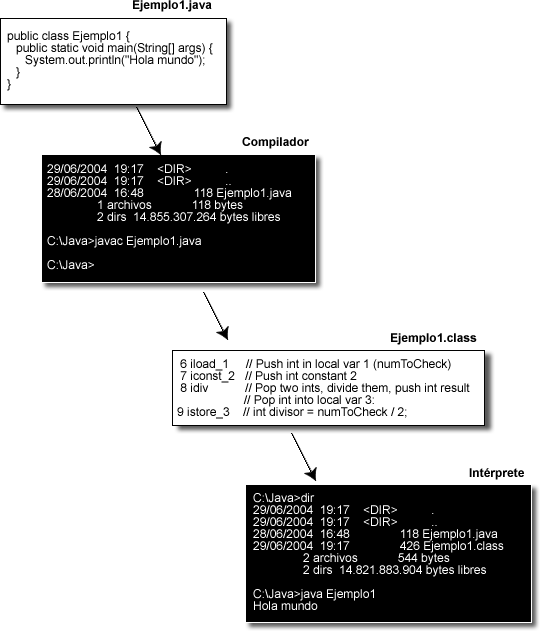
El código Java, una vez compilado, puede llevarse sin modificación alguna sobre cualquier sistema operativo (Windows, Linux, Mac OS X, IBM, ...), y ejecutarlo allí. Esto se debe a que el código se compila a un lenguaje intermedio (llamado bytecodes) independiente de la máquina. Este lenguaje intermedio es interpretado por el intérprete Java, denominado Java Virtual Machine (JVM), que deberá existir en la plataforma en la que queramos ejecutar el código. La siguiente figura ilustra el proceso.
Figura 1.1.1.1 Proceso de compilación y ejecución de un programa Java
El hecho de que la ejecución de los programas Java sea realizada por un intérprete, en lugar de ser código nativo, ha generado la suposición de que los programas Java son más lentos que programas escritos en otros lenguajes compilados (como C o C++). Aunque esto es cierto en algunos casos, se ha avanzado mucho en la tecnología de interpretación de bytecodes y en cada nueva versión de Java se introducen optimizaciones en este funcionamiento. En la última versión de Java, 1.5 (ahora todavía en beta), se introduce una nueva JVM servidora que queda residente en el sistema. Esta máquina virtual permite ejecutar más de un programa Java al mismo tiempo, mejorando mucho el manejo de la memoria. Por último, es posible encontrar bastantes benchmarks en donde los programas Java son más rápidos que programas C++ en algunos aspectos.
Los ficheros fuente de Java tienen la extensión .java.
Cada fichero .java define una clase pública (y,
posiblemente, más de una clase privada usada por la clase
pública). En el apartado siguiente realizaremos una
introducción a la programación orientada a objetos (OO).
Los ficheros bytecodes generados por la compilación tienen la
extensión .class. Un fichero .java
puede generar más de un fichero .class, si en el
fichero .java se define más de una clase. El
nombre del fichero .java debe corresponder con el nombre de una clase
definida en él.
Las clases (ficheros .class) se organizan en paquetes.
Un paquete contiene un conjunto de clases. A su vez, un paquete puede
contener a otros paquetes. La estructura es similar a la de los
directorios y ficheros. Los ficheros hacen el papel de las clases Java
y los directorios hacen el papel de paquetes. De hecho, la estructura
de directorios en la que se organizan los ficheros .class
(estructura física del sistema operativo) debe corresponderse
con la estructura de paquetes definida en los ficheros fuente .java.
Por ejemplo, si al comienzo de un fichero .java
llamado Persona.java se escribe
package misclases.negocios;
estamos declarando que la clase Persona (el fichero Persona.class)
deberá residir en una estructura de directorios misclases/negocios.
El directorio misclases puede estar en cualquier lugar
del árbol de directorios del sistema operativo; eso sí,
su directorio padre debe estar incluido en la variable CLASSPATH para que el
intérprete y el compilador java pueda encontrar la clase Persona.
Los directorios de paquetes y los ficheros de clases pueden
compactarse en ficheros JAR (por ejemplo misclases.jar).
Un fichero JAR es un fichero de archivo (como ZIP o TAR) que contiene
comprimidos un conjunto de directorios y ficheros. Es normal comprimir
toda una libería de clases y paquetes comunes en un único
fichero JAR. Para crear un fichero JAR hay que llamar al comando jar
del SDK, es un comando similar al comando tar de Linux.
Para que el compilador y el intérprete pueda usar las clases de un fichero JAR, hay que incluir su camino (incluyendo el propio fichero JAR) en el CLASSPATH.
Cuando se programa con Java, se dispone de antemano de un conjunto de clases ya implementadas. Estas clases (aparte de las que pueda hacer el usuario) forman parte del propio lenguaje (lo que se conoce como API (Application Programming Interface) de Java).
Una herramienta muy útil son las páginas HTML con la documentación del API de Java 1.4.2. Puedes encontrar estas páginas en los recursos del curso.
Si consultamos la página principal de la documentación, veremos el enlace "Java 2 Platform API Specification" dentro del apartado "API & Language Documentation". Siguiendo ese enlace, aparece la siguiente página HTML. Es una página con tres frames. En la zona superior del lateral izquierdo se listan todos los paquetes de la versión 1.4.2 de Java. La zona inferior muestra una lista con todas las clases existentes en el API. La zona principal describe todos los paquetes existentes en la plataforma.
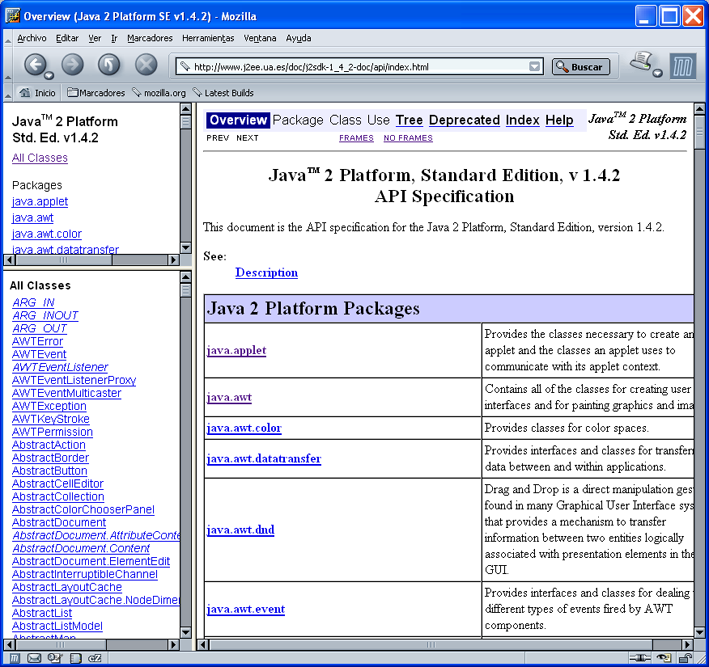
Figura 1.1.1.2 El API de Java 1.4.2
Si seleccionamos un paquete, por ejemplo java.rmi,
aparece la siguiente página HTML. En el frame inferior izquierdo
aparecen los elementos que constituyen el paquete: las clases,
interfaces y excepciones definidas en el mismo. En el frame principal
se describen con más detalle estos elementos. Todos los
elementos están enlazados a la página en la que se
detalla la clase, el interface o la excepción.
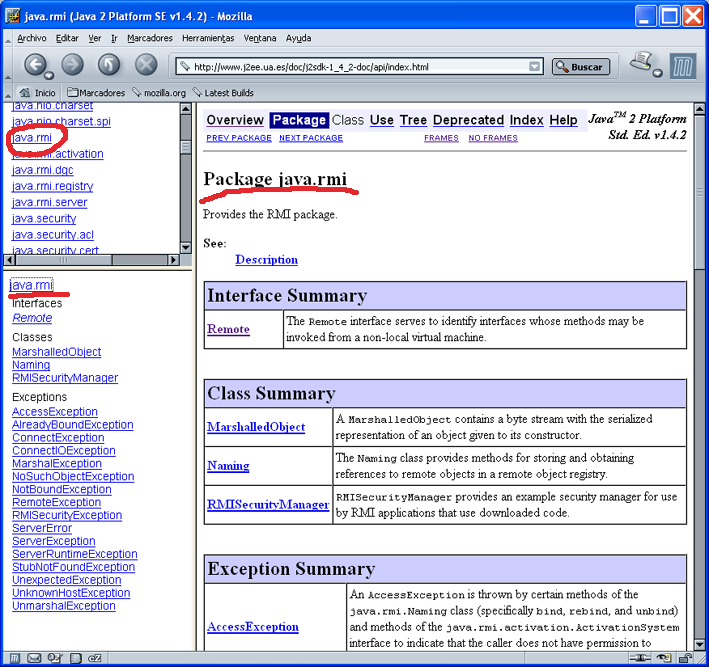
Figura 1.1.1.3 Descripción de un paquete
Cuando escogemos una clase, por ejemplo la clase Integer
del paquete java.lang, aparece una página como la
siguiente. En la ventana principal se muestra la jerarquía de la
clase, todas las interfaces que implementa la clase y sus elementos
constituyentes: campos, constructores y métodos (ver figura
1.1.1.5). En este caso, la clase Integer hereda de la
clase Number (en el paquete java.lang), la
cual hereda de la clase Object (también en el
paquete java.lang). La clase Integer
implementa la interfaz Comparable y la interfaz Serializable
(porque es implementada por la clase Number).
