedades sval o nval para ver qué cadena o número respectivamente se ha leído del fichero. Tanto cuando se lea un token de tipo TT_WORD como de tipo cadena de texto entre comillas el valor de este token estará almacenado en sval. En caso de la lectura sea un número, su valor se almacenará en nval que es de tipo double. Como los demás símbolos ya devuelven el código del símbolo como tipo de token no será necesario acceder a su valor por separado. Podremos consultar el tipo del último token leído en la propiedad ttype.
Un bucle de procesamiento básico será el siguiente:
while(st.nextToken() != StreamTokenizer.TT_EOF) {
switch(st.ttype) {
case StreamTokenizer.TT_WORD:
System.out.println("Leida cadena: " + st.sval);
break;
case StreamTokenizer.TT_NUMBER:
System.out.println("Leido numero: " + st.nval);
break;
}
}
Podemos distinguir tres tipos de caracteres:
| Ordinarios (ordinaryChars) | Caracteres que forman parte de los tokens. |
| De palabra (wordChars) | Una secuencia formada enteramente por este tipo de caracteres se considerará una palabra. |
| De espacio en blanco (whitespaceChars) | Estos caracteres no son interpretados como tokens, simplemente se utilizan para separar tokens. Normalmente estos caracteres son el espacio, tabulador, y salto de línea. |
Para establecer qué caracteres pertenecerán a cada uno de estos tipos utilizaremos los métodos ordinaryChars, wordChars y whitespaceChars del objeto StreamTokenizer respectivamente. A cada uno de estos métodos le pasamos un rango de caracteres (según su código ASCII), que serán establecidos al tipo correspondiente al método que hayamos llamado. Por ejemplo, si queremos que una palabra sea una secuencia de cualquier carácter imprimible (con códigos ASCII desde 32 a 127) haremos lo siguiente:
st.wordChars(32,127);
Los caracteres pueden ser especificados tanto por su código ASCII numérico como especificando ese carácter entre comillas simples. Si ahora queremos hacer que las palabras sean separadas por el caracter ':' (dos puntos) hacemos la siguiente llamada:
st.whitespaceChars(':', ':');
De esta forma, si hemos hecho las llamadas anteriores el tokenizer leerá palabras formadas por cualquier carácter imprimible separadas por los dos puntos ':'. Al querer cambiar un único carácter, como siempre deberemos especificar un rango, deberemos especificar un rango formado por ese único carácter como inicial y final del rango. Si además quisieramos utilizar el guión '-' para separar palabras, no siendo caracteres consecutivos guión y dos puntos en la tabla ASCII, tendremos que hacer una tercera llamada:
st.whitespaceChars('-', '-');
Así tendremos tanto el guión como los dos puntos como separadores, y el resto de caracteres imprimibles serán caracteres de palabra. Podemos ver que el StreamTokenizer internamente implementa una tabla, en la que asocia a cada carácter uno de los tres tipos mencionados. Al llamar a cada uno de los tres métodos cambiará el tipo de todo el rango especificado al tipo correspondiente al método. Por ello es importante el orden en el que invoquemos este método. Si en el ejemplo en el que hemos hecho estas tres llamadas las hubiésemos hecho en orden inverso, al establecer todo el rango de caracteres imprimibles como wordChars hubiésemos sobrescrito el resultado de las otras dos llamadas y por lo tanto el guión y los dos puntos no se considerarían separadores.
Podremos personalizar el tokenizer indicando para cada carácter a que tipo pertenece. Además de con los tipos anteriores, podemos especificar el carácter que se utilice para encerrar las cadenas de texto (quoteChar), mediante el método quoteChar, y el carácter para los comentarios (commentChar), mediante commentChar. Esto nos permitirá definir comentarios de una línea que comiencen por un determinado carácter, como por ejemplo los comentarios estilo Pascal comenzados por el carácter almohadilla ('#'). Además tendremos otros métodos para activar comentarios tipo C como los comentarios barra-barra (//) y barra-estrella (/* */).
Hemos visto como leer y escribir ficheros, pero cuando ejecutamos una aplicación contenida en un fichero JAR, puede que necesitemos leer recursos contenidos dentro de este JAR.
Para acceder a estos recursos deberemos abrir un flujo de entrada que se
encargue de leer su contenido. Para ello utilizaremos el método getResourceAsStream
de la clase Class:
InputStream in = getClass().getResourceAsStream("/datos.txt");
De esta forma podremos utilizar el flujo de entrada obtenido para leer el contenido del fichero que hayamos indicado. Este fichero deberá estar contenido en el JAR de la aplicación.
Especificamos el carácter '/' delante del nombre del recurso
para referenciarlo de forma relativa al directorio raíz del JAR. Si no lo
especificásemos de esta forma se buscaría de forma relativa al directorio
correspondiente al paquete de la clase actual.
Si queremos guardar datos en un fichero binario deberemos
codificar estos datos en forma de array de bytes. Los flujos
de procesamiento DataInputStream y DataOutputStream
nos permitirán codificar y descodificar respectivamente los tipos de datos
simples en forma de array de bytes para ser enviados a través
de un flujo de datos.
Por ejemplo, podemos codificar datos en un array
en memoria (ByteArrayOutputStream) de la siguiente forma:
String nombre = "Jose"; String edad = 25; ByteArrayOutputStream baos = new ByteArrayOutputStream(); DataOutputStream dos = new DataOutputStream(baos); dos.writeUTF(nombre); dos.writeInt(edad); dos.close(); baos.close(); byte [] datos = baos.toByteArray();
Podremos descodificar este array de bytes
realizando el procedimiento inverso, con un flujo que lea un array de bytes
de memoria (ByteArrayInputStream):
ByteArrayInputStream bais = new ByteArrayInputStream(datos); DataInputStream dis = new DataInputStream(bais); String nombre = dis.readUTF(); int edad = dis.readInt();
Si en lugar de almacenar estos datos codificados en una array
en memoria queremos guardarlos codificados en un fichero, haremos lo mismo
simplemente sustituyendo el flujo canal de datos ByteArrayOutputStream
por un FileOutputStream. De esta forma podremos utilizar cualquier
canal de datos para enviar estos datos codificados a través de él.
Si queremos enviar un objeto complejo a través de un flujo de datos, deberemos convertirlo en una serie de bytes. Esto es lo que se conoce como serialización de objetos, que nos permitirá leer y escribir objetos.
Para leer o escribir objetos podemos utilizar los objetos ObjectInputStream y ObjectOutputStream que incorporan los métodos readObject() y writeObject(Object obj) respectivamente. Los objetos que escribamos en dicho flujo deben tener la capacidad de ser serializables.
Serán serializables aquellos objetos que implementan la interfaz Serializable. Cuando queramos hacer que una clase definida por nosotros sea serializable deberemos implementar dicho interfaz, que no define ninguna función, sólo se utiliza para identificar las clases que son serializables. Para que nuestra clase pueda ser serializable, todas sus propiedades deberán ser de tipos de datos básicos o bien objetos que también sean serializables.