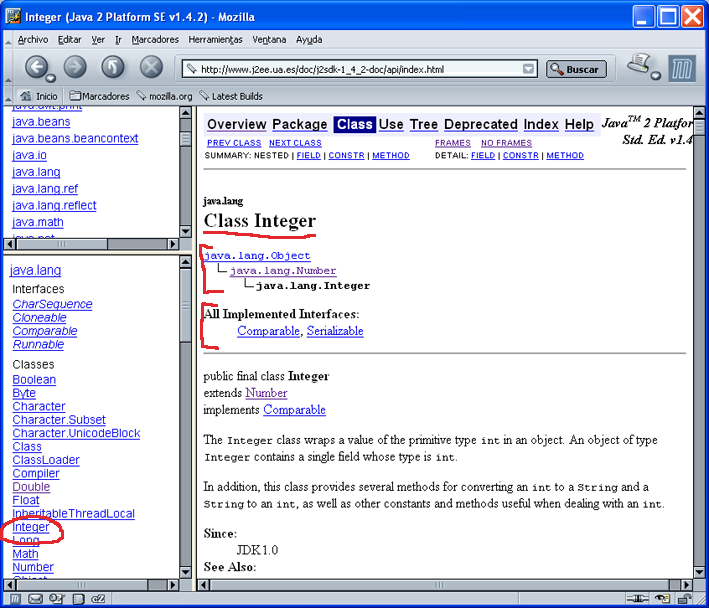
Figura 1.1.1.4 Descripción de una clase
En la figura siguiente se detallan algunos elementos que componen la
clase Integer.
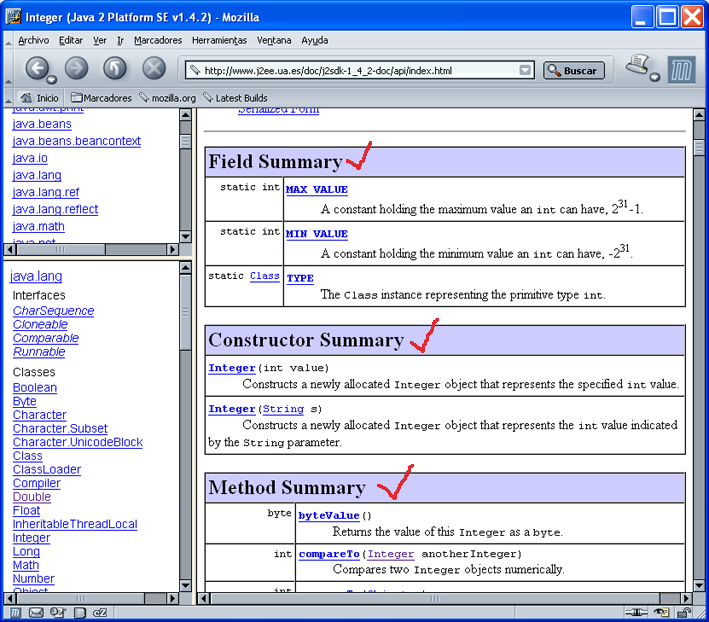
Figura 1.1.1.5 Elementos de una clase
Para compilar y ejecutar programas Java necesitamos la distribución JDK (Java Development Kit) de Sun. Es necesario tener instalada esta distribución para poder trabajar con otros entornos de desarrollo, puesto que dichos entornos se apoyan en la API de clases que viene con JDK.
La instalación es bastante sencilla (tanto en Windows como en Linux). En windows habrá que elegir el directorio donde instalar, y en Linux en general se descomprime en el lugar que se quiera. También es recomendable instalar (descomprimir) la documentación de la API
Para su correcto funcionamiento, Java necesita tener establecidas algunas variables de entorno: las variables PATH y CLASSPATH.
La variable de entorno del sistema PATH deberá contener la ruta donde se encuentren los programas para compilar y ejecutar con JDK (javac y java, respectivamente). Por ejemplo:
set PATH=%PATH%;C:\j2sdk1.4.2_02\bin (Windows)
export PATH=$PATH:/j2sdk1.4.2_02/bin (Linux)
Con la variable CLASSPATH indicamos en qué directorios debe buscar el intérprete de Java las clases compiladas. Por defecto, si CLASSPATH no está definido, las busca en el directorio actual. Puede haber más de un directorio, separando sus caminos por el separador del sistema operativo (";" en Windows y ":" en Linux). Por ejemplo, si las clases que queremos usar están en \misclases:
set CLASSPATH=.;C:\misclases (Windows)
export CLASSPATH=.:/misclases
Si las clases pertenecen a un paquete concreto, se debe apuntar al directorio a partir del cual comienzan los directorios del paquete. Por ejemplo, si la clase MiClase está en el paquete unpaquete, dentro de \mispaquetes (\mispaquetes\unpaquete\MiClase.class):
set CLASSPATH=.;C:\misclases;C:\mispaquetes (Windows)
export CLASSPATH=.:/misclases:/mispaquetes (Linux)
Si las clases están empaquetadas en un fichero JAR, se tendrá que hacer referencia a dicho fichero. Por ejemplo:
set CLASSPATH=.;C:\misclases\misclases.jar (Windows)Para hacer estos cambios permanentes deberemos modificar los ficheros de autoarranque de cada sistema operativo, añadiendo las líneas correspondientes en autoexec.bat (para Windows) o .profile (para Linux).
export CLASSPATH=.:/misclases/misclases.jar (Linux)
La forma de establecer las variables cambia en función de la versión de Windows o Linux. Por ejemplo, en Windows 2000 o XP se pueden establecer variables de entorno directamente desde el panel de control. Y en versiones distintas de Linux se utilizan distintos shells con comandos de establecimiento distintos al export (ver información más detallada en el apéndice 2).
Para compilar y ejecutra las
clases Java se usan los programas javac
y java que
proporciona el SDK.
Veamos el siguiente programa Java. Se trata de un sencillo programa
ejemplo en el que se define una clase Persona con varios
métodos. Uno de ellos es el constructor (crea objetos de tipo Persona)
y otro es el método estático main que hace
que la clase sea ejecutable directamente por el intérprete Java.
/**El fichero lo puedes encontrar en este enlace. Si queremos compilarlo debemos llamar a javac:
* Ejemplo de clase Java
*/
public class Persona {
public String nombre;
int edad;
/**
* Constructor
*/
public Persona() {
nombre = "Pepe";
edad = 33;
}
public void setNombre(String nombre) {
this.nombre = nombre;
}
public String getNombre() {
return nombre;
}
public int getEdad() {
return edad;
}
public static void main(String[] args) {
// Datos de la persona
Persona p = new Persona();
System.out.println("Nombre de persona: " + p.getNombre());
p.setNombre("Maria");
System.out.println("Nombre de persona: " + p.getNombre());
System.out.println("Edad de persona: " + p.getEdad());
// al ser el campo nombre publico, tambien puedo
// cambiarlo y leerlo accediendo directamente
p.nombre = "Pepa";
System.out.println("Nombre de persona: " + p.nombre);
}
}
javac Persona.java
Tras haber compilado el ejemplo se tendrá un fichero Persona.class
. Ejecutamos el programa con java :
java Persona
Si se quisieran pasar parámetros a un programa Java (no es el caso del ejemplo anterior), se pasan después de la clase:
java Persona 20 56 Hola
También podemos ejecutar un fichero JAR, si contiene una clase principal. Para ello pondremos:
java -jar Fichero.jar
Veamos otro ejemplo. Supongamos los siguientes ficheros:
./Persona.java
./animales/Elefante.class
./insectos/Mosca.class
./maspersonas.jar
Vemos que sólo tenemos el código fuente de una clase (Persona.java)
y el resto son clases compiladas (la clase Elefante en el
paquete animales, la clase Mosca en el
paquete insectos y el fichero JAR maspersonas.jar
que contiene la clase OtraPersona). Puedes obtener un
fichero ZIP con todos estos ficheros en este enlace. Para compilar
la clase Persona.java verás que no hace falta
tener los códigos fuentes de las otras clases, sólo sus
ficheros compilados. Hay que incluir en el CLASSPATH el directorio
actual y el fichero JAR:
set CLASSPATH=.:.\maspersonas.jar (Windows)Luego se compila y ejecuta igual que en el ejemplo anterior.
export CLASSPATH=.:./maspersonas.jar (Linux)
Notar que para compilar se pone la extensión del fichero (.java ), pero para ejecutar no se pone la extensión .class, ya que para ejecutar una clase Java hay que pasarle al intérprete el nombre de una clase, no el nombre del fichero de bytecodes. Los nombres de ficheros que pasemos para compilar y ejecutar deben coincidir en mayúsculas y minúsculas con los nombres reales.
En Programación Orientada a Objetos un programa es un
conjunto de objetos interactuando entre si. Cada objeto guarda un
estado (mediante sus campos, también llamados variables de
instancias) y proporciona un conjunto de métodos con los que
puede ejecutar una conducta. Tanto los métodos como las
variables de instancia de un objeto vienen definidas en su clase.
Supongamos la clase Persona definida en el ejemplo anterior. En esa
clase se definen los campos (también llamados variables de
insancia) nombre y edad. También se definen los métodos
Persona (es el constructor, que sirve para crear nuevos objetos de esta
clase), getNombre() y getEdad() que devuelven la información del
objeto y por último los métodos setNombre(nombre) y
setEdad(edad) que modifican la información del objeto. Cada
objeto mantienen un
import java.util.*;
public class
MiClase
{
...
public int a;
Vector v;
public void imprimirA()
public void insertarVector(String cadena)
public MiClase()
Así, podemos definir una instancia con new:
MiClase mc;No tenemos que preocuparnos de liberar la memoria del objeto al dejar de utilizarlo. Esto lo hace automáticamente el garbage collector. Aún así, podemos usar el método finalize() para liberar manualmente.
mc = new MiClase ();
mc.a++;
mc.insertarVector("hola");
Con la herencia podemos definir una clase a partir de otra que ya exista, de forma que la nueva clase tendrá todas las variables y métodos de la clase a partir de la que se crea, más las variables y métodos nuevos que necesite. A la clase base a partir de la cual se crea la nueva clase se le llama superclase.
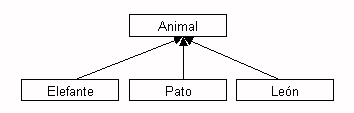
Figura 1.2.2.1 Ejemplo de herencia
class Pato extends Animal
public class MiClase {
int i;
public MiClase (int i) {
this.i = i; // i de la clase = parametro i
}
}
public class MiNuevaClase extends MiClase {
public void Suma_a_i (int j) {
i = i + (j / 2);
super.Suma_a_i (j);
}
}
Mediante las clases abstractas y los interfaces
podemos definir el esqueleto de una familia de clases, de forma que los
subtipos de la clase abstracta o la interfaz implementen ese esqueleto
para dicho subtipo concreto. Por ejemplo, podemos definir en la clase Animal
el método dibuja() y el método imprime(),
y que Animal sea una clase abstracta o un interfaz.
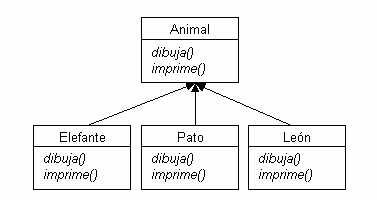
Figura 1.2.4.1 Ejemplo de interfaz y clase abstracta
Animal
tendríamos que implementar los métodos dibuja()
e imprime(). Las clases hijas no tendrían por
qué implementar los métodos, a no ser que quieran
adaptarlos a sus propias necesidades.La especificación en Java es como sigue.
Si queremos definir una clase (por ejemplo, Animal),
como clase abstracta y otra clase (por ejemplo, Pato) que
hereda de esta clase, debemos declararlo así:
public abstract class Animal |
public class Pato extends Animal |
Si en lugar de definir Animal como clase abstracta, lo
definimos como interfaz, debemos declarar que la
clase Pato implementa la interfaz, y
debemos escribir el código de esa implementación en la
clase Pato:
public interface Animal |
public class Pato implements Animal |
La diferencia fundamental es que la clase Pato puede
implementar más de un interfaz, mientras que sólo es
posible heredar de una clase padre (en Java no existe la herencia
múltiple):
public class Pato implements Animal, Volador
{
void dibujar() { codigo; } // viene de la interfaz Animal
void imprimir() { codigo; } // viene de la interfaz Animal
void vuela() { codigo; } // viene de la interfaz Volador
}
random() de la clase java.lang.Math).
Para ejecutar un método estático de una clase debemos
usar la misma sintaxis que para ejecutar un método de un objeto
(el operador punto "."), pero ahora sobre la propia clase, en lugar de
sobre un objeto:hipotenusa = Math.sqrt (Math.pow(cat1,2), Math.pow(cateto2,2));Si se define static en un campo, estamos declarando una variable de clase, accesible por todos los objetos (en el caso de ser public) o sólo por los objetos de la clase (en el caso de ser private).
MiClase1_1
de la siguiente forma:package paquete1.subpaquete1;haremos que la clase MiClase1_1 pertenezca al subpaquete subpaquete1 del paquete paquete1. Para utilizar las clases de un paquete utilizamos import:
public class MiClase1_1
...
import java.Date;Para importar todas las clases del paquete se utiliza el asterisco * (aunque no vayamos a usarlas todas, si utilizamos varias de ellas puede ser útil simplificar con un asterisco). Si sólo queremos importar una o algunas pocas, se pone un import por cada una, terminando el paquete con el nombre de la clase en lugar del asterisco (como pasa con Date en el ejemplo).
import paquete1.subpaquete1.*;
import java.awt.*;
Al poner import podemos utilizar el nombre corto de la clase. Es decir, si ponemos:
import java.Date;
import java.util.*;
Podemos hacer referencia a un objeto Date o a un objeto Vector (una clase del paquete java.util) con:
Date d = ...
Vector v = ...
Si no pusiéramos los import, deberíamos hacer referencia a los objetos con:
java.Date d = ...
java.util.Vector v = ...
Es decir, cada vez que queramos poner el nombre de la clase, deberíamos colocar todo el nombre, con los paquetes y subpaquetes.
Tipos de datos
Se tienen los siguientes tipos de datos simples. Además, se pueden crear complejos, todos los cuales serán subtipos de Object
|
|
|
|
|
| byte | 8 bits, complemento a 2 | Entero de 1 byte |
|
| short | 16 bits, complemento a 2 | Entero corto |
|
| int | 32 bits, complemento a 2 | Entero |
|
| long | 64 bits, complemento a 2 | Entero largo |
|
| float | 32 bits, IEEE 754 | Real simple precisión |
|
| double | 64 bits, IEEE 754 | Real doble precisión |
|
| char | 16 bits, carácter | Carácter simple |
|
| String | Cadena de caracteres |
|
|
| boolean | true / false | verdadero / falso |
|
Arrays
Se definen arrays o conjuntos de elementos de forma similar a como se hace en C. Hay 2 métodos:
int a[] = new int [10];No pueden crearse arrays estáticos en tiempo de compilación (int a[8];), ni rellenar un array sin definir previamente su tamaño con el operador new. La función miembro length se puede utilizar para conocer la longitud del array:
String s[] = {"Hola", "Adios"};
int a [][] = new int [10] [3];Los arrays empiezan a numerarse desde 0, hasta el tope definido menos uno (como en C).
a.length; // Devolvería 10
a[0].length; // Devolvería 3
Identificadores
Nombran variables, funciones, clases y objetos. Comienzan por una letra, carácter de subrayado ‘_’ o símbolo ‘$’. El resto de caracteres pueden ser letras o dígitos (o ’_’). Se distinguen mayúsculas de minúsculas, y no hay longitud máxima. Las variables en Java sólo son válidas desde el punto donde se declaran hasta el final de la sentencia compuesta (las llaves) que la engloba. No se puede declarar una variable con igual nombre que una de ámbito exterior.
En Java se tiene también un término NULL, pero si bien el de C es con mayúsculas (NULL), éste es con minúsculas (null):
String a = null;
...
if (a == null)...
Referencias
En Java no existen punteros, simplemente se crea otro objeto que referencie al que queremos "apuntar".
MiClase mc = new MiClase(); |
mc2 y mc apuntan a la misma variable (al cambiar una cambiará la otra). |
MiClase mc = new MiClase(); |
Tendremos dos objetos apuntando a elementos diferentes en memoria. |
Comentarios
// comentarios para una sola líneaOperadores
/* comentarios de
una o más líneas */
/** comentarios de documentación para javadoc,
de una o más líneas */
Se muestra una tabla con los operadores en orden de precedencia
|
|
|
|
|
|
|
Campo o método de objeto |
|
|
|
Referencia a elemento de array |
|
|
|
Agrupación de operaciones |
|
|
|
Autoincremento / Autodecremento de 1 unidad |
|
|
|
Negación / Complemento |
|
|
|
Indica si a es del tipo TipoDato |
|
|
|
Multiplicación, división y resto de división entera |
|
|
|
Suma y resta |
|
|
|
Desplazamiento de bits a izquierda y derecha |
|
|
|
Comparaciones (mayor, menor, igual, distinto...) |
|
|
|
AND, OR y XOR lógicas |
|
|
|
AND y OR condicionales |
|
|
|
Condicional: si a entonces b , si no c |
|
|
|
Asignación. a += b equivale a (a = a + b) |
Control de flujo
TOMA DE DECISIONES
Este tipo de sentencias definen el código que debe ejecutarse si se cumple una determinada condición. Se dispone de sentencias if y de sentencias switch:
|
|
|
if (condicion1) {
|
if |
switch (condicion) {
|
switch (a) {
|
BUCLES
Para repetir un conjunto de sentencias durante un determinado número de iteraciones se tienen las sentencias for, while y do...while :
|
|
|
for(inicio;condicion; |
for (i=1;i<10;i++) |
while (condicion){
|
while (i < 10) {
|
do{
|
do {
|
SENTENCIAS DE RUPTURA
Se tienen las sentencias break (para terminar la ejecución de un bloque o saltar a una etiqueta), continue (para forzar una ejecución más de un bloque o saltar a una etiqueta) y return (para salir de una función devolviendo o sin devolver un valor):
public int miFuncion(int n)
{
int i = 0;
while (i < n)
{
i++;
if (i > 10)
// Sale del while
break;
if (i < 5)
// Fuerza una iteracion mas
continue;
}
// Devuelve lo que valga i al llegar aquí
return i;
}
Veamos ahora algunos ejemplos de programas en Java.
Eclipse es una herramienta que permite integrar diferentes tipos de aplicaciones. La aplicación principal es el JDT (Java Development Tooling), un IDE para crear programas en Java. Otras aplicaciones, que no vienen con la distribución estándar de Eclipse, se añaden al mismo en forma de plugins, y son reconocidos automáticamente por la plataforma.
Además, Eclipse tiene su propio mecanismo de gestión de recursos. Los recursos son ficheros en el disco duro, que se encuentran alojados en un espacio de trabajo (workspace), un directorio especial en el sistema. Así, si una aplicación de Eclipse modifica un recurso, dicho cambio es notificado al resto de aplicaciones de Eclipse, para que lo tengan en cuenta.
Para instalar Eclipse se requiere:
Para la instalación, se siguen los pasos:
eclipse –vm ruta_jdk_jre
Para arrancar Eclipse se tiene el ejecutable eclipse.exe o eclipse.sh en ECLIPSE_HOME. La pantalla inicial de Eclipse aparecerá tras unos segundos:
Figura 1.4.1.1 Pantalla inicial de Eclipse
Veremos las opciones principales con detalle más adelante. De los menús, entre otros, pueden resultar interesantes:
El usuario trabaja con Eclipse mediante el entorno gráfico que se le presenta. Según la perspectiva que elija, se establecerá la apariencia de dicho entorno. Entendemos por perspectiva una colección de vistas y editores, con sus correspondientes acciones especiales en menús y barras de herramientas. Algunas vistas muestran información especial sobre los recursos, y dependiendo de las mismas, en ocasiones sólo se mostrarán algunas partes o relaciones internas de dichos recursos. Un editor trabaja directamente sobre un recurso, y sólo cuando grabe los cambios sobre el recurso se notificará al resto de aplicaciones de Eclipse sobre estos cambios. Las vistas especiales se pueden conectar a editores (no a recursos), por ejemplo, la vista de estructura (outline view) se puede conectar al editor Java. De este modo, una de las características importantes de Eclipse es la flexibilidad para combinar vistas y editores.
Si queremos abrir una determinada perspectiva, vamos a Window -> Open Perspective. Eligiendo luego Other podemos elegir entre todas las perspectivas disponibles:

Figura 1.4.2.1 Abrir una perspectiva en Eclipse
Para añadir vistas a una perspectiva, primero abrimos la perspectiva, y luego vamos a Window -> Show View y elegimos la que queramos cargar:
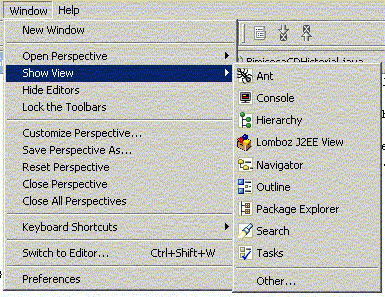
Figura 1.4.2.2 Elegir una vista en una perspectiva
Apariencia
Arrastrando la barra de título de una vista o editor, podemos moverlo a otro lugar de la ventana (lo podremos colocar en las zonas donde el cursor del ratón cambie a una flecha negra), o tabularlo con otras vistas o editores (arrastrando hasta el título de dicha vista o editor, el cursor cambia de aspecto, y se ve como una lista de carpetas, soltando ahí la vista o editor que arrastramos, se tabula con la(s) que hay donde hemos soltado).
Desde el menú Window - Preferences podemos establecer opciones de configuración de los distintos aspectos de Eclipse:
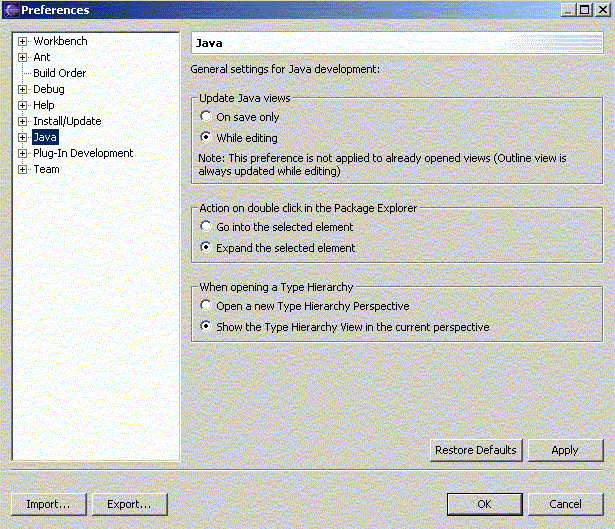
Figura 1.4.3.1 Configuración general de Eclipse
Podemos elegir entre tener nuestro código fuente en el mismo lugar que nuestras clases objeto compiladas, o bien elegir directorios diferentes para fuentes y objetos. Para ello tenemos, dentro del menú de configuración anterior, la opción Java - New Project. En el cuadro Source and output folder podremos indicar si queremos colocarlo todo junto (marcando Project) o indicar un directorio para cada cosa (marcando Folders, y eligiendo el subdirectorio adecuado para cada uno):
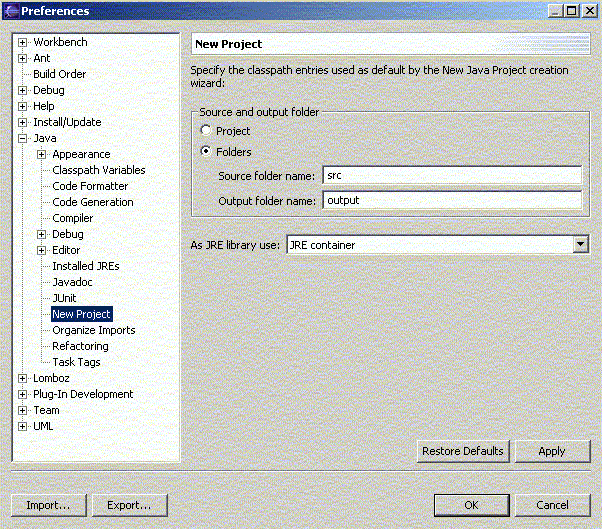
Figura 1.4.3.2. Establecimiento de los directorios fuente y objeto
Para cambiar el compilador a una versión concreta de Java, elegimos la opción de Java y luego Compiler. Pulsamos en la pestaña Compliance and Classfiles y elegimos la opción 1.4 (o la que sea) de la lista Compiler compliance level:
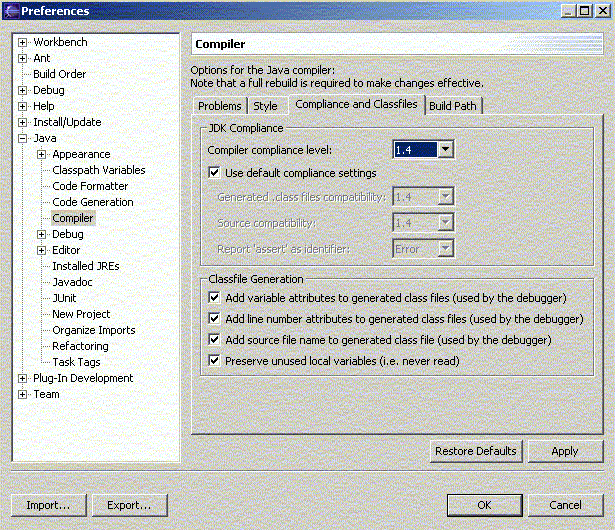
Figura 1.4.3.3 Establecer la versión del compilador
También podemos utilizar JDK en lugar de JRE para ejecutar los programas. Para ello vamos a Java - Installed JREs, elegimos la línea Standard VM y pulsamos en Edit o en Add, según si queremos modificar el que haya establecido, o añadir nuevas opciones.
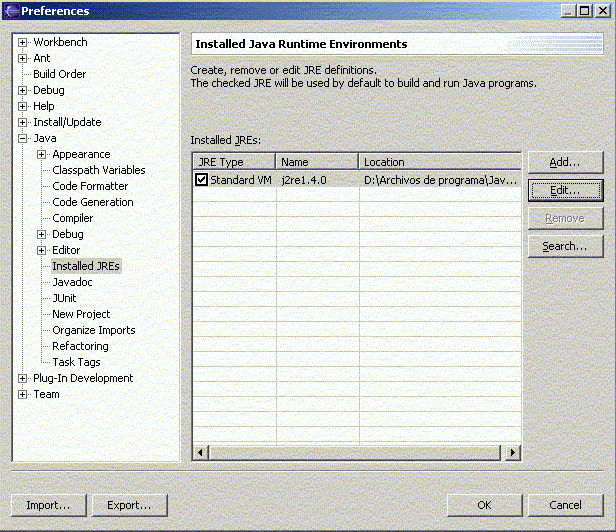
Figura 1.4.3.4 Establecer el compilador, o añadir nuevos
Se nos abre un cuadro de diálogo para editar valores. Pulsando en Browse elegimos el directorio de JDK (por ejemplo, C:\j2sdk1.4.0).
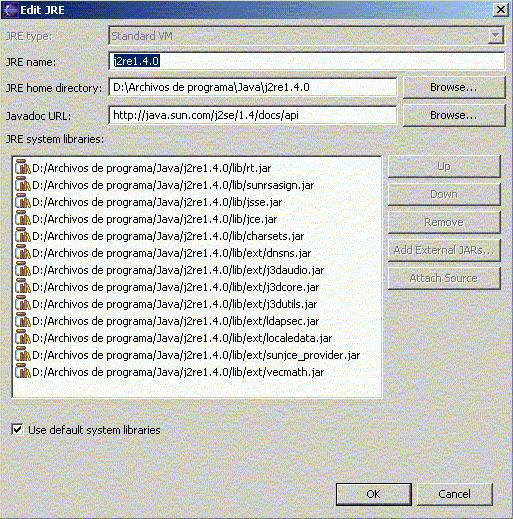
Figura 1.4.3.5 Editar los valores de JDK o JRE
Podemos añadir variables de entorno en Eclipse, cada una conteniendo un directorio, fichero JAR o fichero ZIP. Para añadir variables vamos a la opción Java - Classpath Variables.
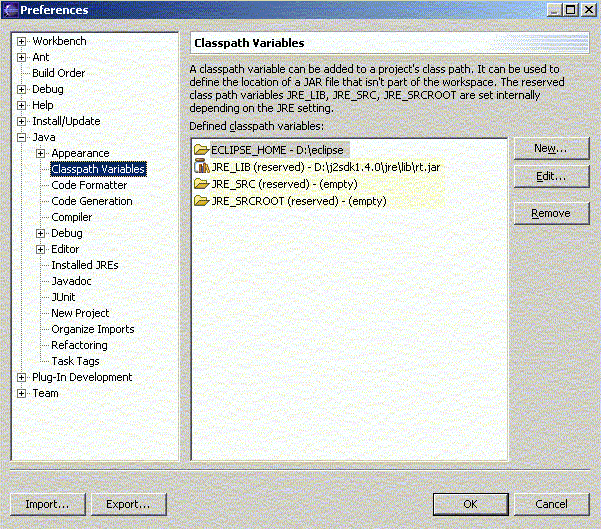
Figura 1.4.3.6 Variables de classpath
Pulsamos el botón de New para añadir una nueva, y le damos un nombre, y elegimos el fichero JAR o ZIP (pulsando en File) o el directorio (pulsando en Folder).
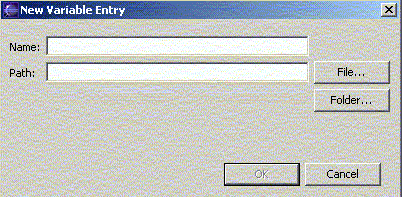
Figura 1.4.3.7 Establecer el valor de la nueva variable
Por defecto el espacio de trabajo (workspace) para Eclipse es el directorio ECLIPSE_HOME/workspace. Podemos elegir un directorio arbitrario lanzando eclipse con una opción –data que indique cuál es ese directorio, por ejemplo:
eclipse –data C:\misTrabajos
También podemos crear nuestros proyectos y trabajos fuera del workspace si queremos, podemos tomarlo simplemente como un directorio opcional donde organizar nuestros proyectos.
Para crear un nuevo proyecto Java vamos a File -> New -> Project. Después en el cuadro que aparece elegimos el proyecto que sea (normalmente, un Java Project en el grupo Java):
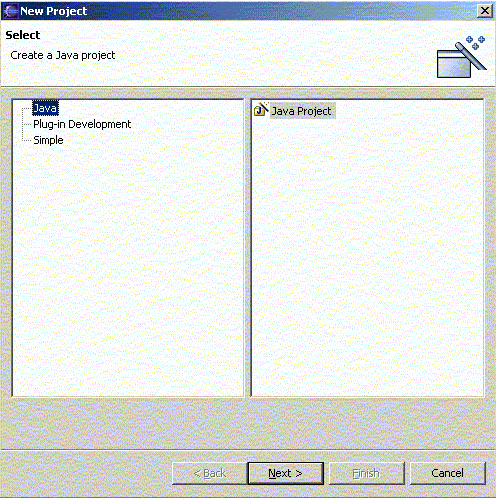
Figura 1.4.4.1 Crear un nuevo proyecto en Eclipse
Después nos aparece otra ventana para elegir el nombre del proyecto, y dónde guardarlo (por defecto en el espacio de trabajo de Eclipse):
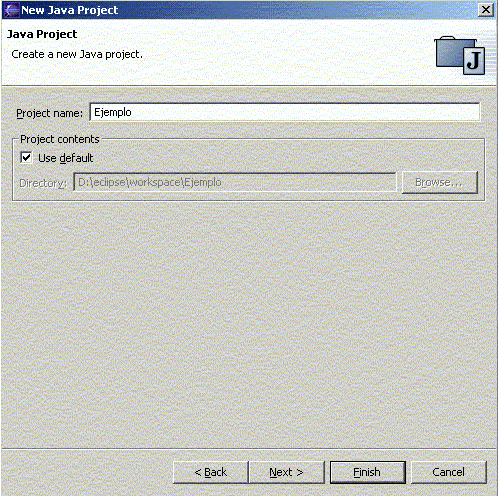
Figura 1.4.4.2 Asignar nombre y ubicación al proyecto
Si pulsamos en Next podemos especificar otras opciones del proyecto en otro panel:
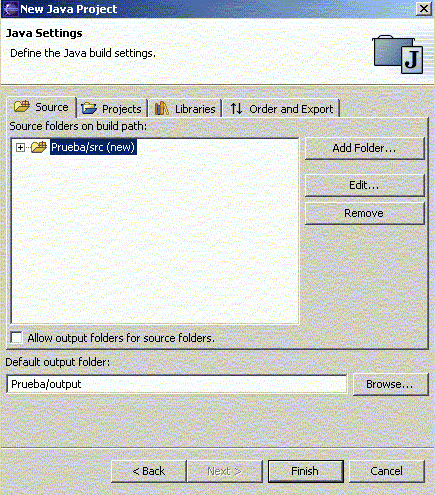
Figura 1.4.4.3 Otras opciones para el proyecto
donde podremos indicar qué carpetas tienen el código del proyecto (Source), el directorio donde sacar las clases compiladas (Default output folder), el classpath (Libraries), etc. Una vez rellenas las opciones a nuestro gusto, ya tendremos el proyecto creado:
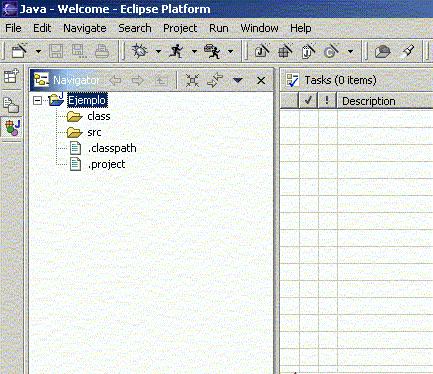
Figura 1.4.4.4 Proyecto creado
Desde el buildpath de un proyecto se establecen las clases que debe compilar, los recursos (directorios, ficheros JAR, etc) que debe tener en cuenta para compilarlo, etc. Para establecerlo, hacemos click con el botón derecho sobre el proyecto, y vamos a Properties.
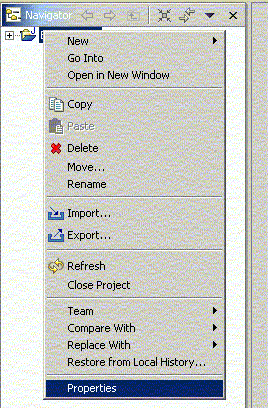
Figura 1.4.4.5 Establecer el buildpath de un proyecto
Nos aparecerá un cuadro con varias pestañas:
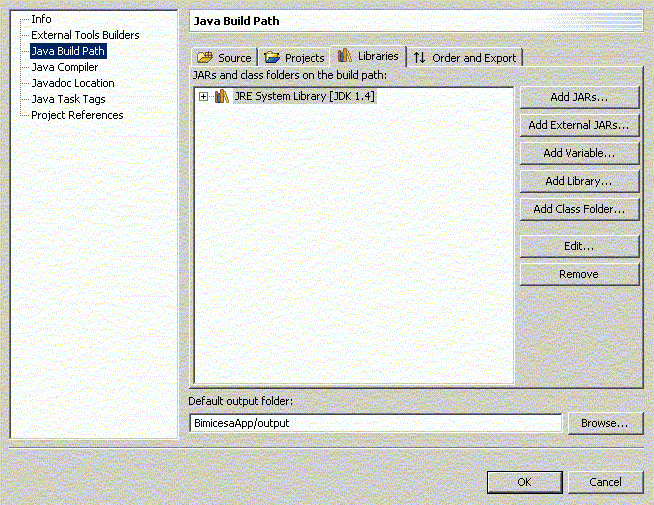
Figura 1.4.4.6 Opciones del buildpath
El editor de código de Eclipse es bastante sencillo de usar, y dispone de una ayuda contextual que permite autocompletar las sentencias de código que vayamos escribiendo. Por ejemplo, si escribimos un nombre de campo, tras el punto nos mostrará las opciones que podemos escribir después:
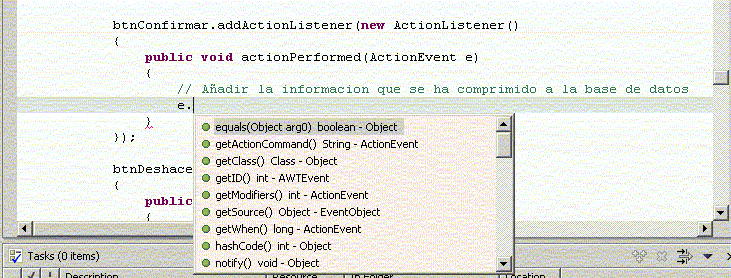
Figura 1.4.6.1 Editor de código de Eclipse
Para instalar nuevos plugins, simplemente hay que copiarlos en el directorio ECLIPSE_HOME/plugins. Después habrá que reiniciar Eclipse para que pueda tomar los nuevos plugins instalados.
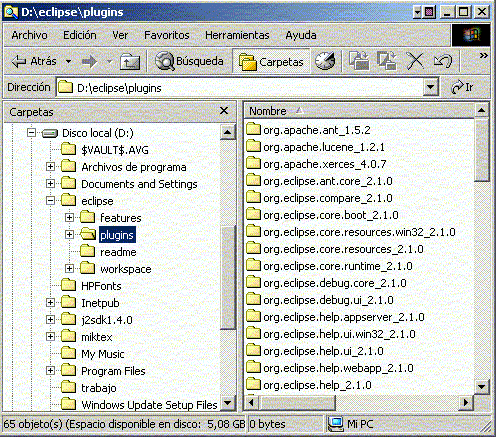
Figura 1.4.7.1 Plugins en Eclipse
Existen gran cantidad de plugins desarrollados. Por ejemplo el plugin EclipseUML de Omondo para realizar diseño UML (diagramas de clases, de paquetes, etc) en un determinado proyecto, o el plugin Lomboz para realizar proyectos J2EE.
JCreator es una herramienta que no da tantas posibilidades como Eclipse, pero permite editar, compilar y ejecutar código Java. Su apariencia es la siguiente:
Figura 1.5.1.1 Ventana principal de JCreator
En la parte superior están los menús y barras de herramientas. A la izquierda se tienen las clases y proyectos que se tengan, y los campos y métodos de la clase seleccionada. La zona derecha es el editor de texto, donde se verá el código de las clases que se tengan. Abajo se muestran los resultados.
Kawa es una herramienta muy parecida a JCreator en cuanto a funcionalidades. Su apariencia es la siguiente:
Figura 1.5.1.2 Ventana principal de Kawa
En la parte superior están los menús y barras de herramientas. A la izquierda se tienen las clases y proyectos que se tengan. La zona derecha es el editor de texto, y abajo se muestran los resultados.
Un applet es una aplicación normalmente corta (aunque no hay límite de tamaño), cuya principal funcionalidad es ser accesible a un servidor Internet (una aplicación que pueda visualizarse desde un navegador). Para ello se carga la clase del applet en un fichero HTML, mediante código como:
<HTML>Aquí tenemos un ejemplo:
<BODY>
...
<APPLET CODE = nombre_prog.class WIDTH = 300 HEIGHT = 100>
</APPLET>
...
</BODY>
</HTML>
El appletviewer es un navegador mínimo proporcionado con Java, que espera como argumento el fichero HTML donde está el applet que se cargará:
appletviewer nombre_prog.html
La plataforma Java nos proporciona un amplio conjunto de clases dentro del que podemos encontrar tipos de datos que nos resultarán muy útiles para realizar la programación de aplicaciones en Java. Estos tipos de datos nos ayudarán a generar código más limpio de una forma sencilla.
Se proporcionan una serie de operadores para acceder a los elementos de estos tipos de datos. Decimos que dichos operadores son polimórficos, ya que un mismo operador se puede emplear para acceder a distintos tipos de datos. Por ejemplo, un operador add utilizado para añadir un elemento, podrá ser empleado tanto si estamos trabajando con una lista enlazada, con un array, o con un conjunto por ejemplo.
Este polimorfismo se debe a la definición de interfaces que deben implementar los distintos tipos de datos. Siempre que el tipo de datos contenga una colección de elementos, implementará la interfaz Collection. Esta interfaz proporciona métodos para acceder a la colección de elementos, que podremos utilizar para cualquier tipo de datos que sea una colección de elementos, independientemente de su implementación concreta.
Podemos encontrar los siguientes elementos dentro del marco de colecciones de Java:
Antes de ver los tipos de datos vamos a ver dos elementos utilizados comunmente en Java para acceder a colecciones de datos.
Las enumeraciones, definidas mediante la interfaz Enumeration, nos permiten consultar los elementos que contiene una colección de datos. Muchos métodos de clases Java que deben devolver múltiples valores, lo que hacen es devolvernos una enumeración que podremos consultar mediante los métodos que ofrece dicha interfaz.
La enumeración irá recorriendo secuencialmente los elementos de la colección. Para leer cada elemento de la enumeración deberemos llamar al método:
Object item = enum.nextElement();
Que nos proporcionará en cada momento el siguiente elemento de la enumeración a leer. Además necesitaremos saber si quedan elementos por leer, para ello tenemos el método:
enum.hasMoreElements()
Normalmente, el bucle para la lectura de una enumeración será el siguiente:
while (enum.hasMoreElements()) {
Object item = enum.nextElement();
// Hacer algo con el item leido
}
Vemos como en este bucle se van leyendo y procesando elementos de la enumeración uno a uno mientras queden elementos por leer en ella.
Otro elemento para acceder a los datos de una colección son los iteradores. La diferencia está en que los iteradores además de leer los datos nos permitirán eliminarlos de la colección. Los iteradores se definen mediante la interfaz Iterator, que proporciona de forma análoga a la enumeración el método:
Object item = iter.next();
Que nos devuelve el siguiente elemento a leer por el iterador, y para saber si quedan más elementos que leer tenemos el método:
iter.hasNext()
Además, podemos borrar el último elemento que hayamos leido. Para ello tendremos el método:
iter.remove();
Por ejemplo, podemos recorrer todos los elementos de una colección utilizando un iterador y eliminar aquellos que cumplan ciertas condiciones:
while (iter.hasNext())
{
Object item = iter.next();
if(condicion_borrado(item))
iter.remove();
}
Las enumeraciones y los iteradores no son tipos de datos, sino elementos que nos servirán para acceder a los elementos dentro de los tipos de datos que veremos a continuación.
Las colecciones representan grupos de objetos, denominados elementos. Podemos encontrar diversos tipos de colecciones, según si sus elementos están ordenados, o si permitimos repetición de elementos o no.
Es el tipo más genérico en cuanto a que se refiere a cualquier tipo que contenga un grupo de elementos. Viene definido por la interfaz Collection, de la cual heredará cada subtipo específico. En esta interfaz encontramos una serie de métodos que nos servirán para acceder a los elementos de cualquier colección de datos, sea del tipo que sea. Estos métodos generales son:
boolean add(Object o)
Añade un elemento (objeto) a la colección. Nos devuelve true si tras añadir el elemento la colección ha cambiado, es decir, el elemento se ha añadido correctamente, o false en caso contrario.
void clear()
Elimina todos los elementos de la colección.
boolean contains(Object o)
Indica si la colección contiene el elemento (objeto) indicado.
boolean isEmpty()
Indica si la colección está vacía (no tiene ningún elemento).
Iterator iterator()
Proporciona un iterador para acceder a los elementos de la colección.
boolean remove(Object o)
Elimina un determinado elemento (objeto) de la colección, devolviendo true si dicho elemento estaba contenido en la colección, y false en caso contrario.
int size()
Nos devuelve el número de elementos que contiene la colección.
Object [] toArray()
Nos devuelve la colección de elementos como un array de objetos. Si sabemos de antemano que los objetos de la colección son todos de un determinado tipo (como por ejemplo de tipo String) podremos obtenerlos en un array del tipo adecuado, en lugar de usar un array de objetos genéricos. En este caso NO podremos hacer una conversión cast descendente de array de objetos a array de un tipo más concreto, ya que el array se habrá instanciado simplemente como array de objetos:
String [] cadenas = (String []) coleccion.toArray();
// Esto no se puede hacer!!!
Lo que si podemos hacer es instanciar nosotros un array del tipo adecuado y hacer una conversión cast ascendente (de tipo concreto a array de objetos), y utilizar el siguiente método:
String [] cadenas = new String[coleccion.size()];
coleccion.toArray(cadenas); // Esto si que funcionará
Esta interfaz es muy genérica, y por lo tanto no hay ningún tipo de datos que la implemente directamente, sino que implementarán subtipos de ellas. A continuación veremos los subtipos más comunes.
Este tipo de colección se refiere a listas en las que los elementos de la colección tienen un orden, existe una secuencia de elementos. En ellas cada elemento estará en una determinada posición (índice) de la lista.
Las listas vienen definidas en la interfaz List, que además de los métodos generales de las colecciones, nos ofrece los siguientes para trabajar con los índices:
void add(int indice, Object obj)
Inserta un elemento (objeto) en la posición de la lista dada por el índice indicado.
Object get(int indice)
Obtiene el elemento (objeto) de la posición de la lista dada por el índice indicado.
int indexOf(Object obj)
Nos dice cual es el índice de dicho elemento (objeto) dentro de la lista. Nos devuelve -1 si el objeto no se encuentra en la lista.
Object remove(int indice)
Elimina el elemento que se encuentre en la posición de la lista indicada mediante dicho índice, devolviéndonos el objeto eliminado.
Object set(int indice, Object obj)
Establece el elemento de la lista en la posición dada por el índice al objeto indicado, sobrescribiendo el objeto que hubiera anteriormente en dicha posición. Nos devolverá el elemento que había previamente en dicha posición.
Podemos encontrar diferentes implementaciones de listas de elementos en Java:
ArrayList
Implementa una lista de elementos mediante un array de tamaño variable. Conforme se añaden elementos el tamaño del array irá creciendo si es necesario. El array tendrá una capacidad inicial, y en el momento en el que se rebase dicha capacidad, se aumentará el tamaño del array.
Las operaciones de añadir un elemento al final del array (add), y de establecer u obtener el elemento en una determinada posición (get/set) tienen un coste temporal constante. Las inserciones y borrados tienen un coste lineal O(n), donde n es el número de elementos del array.
Hemos de destacar que la implementación de ArrayList no está sincronizada, es decir, si múltiples hilos acceden a un mismo ArrayList concurrentemente podriamos tener problemas en la consistencia de los datos. Por lo tanto, deberemos tener en cuenta cuando usemos este tipo de datos que debemos controlar la concurrencia de acceso. También podemos hacer que sea sincronizado como veremos más adelante.
Vector
El Vector es una implementación similar al ArrayList, con la diferencia de que el Vector si que está sincronizado. Este es un caso especial, ya que la implementación básica del resto de tipos de datos no está sincronizada.
Esta clase existe desde las primeras versiones de Java, en las que no existía el marco de las colecciones descrito anteriormente. En las últimas versiones el Vector se ha acomodado a este marco implementando la interfaz List.
Sin embargo, si trabajamos con versiones previas de JDK, hemos de tener en cuenta que dicha interfaz no existía, y por lo tanto esta versión previa del vector no contará con los métodos definidos en ella. Los métodos propios del vector para acceder a su contenido, que han existido desde las primeras versiones, son los siguientes:
void addElement(Object obj)
Añade un elemento al final del vector.
Object elementAt(int indice)
Devuelve el elemento de la posición del vector indicada por el índice.
void insertElementAt(Object obj, int indice)
Inserta un elemento en la posición indicada.
boolean removeElement(Object obj)
Elimina el elemento indicado del vector, devolviendo true si dicho elemento estaba contenido en el vector, y false en caso contrario.
void removeElementAt(int indice)
Elimina el elemento de la posición indicada en el índice.
void setElementAt(Object obj, int indice)
Sobrescribe el elemento de la posición indicada con el objeto especificado.
int size()
Devuelve el número de elementos del vector.
Por lo tanto, si programamos para versiones antiguas de la máquina virtual Java, será recomendable utilizar estos métodos para asegurarnos de que nuestro programa funcione. Esto será importante en la programación de Applets, ya que la máquina virtual incluida en muchos navegadores corresponde a versiones antiguas.
Sobre el vector se construye el tipo pila (Stack), que apoyándose en el tipo vector ofrece métodos para trabajar con dicho vector como si se tratase de una pila, apilando y desapilando elementos (operaciones push y pop respectivamente). La clase Stack hereda de Vector, por lo que en realidad será un vector que ofrece métodos adicionales para trabajar con él como si fuese una pila.
LinkedList
En este caso se implementa la lista mediante una lista doblemente enlazada. Por lo tanto, el coste temporal de las operaciones será el de este tipo de listas. Cuando realicemos inserciones, borrados o lecturas en los extremos inicial o final de la lista el tiempo será constante, mientras que para cualquier operación en la que necesitemos localizar un determinado índice dentro de la lista deberemos recorrer la lista de inicio a fin, por lo que el coste será lineal con el tamaño de la lista O(n), siendo n el tamaño de la lista.
Para aprovechar las ventajas que tenemos en el coste temporal al trabajar con los extremos de la lista, se proporcionan métodos propios para acceder a ellos en tiempo constante:
void addFirst(Object obj) / void addLast(Object obj)
Añade el objeto indicado al principio / final de la lista respectivamente.
Object getFirst() / Object getLast()
Obtiene el primer / último objeto de la lista respectivamente.
Object removeFirst() / Object removeLast()
Extrae el primer / último elemento de la lista respectivamente, devolviéndonos dicho objeto y eliminándolo de la lista.
Hemos de destacar que estos métodos nos permitirán trabajar con la lista como si se tratase de una pila o de una cola. En el caso de la pila realizaremos la inserción y la extracción de elementos por el mismo extremo, mientras que para la cola insertaremos por un extremo y extraeremos por el otro.
Los conjuntos son grupos de elementos en los que no encontramos ningún elemento repetido. Consideramos que un elemento está repetido si tenemos dos objetos o1 y o2 iguales, comparandolos mediante el operador o1.equals(o2). De esta forma, si el objeto a insertar en el conjunto estuviese repetido, no nos dejará insertarlo. Recordemos que el método add devolvía un valor booleano, que servirá para este caso, devolviendonos true si el elemento a añadir no estaba en el conjunto y ha sido añadido, o false si el elemento ya se encontraba dentro del conjunto. Un conjunto podrá contener a lo sumo un elemento null.
Los conjuntos se definen en la interfaz Set, a partir de la cuál se construyen diferentes implementaciones:
HashSet
Los objetos se almacenan en una tabla de dispersión (hash). El coste de las operaciones básicas (inserción, borrado, búsqueda) se realizan en tiempo constante siempre que los elementos se hayan dispersado de forma adecuada. La iteración a través de sus elementos es más costosa, ya que necesitará recorrer todas las entradas de la tabla de dispersión, lo que hará que el coste esté en función tanto del número de elementos insertados en el conjunto como del número de entradas de la tabla. El orden de iteración puede diferir del orden en el que se insertaron los elementos.
LinkedHashSet
Es similar a la anterior pero la tabla de dispersión es doblemente enlazada. Los elementos que se inserten tendrán enlaces entre ellos. Por lo tanto, las operaciones básicas seguirán teniendo coste constante, con la carga adicional que supone tener que gestionar los enlaces. Sin embargo habrá una mejora en la iteración, ya que al establecerse enlaces entre los elementos no tendremos que recorrer todas las entradas de la tabla, el coste sólo estará en función del número de elementos insertados. En este caso, al haber enlaces entre los elementos, estos enlaces definirán el orden en el que se insertaron en el conjunto, por lo que el orden de iteración será el mismo orden en el que se insertaron.
TreeSet
Utiliza un árbol para el almacenamiento de los elementos. Por lo tanto, el coste para realizar las operaciones básicas será logarítmico con el número de elementos que tenga el conjunto O(log n).
Aunque muchas veces se hable de los mapas como una colección, en realidad no lo son, ya que no heredan de la interfaz Collection.
Los mapas se definen en la interfaz Map. Un mapa es un objeto que relaciona una clave (key) con un valor. Contendrá un conjunto de claves, y a cada clave se le asociará un determinado valor. En versiones anteriores este mapeado entre claves y valores lo hacía la clase Dictionary, que ha quedado obsoleta. Tanto la clave como el valor puede ser cualquier objeto.
Los métodos básicos para trabajar con estos elementos son los siguientes:
Object get(Object clave)
Nos devuelve el valor asociado a la clave indicada
Object put(Object clave, Object valor)
Inserta una nueva clave con el valor especificado. Nos devuelve el valor que tenía antes dicha clave, o null si la clave no estaba en la tabla todavía.
Object remove(Object clave)
Elimina una clave, devolviendonos el valor que tenía dicha clave.
Set keySet()
Nos devuelve el conjunto de claves registradas
int size()
Nos devuelve el número de parejas (clave,valor) registradas.
Encontramos distintas implementaciones de los mapas:
HashMap
Utiliza una tabla de dispersión para almacenar la información del mapa. Las operaciones básicas (get y put) se harán en tiempo constante siempre que se dispersen adecuadamente los elementos. Es coste de la iteración dependerá del número de entradas de la tabla y del número de elementos del mapa. No se garantiza que se respete el orden de las claves.
TreeMap
Utiliza un árbol rojo-negro para implementar el mapa. El coste de las operaciones básicas será logarítmico con el número de elementos del mapa O(log n). En este caso los elementos se encontrarán ordenados por orden ascendente de clave.
Hashtable
Es una implementación similar a HashMap, pero con alguna diferencia. Mientras las anteriores implementaciones no están sincronizadas, esta si que lo está. Además en esta implementación, al contrario que las anteriores, no se permitirán claves nulas (null). Este objeto extiende la obsoleta clase Dictionary, ya que viene de versiones más antiguas de JDK. Ofrece otros métodos además de los anteriores, como por ejemplo el siguiente:
Enumeration keys()
Este método nos devolverá una enumeración de todas las claves registradas en la tabla.
Como hemos comentado anteriormente, además de las interfaces y las implementaciones de los tipos de datos descritos en los apartados previos, el marco de colecciones nos ofrece una serie de algoritmos utiles cuando trabajamos con estos tipos de datos, especialmente para las listas.
Estos algoritmos los podemos encontrar implementados como métodos estáticos en la clase Collections. En ella encontramos métodos para la ordenación de listas (sort), para la búsqueda binaria de elementos dentro de una lista (binarySearch) y otras operaciones que nos serán de gran utilidad cuando trabajemos con colecciones de elementos.
A parte de los algoritmos comentados en el apartado anterior, la clase Collections aporta otros métodos para cambiar ciertas propiedades de las listas. Estos métodos nos proporcionan los denominados wrappers de los distintos tipos de colecciones. Estos wrappers son objetos que 'envuelven' al objeto de nuestra colección, pudiendo de esta forma hacer que la colección esté sincronizada, o que la colección pase a ser de solo lectura.
Como dijimos anteriormente, todos los tipos de colecciones no están sincronizados, excepto el Vector que es un caso especial. Al no estar sincronizados, si múltiples hilos utilizan la colección concurrentemente, podrán estar ejecutándose simultáneamente varios métodos de una misma colección que realicen diferentes operaciones sobre ella. Esto puede provocar inconsistencias en los datos. A continuación veremos un posible ejemplo de inconsistencia que se podría producir:
Podemos ver que haciendo una llamada a letras.remove("C"), al final se ha eliminado el objeto "D", lo cual produce una inconsistencia de los datos con las operaciones realizadas, debido al acceso concurrente.
Este problema lo evitaremos sincronizando la colección. Cuando una colección está sincronizada, hasta que no termine de realizarse una operación (inserciones, borrados, etc), no se podrá ejecutar otra, lo cual evitará estos problemas.
Podemos conseguir que las operaciones se ejecuten de forma sincronizada envolviendo nuestro objeto de la colección con un wrapper, que será un objeto que utilice internamente nuestra colección encargándose de realizar la sincronización cuando llamemos a sus métodos. Para obtener estos wrappers utilizaremos los siguientes métodos estáticos de Collections:
Collection synchronizedCollection(Collection c)
List synchronizedList(List l)
Set synchronizedSet(Set s)
Map synchronizedMap(Map m)
SortedSet synchronizedSortedSet(SortedSet ss)
SortedMap synchronizedSortedMap(SortedMap sm)
Como vemos tenemos un método para envolver cada tipo de datos. Nos devolverá un objeto con la misma interfaz, por lo que podremos trabajar con él de la misma forma, sin embargo la implementación interna estará sincronizada.
Podemos encontrar también una serie de wrappers para obtener versiones de sólo lectura de nuestras colecciones. Se obtienen con los siguientes métodos:
Collection unmodifiableCollection(Collection c)
List unmodifiableList(List l)
Set unmodifiableSet(Set s)
Map unmodifiableMap(Map m)
SortedSet unmodifiableSortedSet(SortedSet ss)
SortedMap unmodifiableSortedMap(SortedMap sm)
Hemos visto que en Java cualquier tipo de datos es un objeto, excepto los tipos de datos básicos: boolean, int, long, float, double, byte, short, char.
Cuando trabajamos con colecciones de datos los elementos que contienen éstas son siempre objetos, por lo que en un principio no podríamos insertar elementos de estos tipos básicos. Para hacer esto posible tenemos una serie de objetos que se encargarán de envolver a estos tipos básicos, permitiéndonos tratarlos como objetos y por lo tanto insertarlos como elementos de colecciones. Estos objetos son los llamados wrappers, y las clases en las que se definen tienen nombre similares al del tipo básico que encapsulan, con la diferencia de que comienzan con mayúscula: Boolean, Integer, Long, Float, Double, Byte, Short, Character.
Estas clases, además de servirnos para encapsular estos datos básicos en forma de objetos, nos proporcionan una serie de métodos e información útiles para trabajar con estos datos. Nos proporcionarán métodos por ejemplo para convertir cadenas a datos numéricos de distintos tipos y viceversa, así como información acerca del valor mínimo y máximo que se puede representar con cada tipo numérico.
En esta sección vamos a ver una serie de clases que conviene conocer ya que nos serán de gran utilidad para realizar nuestros programas:
Object
Esta es la clase base de todas las clases en Java, toda clase hereda en última instancia de la clase Object, por lo que los métodos que ofrece estarán disponibles en cualquier objeto Java, sea de la clase que sea.
En Java es importante distinguir claramente entre lo que es una variable, y lo que es un objeto. Las variables simplemente son referencias a objetos, mientras que los objetos son las entidades instanciadas en memoria que podrán ser manipulados mediante las referencias que tenemos a ellos (mediante variable que apunten a ellos) dentro de nuestro programa. Cuando hacemos lo siguiente:
new MiClase()
Se está instanciando en memoria un nuevo objeto de clase MiClase y nos devuelve una referencia a dicho objeto. Nosotros deberemos guardarnos dicha referencia en alguna variable con el fin de poder acceder al objeto creado desde nuestro programa:
MiClase mc = new MiClase();
Es importante declarar la referencia del tipo adecuado (en este caso tipo MiClase) para manipular el objeto, ya que el tipo de la referencia será el que indicará al compilador las operaciones que podremos realizar con dicho objeto. El tipo de esta referencia podrá ser tanto el mismo tipo del objeto al que vayamos a apuntar, o bien el de cualquier clase de la que herede o interfaz que implemente nuestro objeto. Por ejemplo, si MiClase se define de la siguiente forma:
public class MiClase extends Thread implements List {
...
}
Podremos hacer referencia a ella de diferentes formas:
MiClase mc = new MiClase();
Thread t = new MiClase();
List l = new MiClase();
Object o = new MiClase();
Esto es así ya que al heredar tanto de Thread como de Object, sabemos que el objeto tendrá todo lo que tienen estas clases más lo que añada MiClase, por lo que podrá comportarse como cualquiera de las clases anteriores. Lo mismo ocurre al implementar una interfaz, al forzar a que se implementen sus métodos podremos hacer referencia al objeto mediante la interfaz ya que sabemos que va a contener todos esos métodos. Siempre vamos a poder hacer esta asignación 'ascendente' a clases o interfaces de las que deriva nuestro objeto.
Si hacemos referencia a un objeto MiClase mediante una referencia Object por ejemplo, sólo podremos acceder a los métodos de Object, aunque el objeto contenga métodos adicionales definidos en MiClase. Si conocemos que nuestro objeto es de tipo MiClase, y queremos poder utilizarlo como tal, podremos hacer una asignación 'descendente' aplicando una conversión cast al tipo concreto de objeto:
Object o = new MiClase();
...
MiClase mc = (MiClase) o;
Si resultase que nuestro objeto no es de la clase a la que hacemos cast, ni hereda de ella ni la implementa, esta llamada resultará en un ClassCastException indicando que no podemos hacer referencia a dicho objeto mediante esa interfaz debido a que el objeto no la cumple, y por lo tanto podrán no estar disponibles los métodos que se definen en ella.
Una vez hemos visto la diferencia entre las variables (referencias) y objetos (entidades) vamos a ver como se hará la asignación y comparación de objetos. Si hiciesemos lo siguiente:
MiClase mc1 = new MiClase();
MiClase mc2 = mc1;
Puesto que hemos dicho que las variables simplemente son referencias a objetos, la asignación estará copiando una referencia, no el objeto. Es decir, tanto la variable mc1 como mc2 apuntarán a un mismo objeto.
Si lo que queremos es copiar un objeto, teniendo dos entidades independientes, deberemos invocar el método clone del objeto a copiar:
MiClase mc2 = (MiClase)mc1.clone();
El método clone es un método de la clase Object que estará disponible para cualquier objeto Java, y nos devuelve un Object genérico, ya que al ser un método que puede servir para cualquier objeto nos debe devolver la copia de este tipo. De él tendremos que hacer una conversión cast a la clase de la que se trate como hemos visto en el ejemplo.
Por otro lado, para la comparación, si hacemos lo siguiente:
mc1 == mc2
Estaremos comparando referencias, por lo que estaremos viendo si las dos referencias apuntan a un mismo objeto, y no si los objetos a los que apuntan son iguales. Para ver si los objetos son iguales, aunque sean entidades distintas, tenemos:
mc1.equals(mc2)
Este método también es propio de la clase Object, y será el que se utilice para comparar internamente los objetos.
Tanto clone como equals, deberán ser redefinidos en nuestras clases para adaptarse a éstas. Deberemos especificar dentro de ellos como se copia nuestro objeto y como se compara si son iguales:
public class Punto2D {
public int x, y;
...
public boolean equals(Object o) {
Punto2D p = (Punto2D)o;
// Compara objeto this con objeto p
return (x == p.x && y == p.y);
}
public Object clone() {
Punto2D p = new Punto2D();
// Construye nuevo objeto p
// copiando los atributos de this
p.x = x;
p.y = y;
return p;
}
Un último método interesante de la clase Object es toString. Este método nos devuelve una cadena (String) que representa dicho objeto. Por defecto nos dará un identificador del objeto, pero nosotros podemos sobrescribirla en nuestras propias clases para que genere la cadena que queramos. De esta manera podremos imprimir el objeto en forma de cadena de texto, mostrandose los datos con el formato que nosotros les hayamos dado en toString. Por ejemplo, si tenemos una clase Punto2D, sería buena idea hacer que su conversión a cadena muestre las coordenadas (x,y) del punto:
public class Punto2D {
public int x,y;
...
public String toString() {
String s = "(" + x + "," + y + ")";
return s;
}
}
Properties
Esta clase es un subtipo de Hastable, que se encarga de almacenar una serie de propiedades asociando un valor a cada una de ellas. Estas propiedades las podremos utilizar para registrar la configuración de nuestra aplicación. Además esta clase nos permite cargar o almacenar esta información en algún dispositivo, como puede ser en disco, de forma que sea persistente.
Puesto que hereda de Hashtable, podremos utilizar sus métodos, pero también aporta métodos propios para añadir propiedades:
Object setProperty(Object clave, Object valor)
Equivalente al método put.
Object getProperty(Object clave)
Equivalente al método get.
Object getProperty(Object clave, Object default)
Esta variante del método resulta útil cuando queremos que determinada propiedad devuelva algún valor por defecto si todavía no se le ha asignado ningún valor.
Además, como hemos dicho anteriormente, para hacer persistentes estas propiedades de nuestra aplicación, se proporcionan métodos para almacenarlas o leerlas de algún dispositivo de E/S:
void load(InputStream entrada)
Lee las propiedades del flujo de entrada proporcionado. Este flujo puede por ejemplo referirse a un fichero del que se leerán los datos.
void store(OutputStream salida, String cabecera)
Almacena las información de las propiedades escribiendolas en el flujo de salida especificado. Este flujo puede por ejemplo referirse a un fichero en disco, en el que se guardará nuestro conjunto de propiedades, pudiendo especificar una cadena que se pondrá como cabecera en el fichero, y que nos permite añadir algún comentario sobre dicho fichero.
System
Esta clase nos ofrece una serie de métodos y campos útiles del sistema. Esta clase no se debe instanciar, todos estos métodos y campos son estáticos.
Podemos encontrar los objetos que encapsulan la entrada, salida y salida de error estándar, así como métodos para redireccionarlas, que veremos con más detalle en el tema de entrada/salida.
También nos permite acceder al gestor de seguridad instalado, como veremos en el tema sobre seguridad.
Otros métodos útiles que encontramos son:
void exit(int estado)
Finaliza la ejecución de la aplicación, devolviendo un código de estado. Normalmente el código 0 significa que ha salido de forma normal, mientras que con otros códigos indicaremos que se ha producido algún error.
void gc()
Fuerza una llamada al colector de basura para limpiar la memoria. Esta es una operación costosa. Normalmente no lo llamaremos explicitamente, sino que dejaremos que Java lo invoque cuando sea necesario.
long currentTimeMillis()
Nos devuelve el tiempo medido en el número de milisegundos transcurridos desde el 1 de Enero de 1970 a las 0:00.
void arraycopy(Object fuente, int pos_fuente,
Object destino, int pos_dest, int n)
Copia n elementos del array fuente, desde la posición pos_fuente, al array destino a partir de la posición pos_dest.
Properties getProperties()
Devuelve un objeto Properties con las propiedades del sistema. En estas propiedades podremos encontrar la siguiente información:
| Clave | Contenido |
file.separator |
Separador entre directorios en la ruta de los ficheros. Por ejemplo "/" en UNIX. |
java.class.path |
Classpath de Java |
java.class.version |
Versión de las clases de Java |
java.home |
Directorio donde está instalado Java |
java.vendor |
Empresa desarrolladora de la implementación de la plataforma Java instalada |
java.vendor.url |
URL de la empresa |
java.version |
Versión de Java |
line.separator |
Separador de fin de líneas utilizado |
os.arch |
Arquitectura del sistema operativo |
os.name |
Nombre del sistema operativo |
os.version |
Versión del sistema operativo |
path.separator |
Separador entre los distintos elementos de una variable de entorno tipo PATH. Por ejemplo ":" |
user.dir |
Directorio actual |
user.home |
Directorio de inicio del usuario actual |
user.name |
Nombre de la cuenta del usuario actual |
Runtime
Toda aplicación Java tiene una instancia de la clase Runtime que se encargará de hacer de interfaz con el entorno en el que se está ejecutando. Para obtener este objeto debemos utilizar el siguiente método estático:
Runtime rt = Runtime.getRuntime();
Una de las operaciones que podremos realizar con este objeto, será ejecutar comandos como si nos encontrásemos en la línea de comandos del sistema operativo. Para ello utilizaremos el siguiente método:
rt.exec(comando);
De esta forma podremos invocar programas externos desde nuestra aplicación Java.
Math
La clase Math nos será de gran utilidad cuando necesitemos realizar operaciones matemáticas. Esta clase no necesita ser instanciada, ya que todos sus métodos son estáticos. Entre estos métodos podremos encontrar todas las operaciones matemáticas básicas que podamos necesitar, como logaritmos, exponenciales, funciones trigonométricas, generación de números aleatorios, conversión entre grados y radianes, etc. Además nos ofrece las constantes de los números PI y E.
Otras clases
Si miramos dentro del paquete java.util, podremos encontrar una serie de clases que nos podrán resultar útiles para determinadas aplicaciones.
Entre ellas tenemos la clase Calendar, que nos servirá cuando trabajemos con fechas y horas, para realizar operaciones con fechas, comparar fechas, u obtener distintas representaciones para mostrar la fecha en nuestra aplicación.
Encontramos también la clase Currency con información monetaria. La clase Locale almacena información sobre una determinada región del mundo, por lo que podremos utilizar esta clase junto a las anteriores para obtener la moneda de una determinada zona, o las diferencias horarias y de representación de fechas.
Hemos visto que Java nos permite escribir facilmente un código limpio y mantenible. Sin embargo, en muchas ocasiones además nos interesará que el código sea rápido en determinadas funciones críticas. A continuación damos una serie de consejos para optimizar el código Java: