1. Presentación
En esta primera sesión vamos a introducir brevemente la plataforma Java EE, la arquitectura del proyecto de aplicación web y vamos a presentar una guía de laboratorio en la que introduciremos y practicaremos algunos de los servicios y herramientas que utilizaremos durante el curso: servidores del curso, ordenadores de la UA, máquina virtual, IntelliJ y Bitbucket.
1.1. La plataforma Java EE
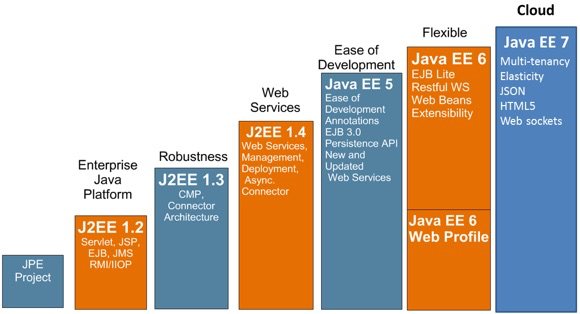
La plataforma Java EE (Java Enterprise Edition) es la plataforma Java estándar propuesta por Oracle para el desarrollo de aplicaciones web y aplicaciones empresariales (enterprise applications). Nace en el año 2000 con el nombre de Java 2 EE y en sus 15 años de existencia ha evolucionado en 6 distintas versiones hasta llegar a la versión Java EE 7 existente en la actualidad.
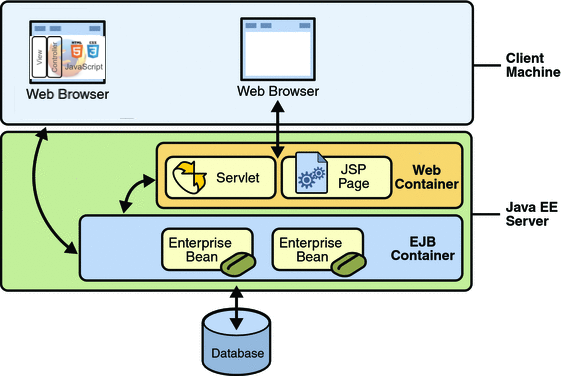
¿Qué es una aplicación empresarial o una aplicación web? ¿Cuál es la diferencia fundamental entre estas aplicaciones y las aplicaciones Java de escritorio (Java SE)? Lo veremos con detalle más adelante, pero vamos a adelantar un concepto muy importante: el servidor de aplicaciones. La diferencia fundamental entre estos tipos de aplicaciones y una aplicación Java de escritorio (Java SE) es el soporte de ejecución sobre el que corren. Estas últimas corren sobre la JVM mientras que las primeras se ejecutan dentro de un servidor de aplicaciones.
| Un servidor de aplicaciones es un programa Java que corre sobre la JVM y que da soporte de ejecución a otros programas Java que se despliegan en él. |
La Máquina Virtual Java (JVM) proporciona a una aplicación Java SE todo el soporte necesario para su ejecución (bibliotecas, ejecución de bytecodes, soporte de multi-hilos, etc.). Sin embargo, una aplicación web o una aplicación empresarial necesita para su ejecución una capa más (que también corre sobre la JVM), un programa Java denominado servidor de aplicaciones. Este programa ejecuta aplicaciones web o empresariales (que se despliegan en él) y da soporte de ejecución (runtime) a todo un conjunto de servicios y recursos, como procesamiento de las peticiones HTTP, acceso a bases de datos, a colas de mensajes o gestión de objetos creados por el propio servidor de aplicaciones. Todos estos recursos están a disposición de la aplicación desplegada y del programador que la desarrolla. Veremos más adelante estos conceptos con más detalle.
Existen dos posibles enfoques para definir la arquitectura de una aplicación Java EE.
-
En la versión más tradicional de la plataforma Java EE las aplicaciones web están diseñadas como una aplicación multi-capa, con una capa de frontend que genera la presentación HTML, una capa intermedia que proporciona seguridad y transaccionalidad y una capa de backend que proporciona conectividad a una base de datos o a un sistema heredado (legacy). Todo ello en el servidor.
-
En la versión mas moderna de Java EE se promueve una arquitectura alternativa en donde la capa de presentación o frontend se lleva al cliente web y se implementa en HTML5 y JavaScript. El servidor implementa un servicio REST con el que se comunica el cliente usando el protocolo HTTP. Este servicio REST, implementado con el API de Java EE 7, proporciona todas las funcionalidades de negocio y de acceso a datos. Al separar físicamente la capa de frontend de la capa de backend la aplicación se hace mucho más modular y más fácil de diseñar y mantener. Este es el estilo que vamos a seguir en el proyecto de aplicación web y en el Experto Java en general.
Aunque Java EE es una propuesta de Oracle, su diseño e implementación es un proceso en el que participan un gran número de empresas e instituciones, formando una comunidad abierta muy dinámica, con muchas aportaciones, propuestas y oportunidades.
1.1.1. La plataforma Java
La definición de la plataforma Java en la Wikipedia en inglés es muy acertada:
|
La plataforma Java es el nombre de un conjunto de programas relacionados que permiten desarrollar y ejecutar programas escritos en el lenguaje de programación Java. La plataforma no está ligada a un procesador o sistema operativo, sino a un motor de ejecución (llamado máquina virtual - Java Virtual Machine, JVM) y a un compilador con un conjunto de bibliotecas implementadas para distintos sistemas operativos y sistemas hardware, de forma que los programas Java pueden correr de forma idéntica en todos ellos. |
Entre los programas que forman parte de la plataforma los dos más importantes son:
-
El compilador
javacque convierte el código fuente Java en ficheros.classformados por código Java intermedio o bytecodes, idénticos para todas las plataformas -
El intérprete
java(JVM, Java Virtual Machine) que ejecuta los programas bytecodes de forma nativa en cada plataforma
Una característica fundamental de Java es que los ficheros .class son, por tanto, multiplataforma. Y también lo son los ficheros .jar y .war, ficheros archivo en el se incluyen múltiples archivos .class y que constituyen las bibliotecas de clases Java que se distribuyen e instalan en los distintos sistemas operativos. No es necesario compilar distintas versiones de una determinada biblioteca para los distintos sistemas operativos, sino que la diversidad la trata el soporte de ejecución (la JVM) que interpreta estos ficheros JAR.
Dentro de la JVM hay un denominado compilador JIT (Just In Time) que optimiza el funcionamiento en tiempo de ejecución del código interpretado. De esta forma se consigue reducir muchísimo la diferencia en tiempo de ejecución entre un programa Java con bytecodes interpretado y un programa compilado a código nativo. La introducción de esta técnica en la JVM supuso un gran avance en la adopción de Java y una forma de vencer las críticas sobre la lentitud del código comparado con código nativo. Hoy en día ya casi nadie critica a Java por ese motivo e incluso el enfoque de la máquina virtual que interpreta código intermedio ha sido adoptado también por la plataforma .NET de Microsoft.
Otro elemento fundamental de la plataforma Java es su enorme biblioteca de clases (class libraries). Se trata de un conjunto de bibliotecas estándar que proporcionan una gran cantidad de utilidades y funciones para todo tipo de operaciones, como el procesamiento de expresiones regulares, el trabajo con distintos tipos de colecciones, funciones de bajo nivel de entrada-salida o el procesamiento de imágenes. Las librerías se distribuyen como ficheros JAR que se cargan de forma dinámica en el intérprete y a las que nuestras aplicaciones llaman en tiempo de ejecución.
El API de las bibliotecas Java depende de la plataforma de Java (Java SE o Java EE). Toda la biblioteca de funciones de Java SE está disponible en Java EE. La plataforma Java EE define un conjunto adicional de funcionalidades implementadas por más de 20 APIs.
1.1.2. Aplicaciones web y servidores de aplicaciones
Las aplicaciones en el servidor necesitan estar funcionando continuamente para responder a todas las peticiones que reciben. Por ejemplo, una aplicación web que recibe peticiones HTTP debe estar continuamente escuchando el puerto (normalmente el 80), recibiendo las peticiones GET o POST de los clientes (navegadores), procesándolas y contestándolas.
El desarrollo de este tipo de aplicaciones sería complicadísimo si tuviéramos que preocuparnos de todo su ciclo de vida. Por ejemplo, sería un infierno tener que implementar nosotros todo el bucle de procesamiento de las peticiones que llegan al servidor, utilizando hilos concurrentes que gestionan la entrada-salida y que lanzan las llamadas a los métodos que realizan el procesamiento.
En la plataforma Java EE se utiliza la idea de contenedor para solucionar este problema. El contenedor es la aplicación Java que se encarga de realizar todo el trabajo de infraestructura (como escuchar los puertos para recibir las peticiones) y que delega el procesamiento final en las aplicaciones (componentes) desplegadas en él. El desarrollador implementa estos componentes escribiendo las interfaces de las clases que se utilizan para definir los componentes. Un ejemplo concreto es el funcionamiento de los servlets que veremos en la primera asignatura del curso.
En palabras de Arun Gupta (en su libro Java EE 7 Essentials):
|
Los componentes Java se despliegan en contenedores que proporcionan el soporte de su ejecución (runtime). Los contenedores proporcionan las APIs Java EE subyacentes a los componentes de aplicación. Las aplicaciones componentes Java EE nunca interaccionan directamente con otras aplicaciones componente. Utilizan protocolos y métodos del contenedor para interactuar entre ellas y con los servicios de la plataforma. La interposición de un contenedor entre las aplicaciones componentes y los servicios Java EE permite al contenedor inyectar transparentemente los servicios requeridos por el componete, como gestión declarativa de las transacciones, comprobaciones de seguridad, pooling de recursos y gestión del estado. |
Los servidores de aplicaciones ofrecen tambien un conjunto de servicios relacionados con la alta disponibilidad, como son tolerancia a fallos, concurrencia o clustering.
1.1.3. Historia de Java EE
En la actualidad Sun proporciona tres grandes distribuciones (o ediciones):
- Java ME (Java Micro Edition)
-
Para el desarrollo de aplicaciones Java en pequeños dispositivos (móviles, tarjetas de crédito, bluetooth, televisiones o reproductores blu-ray).
- Java SE (Java Standard Edition)
-
Para el desarrollo de aplicaciones de escritorio en ordenadores personales.
- Java EE (Java Enterprise Edition)
-
Para el desarrollo de aplicaciones distribuidas (cliente-servidor o con múltiples capas) como aplicaciones web o servicios web.
La historia de las versiones de estas distribuciones Java es la siguiente:
- Enero de 1996
-
JDK 1.0. Lanzamiento de JDK (Java Development Kit) 1.0, la primera versión del lenguaje.
- Febrero de 1997
-
JDK 1.1. lanzamiento de JDK 1.1, que incluía la primera versión de JDBC y de RMI (llamadas a objetos remotos).
- Diciembre de 1998
-
J2SE 1.2. En el primer cambio de nombre, la plataforma pasa a llamarse J2SE (Java 2 Platform, Standard Edition). La versión inicial de la distribución SE es la 1.2 (para mantener la numeración de versiones consistente con la del JDK). Se introducen importantes cambios en el lenguaje y en la plataforma. Se introduce la API Swing para el desarrollo de interfaces de usuario.
- Diciembre de 1999
-
J2EE 1.2. Aparece la primera versión de Java Enterprise, que incluye: JSP, Servlets, JDBC, EJB, JMS, JTA y JavaMail.
- Mayo de 2000
-
J2SE 1.3. Mejora la eficiencia de Java con la máquina virtual HotSpot.
- Septiembre de 2001
-
J2EE 1.3. Segunda versión de Java Enterprise, en la que se mejora el rendimiento de los EJB (EJB 2.0) y se introducen nuevas versiones de las APIs como JSP 1.2 o servlets 2.3.
- Febrero de 2002
-
J2SE 1.4. Se introducen APIs para tratar XML (JAXP), seguridad y criptografía (JCE, JSSE, JAAS). Se incluye Java Web Start para la distribución remota de aplicaciones Java de escritorio.
- Noviembre de 2003
-
J2EE 1.4. Nuevas versiones de las APIs: EJB 2.1, JSP 1.3, Servlets 2.4, JDBC 3.0. Se introducen por primera vez las librerías para los servicios Web.
- Septiembre de 2004
-
J2SE 1.5. Importantes cambios en el lenguaje: genéricos, anotaciones, enumeraciones o iteración.
- Mayo de 2006
-
Java EE 5. Otro cambio de nomenclatura de la plataforma, junto con un gran cambio en bastantes APIs. Se elimina el 2 después de la palabra Java y se elimina el 1 del número de versión. Se introduce la especificación 3.0 de los EJB con anotaciones, uso de persistencia (JPA) y timers. Nuevas versiones de APIs: JSP 2.1, Servlets 2.5, JDBC 4.0. Se introduce JSF y mejoras en los servicios Web.
- Diciembre de 2006
-
Java SE 6. Se incluye el cambio de nomenclatura que elimina el 2 después de Java. Mejoras en el rendimiento de Swing. Mejoras: Servicios web en Java SE, scripting (soporte para Python y Ruby), Java DB (base de datos basada en Apache Derby).
- Julio de 2008
-
Java SE 7. Lenguajes dinámicos en la JVM. Nueva librería de entrada/salida. Mejoras en el intérprete/compilador HotSpot.
- Diciembre de 2009
-
Java EE 6. Se introduce el perfil Web, con la intención de popularizar Java EE no sólo para el desarrollo de aplicaciones enterprise, sino también aplicaciones web sencillas. En esta línea, se define la versión reducida de EJB, EJB Lite, el API de servicios REST y los Web Beans.
- Marzo de 2014
-
Java SE 8. Grandes cambios en el lenguaje: expresiones lambda, anotaciones.
- Junio de 2014
-
Java EE 7. Se mejora el perfil Web, con énfasis en servicios REST, JSON, Web sockets y conexión con HTML5/JavaScript. En la parte enteprise, se profundiza en el despliegue en la nube y en el concepto de platform as a service.
1.1.4. Detalles de la plataforma Java EE 7
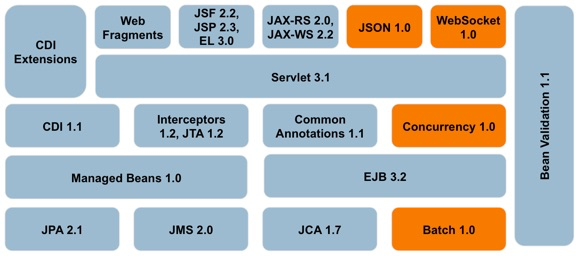
La plataforma Java EE 7 se define en la JSR 342. En la especificación se definen dos perfiles: el perfil web y el perfil completo. El perfil web está orientado a aplicaciones web básicas que no necesitan componentes transaccionales distribuidos. Las APIs que debe ofrecer el servidor de aplicaciones que soporta este perfil son las siguientes, agrupadas por la funcionalidad que proporcionan:
-
Anotaciones:
-
Common Annotations for the Java Platform (JSR-250) 1.2
-
-
Procesamiento de peticiones HTTP y ciclo de vida de la aplicación web:
-
Servlet 3.1
-
Managed Beans 1.0
-
Interceptors 1.2
-
Contexts and Dependency Injection for the Java EE Platform 1.1
-
-
Generación de páginas HTML:
-
JavaServer Pages (JSP) 2.3
-
Expression Language (EL) 3.0
-
Standard Tag Library for JavaServer Pages (JSTL) 1.2
-
JavaServer Faces (JSF) 2.2
-
-
Servicios REST y APIs avanzadas de comunicación con clientes:
-
Java API for RESTful Web Services (JAX-RS) 2.0
-
Java API for JSON Processing (JSON-P) 1.0
-
Java API for WebSocket (WebSocket) 1.0
-
-
Capa de lógica de negocio y de acceso a bases de datos:
-
Bean Validation 1.1
-
Enterprise JavaBeans (EJB) 3.2 Lite
-
Java Persistence API (JPA) 2.1
-
Java Transaction API (JTA) 1.2
-
Veremos una gran parte de estas APIs a lo largo de la primera parte del curso.
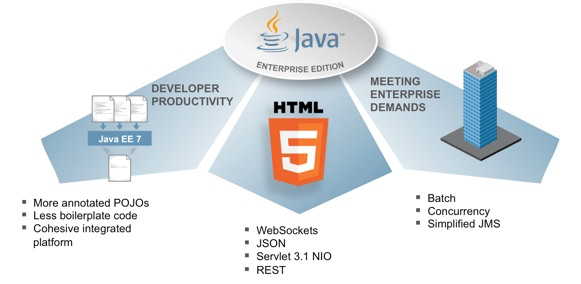
La plataforma completa Java EE 7 añade a las APIs anteriores otro conjunto de características, orientadas sobre todo al soporte de aplicaciones transaccionales distribuidas:
-
Enterprise JavaBeans (EJB) 3.2 completo
-
Java Message Service (JMS) 2.0
-
JavaMail 1.5
-
Connector 1.7
-
Web Services 1.4
-
Concurrency Utilities 1.0
-
Batch 1.0
-
Procesamiento XML con JAXB 2.2
-
Java EE Management 1.1
-
Java Authorization Contract for Containers (JACC) 1.5
-
Java Authentication Service Provider Interface for Containers (JASPIC) 1.1
-
Web Services Metadata 2.1
Todas estas especificaciones se encuentran detalladas en distintas especficaciones denominadas JSRs (Java Specification Request). Cada JSR tiene un número de identificación y puede ser consultada en el sitio web Java Community Process. Todas las especificaciones de APIs sufren un largo proceso desde que comienza su propuesta hasta su aprobación final en una votación en la que participan todos los partners interesados en el API.
Por ejemplo, ahora mismo (el 22 de septiembre) se acaba de aprobar (con 24 votos a favor y ninguno en contra) que comience el desarrollo de la JSR 366 que definirá la nueva especificación de Java EE 8. Todas las JSRs de APIs de la plataforma Java EE (incluidas las ya retiradas) se encuentran en este enlace. Y, por ejemplo, la especificación de Java EE 7 se define en la JSR 342 que tardó dos años en ser completada.
| Si la especificación de Java EE 8 tarda lo mismo en terminarse que la de Java EE 7, la nueva versión de la plataforma llegará a finales de 2016 o comienzos de 2017. |
Todas estas especificaciones sirven para que empresas independientes de Oracle (y también Oracle) desarrollen servidores de aplicaciones que compitan en rendimiento y funcionalidades adicionales, pero que sean todos compatibles entre si. El servidor GlassFish de Oracle es un servidor gratuito que sirve de plataforma de prueba de las especificaciones.
En la página de Oracle de compatibilidad de servidores de aplicaciones Java EE se listan los servidores de aplicaciones que han pasado las pruebas necesarias para obtener una compatibilidad con una determinada especificación Java EE. Existen muy pocos servidores de aplicaciones totalmente compatibles con Java EE 7, tanto en el perfil Web como en el perfil completo:
-
GlassFish (Oracle, perfiles web y completo)
-
Wildfly (anteriormente JBoss, RedHat, perfiles web y completo)
Por su mayor antiguedad, hay más servidores compatibles con Java EE 6:
-
GlassFish (Oracle, perfiles web y completo)
-
WebLogic (Oracle, perfil completo)
-
Wildfly (anteriormente JBoss, RedHat, perfiles web y completo)
-
WebSphere (IBM, perfil completo)
-
Geronimo (Apache, perfil completo)
-
TomEE (Apache, perfil web)
El servidor de aplicaciones que vamos a utilizar en el curso es Wildfly, uno de los más avanzados, ligeros y competitivos. Está desarrollado por Red Hat y es muy posible que lo conozcas con el nombre que tenía anteriormente: JBoss. Es un servidor gratuito que tiene la posibilidad de contratar licencias comerciales para su uso en entornos que requieran un funcionamiento continuo y una disposición inmediata para solución de incidencias.
1.2. Arquitectura del proyecto de aplicación web
En los últimos años está ganando cada vez más popularidad la arquitectura REST como enfoque para construir las aplicaciones web. De hecho, el temario del curso de experto y sus asignaturas está muy influenciado por esta filosofía. Y la aplicación web que vamos a implementar a lo largo del curso va a tener precisamente esta arquitectura.
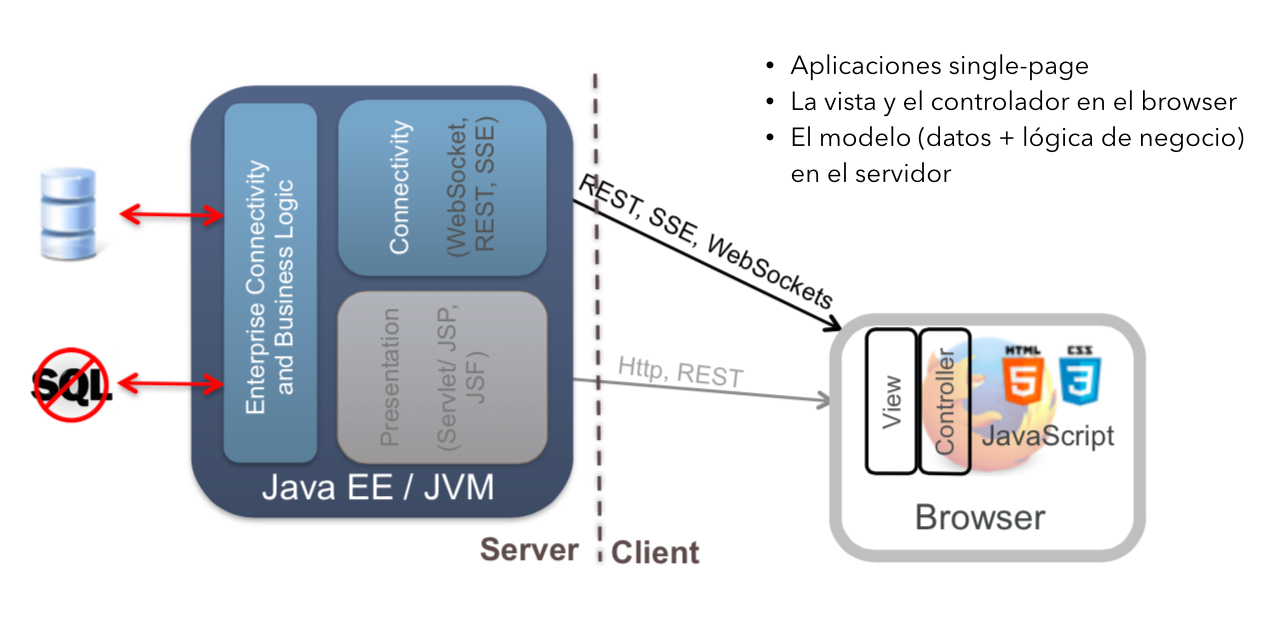
¿En qué consiste una arquitectura REST? ¿Cuáles son sus ventajas? ¿Cuál es la razón de su popularidad? En el curso vamos a dedicar una asignatura completa a hablar de cómo construir APIs REST utilizando la tecnología Java JAX-RS. Pero vamos a avanzar ahora algunos aspectos básicos de esta arquitectura.
1.2.1. Aplicaciones web basadas en REST
Ideas fundamentales:
-
Separación clara de responsabilidades entre del cliente y el servicio: el cliente se encarga de la interfaz de usuario y el servicio de la lógica de negocio. El cliente suele ser un navegador web o una aplicación móvil en el que se ejecuta el programa que interactua con el usuario, recoge sus peticiones y las envía al servicio. El servicio realiza toda las operaciones relacionadas con el procesamiento de la petición. Recoge los datos de la petición, accede a la base de datos, procesa los resultados y los devuelve al cliente.
-
Se utiliza el protocolo HTTP como base de la comunicación entre el cliente y el servidor: el cliente realiza peticiones utilizando los métodos GET, POST, PUT o DELETE para indicar el tipo de acción a realizar y las URLs como identificadores de los recursos sobre los que se está haciendo la petición. El servidor recibe la petición y devuelve un código de respuesta HTTP y el contenido de la respuesta.
-
La comunicación entre el cliente y el servidor se realiza usando texto estructurado. Las peticiones llevan los parámetros en las cabeceras HTTP o en las URL del recurso al que se está accediendo. Y los resultados se devuelven en formato texto XML o JSON.
1.2.2. Servicio REST
El servicio REST proporciona el backend de la aplicación. Lo implementamos con la tecnología Java EE, que proporciona APIs para definir las distintas capas de la aplicación:
-
API JAX-RS para implementar el API REST de la aplicación
-
Objetos EJB lite para definir la lógica de negocio
-
JPA/Hibernate para definir la capa de modelo y la conexión con la base de datos
Dibujo y ejemplo concreto.
1.2.3. Aplicación cliente JavaScript
La aplicación cliente se ejecuta en dispositivos separados del servidor (navegadores web o dispositivos móviles), construye la interfaz con la que interactúan los usuarios y se comunica con el servicio REST usando HTTP.
La tendencia que está ganando cada vez más fuerza es construir la aplicación cliente como una aplicación JavaScript que corre en un navegador web usando algún framework de alto nivel como AngularJS o BackboneJS. La aplicación cliente lanza peticiones HTTP al servicio y pinta la interfaz de usuario y la rellena con los resultados de las peticiones.
1.3. Guía de laboratorio
En esta sesión de ejercicios vamos a describir los aspectos más importantes de las distintas plataformas, utilidades y sitios web necesarios para el desarrollo de las prácticas del Experto.
- Máquina VirtualBox Linux Ubuntu
-
Las prácticas se desarrollarán en una máquina virtual (MV) VirtualBox basada en Linux Ubuntu. Disco SSD externo de 120 GB. Ponemos a vuestra disposición un disco SSD de 120 GB de alta velocidad, de más de 400 MB/s de escritura y lectura, el Samsung 840 EVO. El disco está instalado en una caja USB 3.0 StarTech con cable integrado. En el disco se guarda una imagen de la máquina VirtualBox con todo el software necesario para desarrollar las prácticas (fichero
Experto_Java_2014.vdi). El disco se encuentra formateado con el sistema de ficheros exFAT, para que sea posible guardar ficheros de más de 4GB (límite de FAT32). Para los usuarios de Mac esto puede ser un problema, ya que no es posible escribir de forma nativa en este sistema de ficheros. Consúltanos y te dejaremos algún programa para solucionar el problema. - Cuentas Bitbucket
-
Profesores y estudiantes usaremos cuentas en Bitbucket para guardar los repositorios git de los proyectos que se van desarrollando a lo largo del curso. La cuenta común bitbucket/java_ua guardará los repositorios iniciales (plantillas) de los distintos módulos del curso. Una vez terminado el módulo y entregados y corregidos los ejercicios se añadirá un repositorio con las soluciones. Las cuentas de los estudiantes serán privadas y contendrán los repositorios desarrollados por cada uno. Servirán como copia de seguridad del trabajo realizado y se utilizará también para realizar las entregas de los ejercicios de cada módulo.
- Apuntes y materiales docentes
-
Todos los apuntes, transparencias y materiales docentes están disponibles en una zona restringida de la web de apuntes del Experto (http://expertojava.ua.es).
- Moodle
-
Se utilizará la plataforma Moodle del Campus Virtual de la UA para la interacción on-line. Usaremos principalmente sus funcionalidades de foros y de puntuaciones de las entregas de ejercicios.
A continuación vamos a detallar el uso de estos elementos y algunos otros también necesarios para el desarrollo de las prácticas del Experto.
1.3.1. Materiales docentes
Los apuntes, trasparencias y demás material docente se encuentran en un sitio web restringido a los alumnos del Experto. Puedes acceder a los materiales de cada módulo desde los enlaces disponibles en las páginas públicas de cada uno de las asignaturas del experto, accesibles desde el menú superior de las páginas públicas del Experto:
Cuando intentes acceder a la zona restringida del Experto Java aparecerá una página pidiéndote tu usuario y contraseña. El usuario será tu inicial (o iniciales) del nombre y tu primer apellido. Por ejemplo, el login de Juan Luis Pérez será jlperez.
Si deseas cambiar tu contraseña (o no la recuerdas), puedes pulsar en el enlace correspondiente. Se enviará un mensaje a tu dirección de correo con un enlace con el que podrás modificar la contraseña.
1.3.2. Moodle
La Universidad de Alicante utiliza dos plataformas on-line para la interacción docente: Campus Virtual y Moodle. En nuestro título vamos a utilizar Moodle por considerarlo bastante más potente, flexible y fácil de utilizar que el Campus Virtual.
Para acceder a Moodle debes logearte en el CV de la UA y pulsar en el botón que hay en la parte inferior izquierda:
Vamos a utilizar Moodle como plataforma de trabajo colaborativo. La usaremos para gestionar los foros, las calificaciones de los ejercicios y alguna que otra encuesta que iremos presentando.
Uno de los elementos principales que utilizaremos de Moodle es el foro, que utilizaremos para resolver dudas que puedan surgir sobre el desarrollo de los ejercicios de las asignaturas o sobre cualquier tema relacionado con el título. Cualquiera puede publicar una entrada nueva en el foro o contestar a las ya existentes. Cada nueva entrada o contestación genera un correo electrónico que se envía a todos los profesores y estudiantes.
Para poder utilizar correctamente el foro es muy importante que actualices tu foto. Para esto debes pinchar en Administración > Ajustes de mi perfil > Editar perfil) y seleccionar Imagen del usuario. Allí puedes colocar tu foto. Cuando todos tenemos la foto es mucho más sencillo contestar e interactuar en el foro. La siguiente imagen muestra un ejemplo del foro general en la edición 2009-2010 del especialista:
En la página principal del curso podrás encontrar también:
-
Enlaces a las tareas de entregas de ejercicios de cada una de las asignaturas
-
Calendario de clases y entregas de ejercicios
-
Enlaces a los apuntes y materiales de la asignatura en curso
1.3.3. Ordenadores de la UA
Las clases se impartirán en un laboratorio gestionado por la EPS (los viernes, el laboratorio L17) y en un laboratorio gestionado por el Servicio de Informática (los sábados, en el Aulario I).
Para acceder los laboratorios de la EPS se debe contar con una cuenta de usuario (más información).
Al arrancar el ordenador deberás seleccionar como sistema operativo Windows. En este sistema operativo se encuentra el programa VirtualBox con el que se pondrá en marcha la MV en la que se realizarán las prácticas.
Trabajaremos directamente con la imagen de la MV en el disco externo SSD. Incluso en ordenadores con USB 2.0 el rendimiento será aceptable. En los ordenadores con USB 3.0 podrás aprovechar completamente la velocidad del disco SSD.
Buscar cuál es la disposición de puertos USB 3.0 en los ordenadores nuevos de la EPS.
|
¡Cuidado con tus datos! Debes tener precaución con el disco externo. Si le sucediera algo a la máquina virtual perderías todo lo hecho en el curso. Por ello debes tener cuidado de copiar regularmente la máquina virtual en tu ordenador de casa y de subir a Bitbucket los repositorios con los proyectos Java. |
1.3.4. Máquina virtual Virtual Box
Uno de los elementos más importantes de las prácticas del curso es la MV con una distribución de Linux Lubuntu y con las herramientas necesarias para realizar los ejercicios. Su uso te hace sencillo continuar en casa los ejercicios y prácticas realizados en clase y garantiza que todos utilizamos el mismo entorno de trabajo. También nos hace inmunes a posibles cambios en las instalaciones de los ordenadores de la universidad.
El disco imagen de la MV original se encuentra en el disco externo, y también comprimida en la zona restringida de apuntes de la web del Experto y dividida en 4 ficheros ZIP de unos 900 MB cada uno:
La MV Ubuntu es compatible con las últimas versiones VirtualBox. La versión de las Guest Additions instalada en la MV es la 4.3.14.
VirtualBox es multiplataforma y opensource. Existen versiones para Windows, Mac y Linux y es posible trabajar con la misma máquina virtual en distintos sistemas operativos. Puedes, por ejemplo, trabajar en la EPS en Windows y después continuar el trabajo en casa en Mac. Puedes bajar la última versión e instalarla en tu ordenador de casa desde la web de VirtualBox. Una vez instalado el programa VirtualBox, debes instalar también el VirtualBox Extension Pack que proporciona soporte para hardware adicional en el ordenador anfitrión, como el USB 2.0.
1.3.5. Máquina virtual Lubuntu
En la máquina virtual está instalada la versión 14.04 de Lubuntu, una versión más ligera del sistema operativo Ubuntu que usa una interfaz de usuario mínima y funcional basada en LXDE.
En la MV se ha creado el usuario expertojava con la contraseña expertojava. Tendrás que utilizar este login para entrar en el sistema, para ejecutar comandos en modo superusuario o cuando se bloquee la pantalla:
El disco de la máquina virtual tiene una capacidad máxima de 52 GB. Las aplicaciones instaladas ocupan inicialmente alrededor de 8 GB.
En la máquina virtual se ha instalado el software que vamos a utilizar a lo largo de todos los módulos del curso:
-
Plataforma Java 1.7.0_65
-
Entorno de desarrollo IntelliJ IDEA 13 con licencia de desarrollo para la Universidad de la Alicante
-
Servidor de aplicaciones JBoss WildFly 8
-
Bases de datos: MySQL 5.5 (contraseña del usuario root:
expertojava) y MongoDB -
Editor de textos avanzado Atom
-
Node y npm
-
Herramientas: Maven, Git, Curl
1.3.6. Paso a paso: creación de la MV Ubuntu en el ordenador anfitrión
Lo primero que tenemos que hacer es crear con VirtualBox la máquina virtual en la que vamos a trabajar. Vamos a crear la MV para que trabaje con la imagen vdi en el disco externo (Experto_Java_2014.vdi).
-
Arranca VirtualBox en el ordenador anfitrión y crea una nueva MV de tipo Linux Ubuntu con el nombre
Experto Java: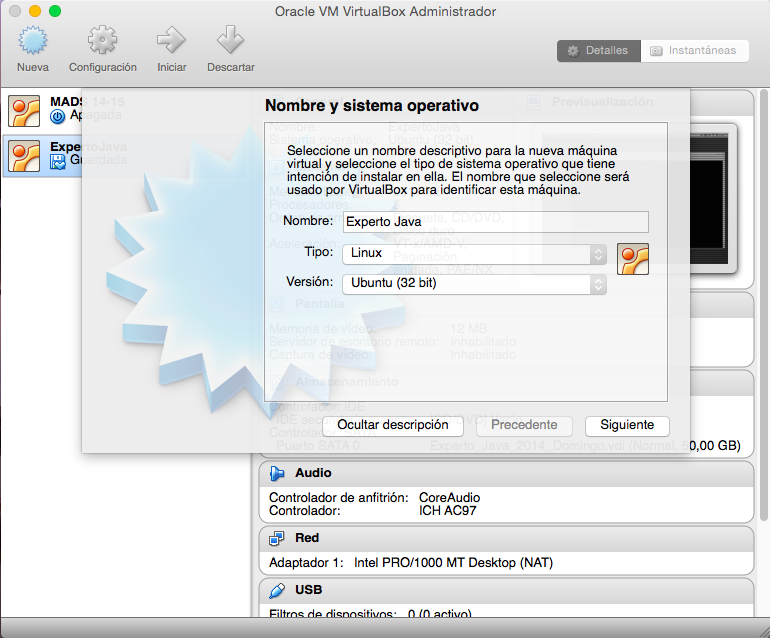
-
Define el tamaño de la memoria de la MV en un valor suficiente para trabajar cómodamente con el entorno de trabajo y que no comprometa el rendimiento del ordenador anfitrión. Los ordenadores de la EPS tienen 4 GB de memoria y 2 GB está en límite de lo recomendable. Pondremos alrededor de 2 GB.
-
Ahora debemos vincular la imagen vdi del disco externo con la máquina virtual que estamos creando. Para ello, en la pantalla Disco Duro Virtual seleccionamos la opción Usar un archivo de disco duro virtual existente y seleccionamos el fichero
Experto_Java_2014.vdien el disco duro externo. -
Terminamos configurando el número de procesadores de la MV. Es muy recomendable trabajar con al menos 2 procesadores, porque el rendimiento aumenta muchísimo. Para ello debemos seleccionar la opción Configuración > Sistema > Habilitar IO APIC:
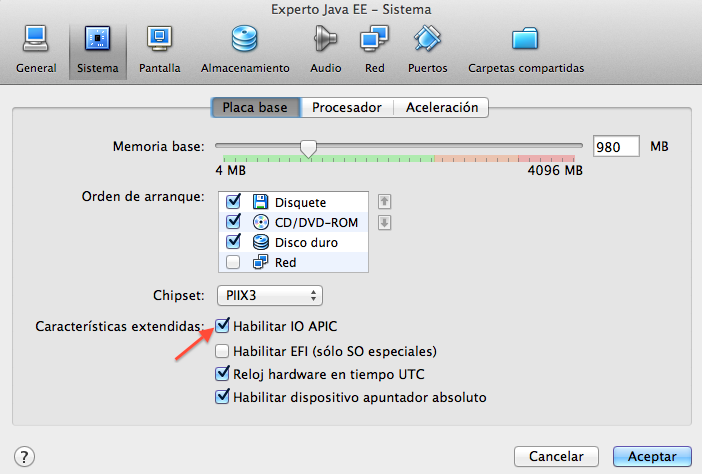
Y después definir más de 1 procesador en la pestaña de Procesador.
La configuración de la máquina virtual creada se guarda en la carpeta VirtualBox VMs del directorio de usuario en el ordenador anfitrión. Como en los ordenadores de la universidad se restauran los discos duros frecuentemente, deberás repetir esto cada vez que empiece la sesión de prácticas. En tu ordenador de casa, bastará que lo hagas una vez.
Instalación de Guest Additions
Es recomendable instalar las Guest Additions. Con ellas instaladas es posible pasar del SO invitado (lubuntu) al SO anfitrión sin tener que pulsar ninguna combinación de teclas, sólo moviendo el cursor. También son útiles para copiar y pegar texto entre ambos sistemas operativos, así como para cambiar fácilmente la resolución de la pantalla.
Las Guest Additions ya están instaladas en la imagen inicial. Si en algún momento actualizas VirtualBox o lubuntu, deberás también volver a instalar Guest Additions. Para ellos debes seleccionar la opción Dispositivos > Insertar Guest Additions CD Image del menú de Virtual Box que aparece cuando estamos ejecutando la MV. Esto montará en lubunutu un disco con distintos comandos disponibles. Deberás abrir un terminal y ejecutar:
$ cd /media/expertojava/VBOXADDITIONS_<version>
$ sudo ./VBoxLinuxAdditions.runUna vez instaladas, debes desmontar el CD y reiniciar lubuntu.
Compartición de directorios con el anfitrión
Una vez instaladas las Guest Additions es posible compartir directorios entre el ordenador invitado (lubuntu) y el anfitrión (Windows, Mac, etc.). Para ello selecciona la opción Dispositivos > Directorios Compartidos y pulsa en el icono para añadir un nuevo directorio transitorio (no se guardan los datos de un arranque a otro).
Aparecerá una ventana en la que debes indicar la ruta del directorio del ordenador anfitrión que se quiere compartir y un nombre simbólico con el que identificar ese directorio. Para indicar la ruta del directorio en el anfitrión puedes también escoger la opción del desplegable que abre el navegador de archivos para seleccionarlo gráficamente.
Crea el directorio Compartido MV en el ordenador anfitrión, escógelo y escribe como nombre simbólico Compartido.
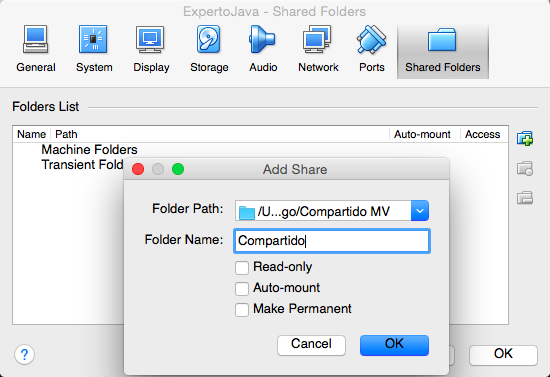
De esta forma estamos creando un dispositivo que puede ser montado en el sistema y que tiene como nombre Compartido y que estará conectado con el directorio `Compartido MV`_ en el ordenador anfitrión.
Por último debemos crear un directorio en la MV que haga de punto de montaje del dispositivo que acabamos de crear. Lo podemos llamar con cualquier nombre, por ejemplo Host. Y después usamos el comando mount como root para montarlo:
$ cd Escritorio
$ mkdir Host
$ sudo mount -t vboxsf -o uid=1000,gid=1000 Compartido HostLos parámetros uid=1000,gid=1000 hacen que el propietario de la carpeta compartida sea el propio usuario, con lo que no es necesario ser root para explorarla.
Para desmontar el directorio llamamos al comando umount:
$ sudo umount Host1.3.7. Git y Bitbucket
Vamos a desarrollar todos los proyectos del experto utilizando el sistema de control de versiones distribuido Git. Con este sistema de control de versiones trabajaremos sobre un repositorio local y tendremos una réplica en un sitio remoto. Iremos confirmando (commit) todos los cambios que vamos realizando sobre el código fuente de nuestros proyectos en el repositorio local y luego subiremos (push) estos cambios al repositorio remoto. El repositorio remoto servirá de copia de seguridad y para compartir el código con los profesores.
Para la creación de los repositorios remotos utilizaremos el servicio Bitbucket.
Vamos a ver en cómo crear nuestro primer repositorio git. Podemos hacerlo primero en remoto y después bajarlo a nuestro ordenador o al revés.
Creación de un repositorio remoto en bitbucket
Vamos a ver cómo crear un repositorio privado en bitbucket Bitbucket que vincularemos con nuestro repositorio local.
-
En primer lugar, deberemos crearnos una cuenta personal en bitbucket, si no disponemos ya de una: (https://bitbucket.org)
-
Creamos desde nuestra cuenta de bitbucket un repositorio (Repositories > Create repository).
-
Deberemos darle un nombre al repositorio, por ejemplo
prueba-expertojava. Será de tipo Git y como lenguaje especificaremos Java.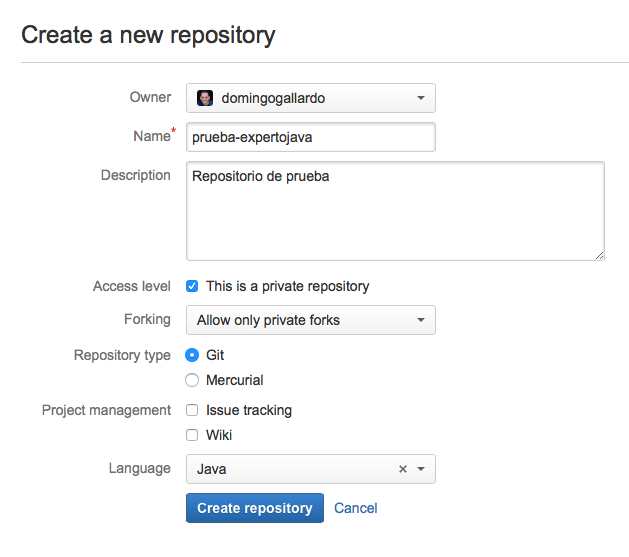
-
Una vez hecho esto, veremos el repositorio ya creado, en cuya ficha podremos encontrar la ruta que nos dará acceso a él.
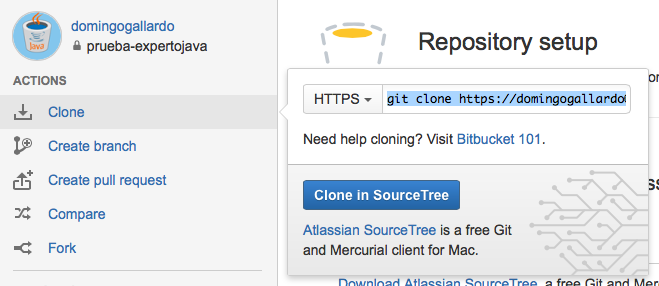
Será útil copiar la dirección anterior para vincular con ella nuestro repositorio local al remoto. Veremos como hacer esto en el siguiente apartado.
Creación del repositorio git local
Tenemos dos alternativas para crear un repositorio local vinculado al remoto:
-
Clonar el repositorio remoto, lo cual inicializa un repositorio local en el que ya está configurado el vínculo con el remoto.
-
Crear un repositorio local independiente, y vincularlo posteriormente con un repositorio remoto.
Para realizar cualquiera de estas dos alternativas hay que utilizar comandos de Git. Es posible hacerlo desde el IDE IntelliJ, pero es mucho más útil aprender a trabajar con Git desde línea de comandos. Así podremos utilizar los comandos en cualquier entorno y no dependeremos de tener instalado un entorno gráfico que es mucho más pesado que un sencillo terminal.
Creación a partir del repositorio remoto
La forma más sencilla de crear un repositorio Git local es hacerlo directamente a partir del repositorio remoto. Si ya tenemos un repositorio remoto (vacío o con contenido) podemos clonarlo en nuestra máquina local con:
$ git clone https://<usuario>:bitbucket.org/<usuario>/prueba-expertojavaEste comando podemos copiarlo directamente desde bitbucket, tal como hemos visto en el último paso del apartado anterior (opción Clone de la interfaz del repositorio).
De esta forma se crea en nuestro ordenador el directorio prueba-expertojava y se descarga en él el contenido del proyecto, en caso de no estar vacío el repositorio remoto. Además, quedará configurado como repositorio git local y conectado de forma automática con el repositorio git remoto del que lo hemos clonado.
Creación de un repositorio local y vinculación con el remoto
Esta forma es algo más compleja que la anterior, pero será útil si tenemos ya creado un repositorio git local de antemano, o si queremos vincularlo con varios repositorios remotos.
Para la creación de un repositorio git local seguiremos los siguientes pasos.
-
Creamos un directorio local y nos movemos a él:
$ mkdir prueba-expertojava
$ cd prueba-expertojava-
Inicializamos el repositorio git. Estando en la raíz del directorio
prueba-expertojavahacemos:
$ git init-
Conectamos el repositirio local con el remoto. En bitbucket veremos la URL que identifica el repositorio, que será del tipo:
https://<usuario>@bitbucket.org/<usuario>/presentacion-expertojava.git. Desde el directorio raíz del proyecto ejecutamos:
$ git remote add origin https://<usuario>@bitbucket.org/<usuario>/prueba-expertojava.gitDe esta forma añadimos añadiendo un repositorio remoto llamado origin (el nombre por defecto del repositorio remoto en git) conectado al local. Hemos inicializado nuestro directorio como un repositorio local git y lo hemos conectado con el repositorio remoto situado en Bitbucket.
Registrar cambios en el repositorio
Independientemente de cuál de los métodos anteriores hayamos utilizado para inicializar nuestro repositorio git local, lo habremos conectado con el repositorio remoto de Bitbucket.
Vamos a ver ahora cómo trabajar con un repositorio git.
En primer lugar será recomendable añadir un fichero .gitignore al directorio del proyecto, que dependerá del tipo de proyecto y que se encargará de excluir del control de versiones todos aquellos tipos de ficheros que sean generados automáticamente (por ejemplo las clases compiladas). Podemos encontrar diferentes modelos de .gitignore en: (https://github.com/github/gitignore)
Tras añadir el .gitignore correcto para nuestro tipo de proyecto podremos añadir nuevos ficheros, registrarlos en el sistema de control de versiones y confirmar los cambios que realicemos.
Antes de añadir ningún cambio al repositorio debemos inicializar en la máquina linux las variables de git user.name y user.email para que quede registrado el usuario que hace los commits. El user.email debe coincidir con el correo electrónico registrado en Bitbucket.
$ git config --global user.name "Pepito Pérez"
$ git config --global user.email pepito.perez@gmail.comA partir de ahora todos los cambios se registrán como realizados por ese usuario. A partir de ahora cada vez que queramos registrar cambios en el repositorio local deberemos:
-
Si hemos añadido nuevos archivos al proyecto, deberemos añadirlos al sistema de control de versiones con
git add:
$ echo "Hola mundo" > hola-mundo.txt
$ git add .-
Podemos confirmar los cambios realizados y añadirlos al control de versiones con el comando
git commit -a -m(o haciendo commit desde el IDE). Es obligatorio añadir un mensaje con una explicación del cambio realizado:
$ git commit -a -m "Primer fichero en el repositorio"-
Git almacena los cambios confirmados en el repositorio local. En este caso hemos añadido un fichero llamado
hola-mundo.txt. Cuando queramos subir un conjunto de cambios al repositorio remoto deberemos hacer un push para subir al repositorio origin (en Bitbucket):
$ git push -u origin master-
Al hacer
- uindicamos que la rama master local está haciendo tracking de la rama master en origin. A partir de ahora sólo será necesario hacergit pushpara subir los cambios. -
Editamos con algún editor sencillo el fichero
hola-mundo.txty añadimos un par de líneas más. Hacemos después un commit:
$ gedit hola-mundo.txt
$ git status # Comprobamos los cambios sin confirmar
$ git commit -a -m "Añadidas un par de líneas en hola-mundo.txt"Cada commit representa un punto del desarrollo al que podríamos volver con el comando git checkout <commit-id> para examinar esa versión o crear nuevas ramas.
Para listar todos los commits realizados podemos hacer:
$ git log --onelineSe listan el identificador del commit y su comentario.
Por último, podemos volver a hacer git push para subir los cambios al repositorio:
$ git status
$ git pushCompartición de repositorio
Bitbucket permite compartir un repositorio con otros usuarios. Vamos a utilizar esta características para compartir las plantillas iniciales de los ejercicios y para realizar las entregas de los mismos:
-
Los profesores compartirán con vosotros los repositorios iniciales de cada módulo, a partir de los que se comenzaréis a realizar los ejercicios del módulo. Deberéis hacer una copia de propia haciendo un fork en la cuenta personal de Bitbucket.
-
Una vez que hayáis terminado de realizar los ejercicios, en la fecha de entrega de la asignatura, deberéis dar permiso de lectura al repositorio al profesor que ha impartido el módulo. Se puede hacer desde Settings > Access management:
1.3.8. Creación de proyectos con IntelliJ
Vamos a realizar una rápida introducción a la creación de proyectos y la sincronización con git y Bitbucket usando IntelliJ, el IDE que utilizaremos a lo largo de todo el curso.
En IntelliJ es importante diferenciar entre proyecto y módulo. El proyecto es el directorio principal de trabajo de IntelliJ, en el que se guarda la configuración de los distintos elementos que vamos creando en el entorno. Puede constituir un proyecto Java único, con sus clases, sus bibliotecas, sus ficheros de configuración, etc. O también puede contener más de un módulo, subdirectorios que constituyen subproyectos independientes pero que pueden compartir ciertos elementos situados en el proyecto principal.
Los proyectos y módulos del entorno se corresponden con directorios del sistema operativo y guardan la configuración en ficheros XML. La información de un proyecto se guarda en el directorio oculto .idea dentro del directorio con el nombre del proyecto. Por ejemplo, si creamos el proyecto prueba se creará un directorio con el mismo nombre que contendrá el directorio .idea. Lo podemos comprobar desde el terminal:
$ cd prueba
$ ls -laLos que conocen Eclipse pueden ver un proyecto IntelliJ como un workspace de Eclipse, con la diferencia de que en Eclipse no es posible usar un workspace como un proyecto con código fuente.
Cada módulo se guarda como un directorio con el nombre del módulo, en el que se crea un fichero <modulo>.iml con la configuración del módulo.
En IntelliJ podremos crear tres tipos de proyectos:
-
Proyectos que contienen únicamente código fuente, sin incluir ningún módulo adicional:
-
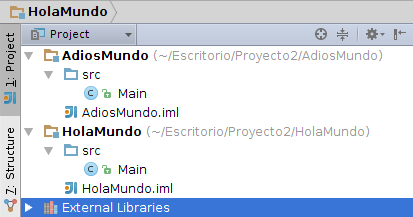
Proyectos vacíos que contienen distintos módulos:
-
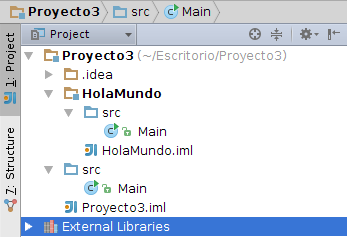
Proyectos que contienen código fuente y que además incluye módulos adicionales:
En todos los casos anteriores se puede definir un repositorio git en el proyecto principal, que contenga todos sus elementos (ya sea código fuente y/o otros subproyectos).
Vamos a empezar con un ejemplo del segundo tipo de proyectos: un proyecto vacío que contiene un par de módulos (programas Java) y que sincronizaremos posteriormente con Bitbucket. Lo hacemos paso a paso.
Paso a paso: creción de un proyecto git con varios módulos en IntelliJ
-
Crea un repositorio
pres-expertojavaen tu cuenta de Bitbucket. -
Abre IntelliJ y crea un proyecto vacío con el mismo nombre
pres-expertojavaen cualquier directorio, por ejemplo el escritorio.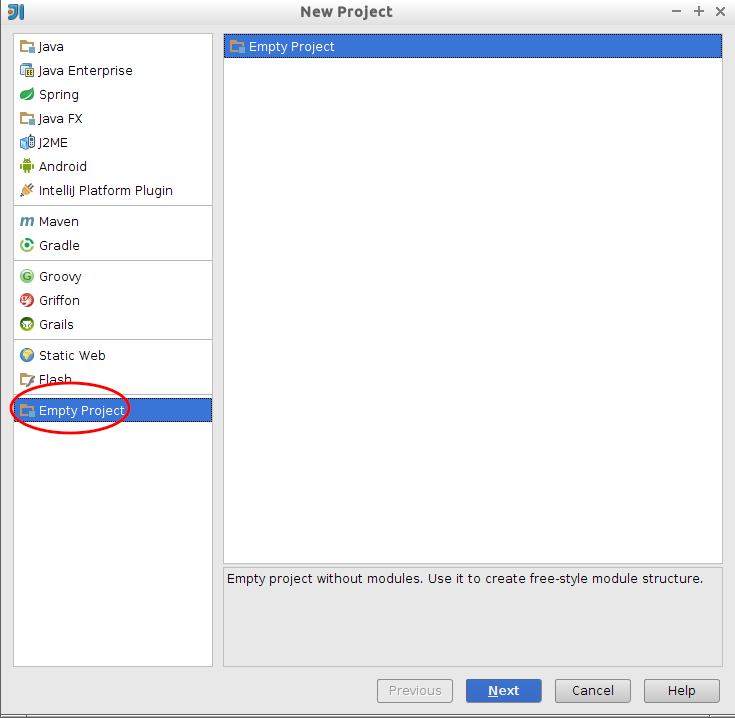
-
Se habrá creado un directorio nuevo con ese nombre. Vamos ahora a un terminal. Es más fácil inicializar git desde línea de comando que desde IntelliJ. Crea el fichero
.gitignorecon un editor, por ejemploatom:$ cd Escritorio/pres-expertojava $ atom .gitignore -
Copia el siguiente código:
Fichero .gitignore:# IntelliJ out/ .idea/workspace.xml # Maven output target #OS X stuff .DS_Store -
Inicializa git en el directorio, añade los ficheros al repositorio y conéctalo con el repositorio remoto en Bitbucket:
$ git init $ git add . $ git commit -m "Creado el repositorio" $ git remote add origin https://<usuario>@bitbucket.org/<usuario>/pres-expertojava.git $ git push -u origin masterSi ejecutas el comando
ls -laverás que se ha creado un directorio oculto.giten el que se guarda la configuración del repositorio git creado (en el fichero.git\config) y todos los commits que se realicen en el repositorio local. -
Ahora ya podemos cambiar a IntelliJ. Una vez creado el repositorio es cómodo realizar los commits desde el IDE. Creamos un nuevo módulo Java dentro del proyecto, con la opción File > New Module…. Pichamos Next y le damos el nombre al nuevo módulo:
hola-mundo:
-
Creamos una nueva clase
HolaMundopinchando con el botón derecho sobre el directoriosrcy seleccionando New > Java Class: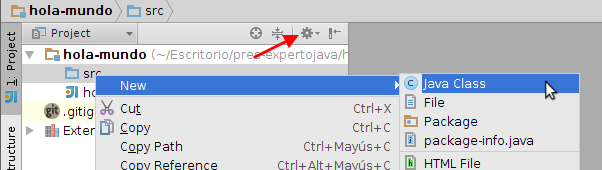
Aunque lo habitual es crear las clases Java dentro de packages, en este caso no lo hemos hecho para simplificar el ejercicio. En el experto vamos a nombrar los paquetes siempre empezando por
org.expertojava. Para trabajar con paquetes es recomendable seleccionar la opción Flatten Packages que hay en la rueda dentada en la parte superior derecha del panel de proyectos. -
Le damos a la clase como nombre
HolaMundoy escribimos el típico código Hola mundo:public class HolaMundo { public static void main(String[] args) { System.out.println("Hola, mundo\n"); } }En IntelliJ es posible utilizar abreviaturas que se expanden en código. Por ejemplo, escribe
psvmy pulsa el tabulador. Verás que se expande en la plantilla de la funciónmain. Puedes también escribirsouty pulsar el tabulador. Verás que se expande en una plantilla para hacer unSystem.out.println.Estas abreviaturas se denominan Live Templates. Puedes consultar, modificar y añadir nuevas plantillas seleccionando File > Settings > IDE Settings > Live Templates.
-
IntelliJ todavía no ha detectado que hemos inicializado git en el repositorio. Para ello hay que seleccionar VCS > Enable Version Control Integration… y seleccionar
Git.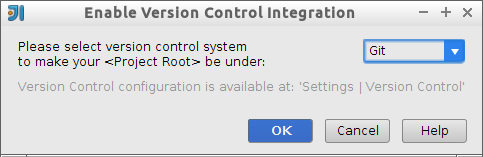
El menú VCS (Version Control System) es muy importante, ahí se encuentran todas las opciones relacionadas con Git.
Verás que automáticamente en el panel del proyecto cambia el color de los ficheros que no están confirmados y que aparecen nuevas opciones en el entorno.
-
Abriendo el panel inferior Changes podemos gestionar los cambios pendientes de confirmar del proyecto
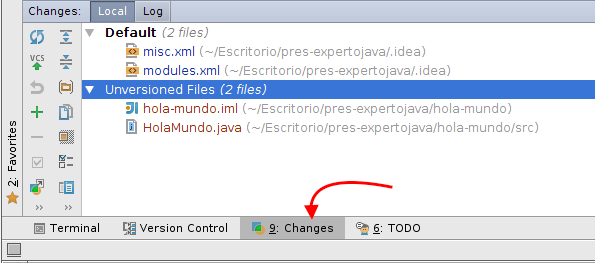
El color del nombre de un fichero indica su estado en el control de versiones:
-
Rojo: Fichero sin añadir
-
Verde: Fichero que será añadido en el siguiente commit
-
Azul: Fichero con cambios pendientes de confirmar
-
Negro: Fichero sin cambios
-
-
Pulsamos el botón derecho sobre Unversioned Files y seleccionamos la opción Add to VCS (o pulsamos Ctrl+Alt+A). Los ficheros se añadirán a la lista de cambios (Changelist) Default:
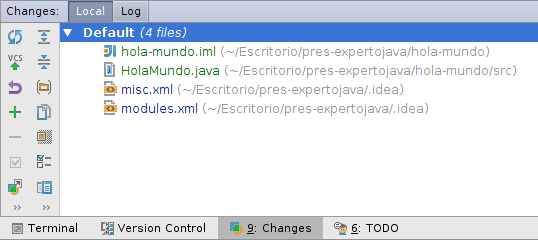
-
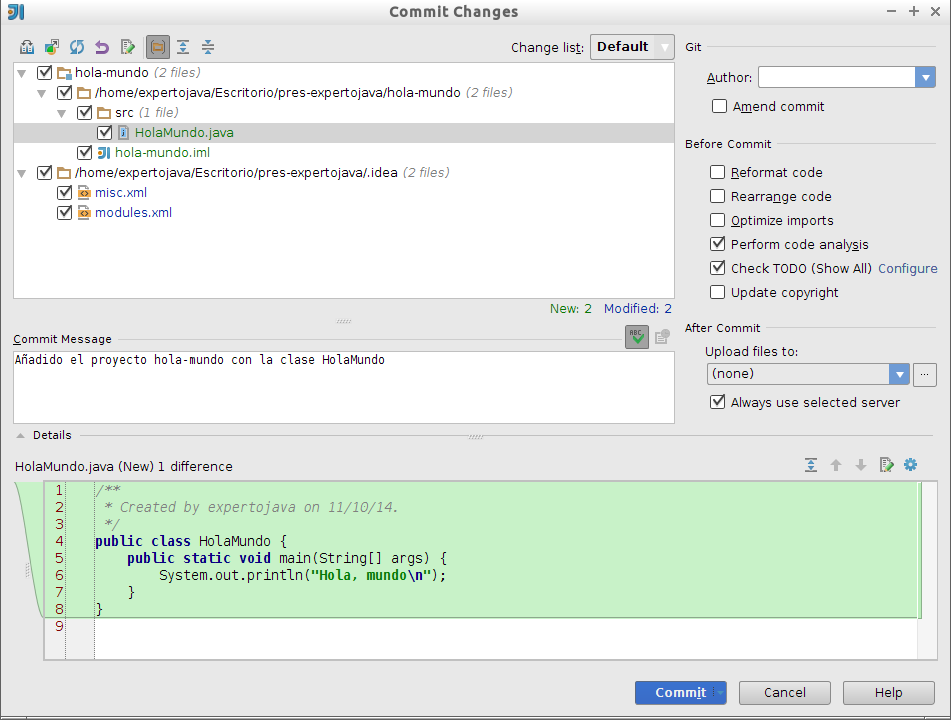
Pulsamos con el botón derecho Commit y aparecerá una ventana en la que podemos revisar los cambios, añadir un comentario y confirmarlos
También podemos realizar un commit de los cambios en un fichero o en un directorio:
-
Desde el menú VCS, seleccionando el fichero o directorio en el panel del proyecto y seleccionando la opción VCS > Git > Commit File….
-
Pulsando Ctrl+K
-
-
Vamos a terminar creando una configuración de ejecución para ejecutar el programa y subiendo todos los cambios a Bitbucket. Para crear una configuración de ejecución pulsa en el desplegable junto al botón Play (ahora inactivo) y selecciona Edit Configurations…

-
Aparece una ventana para gestionar las configuraciones de ejecución. Crea una nueva configuración de ejecución pulsando el símbolo
+en la esquina superior izquierda y seleccionando Application. Rellena los siguientes datos:-
Share: chequeado (para que la configuración se guarde en el control de versiones)
-
Name: HolaMundo
-
Main class: HolaMundo (puedes seleccionarla con el botón de la derecha del campo)
-
Working directory: /home/expertojava/Escritorio/pres-expertojava (aparece por defecto)
-
Use classpath of module: hola-mundo
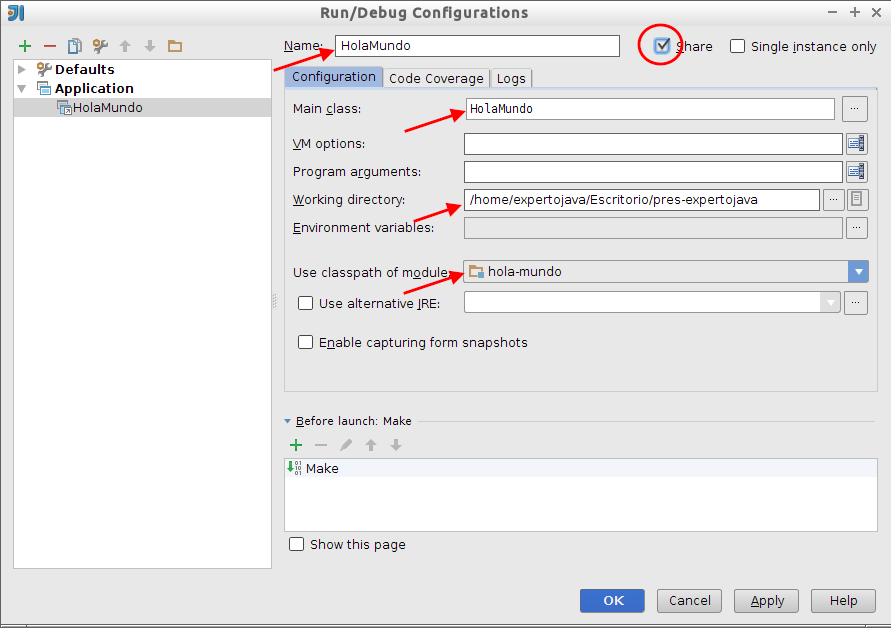
Aparecerá un aviso preguntando si queremos añadir al control de versiones la configuración de ejecución. Decimos que sí. Ya podemos ejecutar o depurar el programa:

-
-
Ejecutamos el programa, comprobando que aparece el panel con la salida en la parte inferior de la ventana. Confirmamos los cambios.
-
Por último, subimos (push) los cambios al repositorio en Bitbucket. Lo podemos hacer seleccionando VCS > Git > Push… o Ctrl+Mayús+K. Aparece una ventana que nos permite revisar por última vez los cambios que vamos a subir al repositorio remoto:
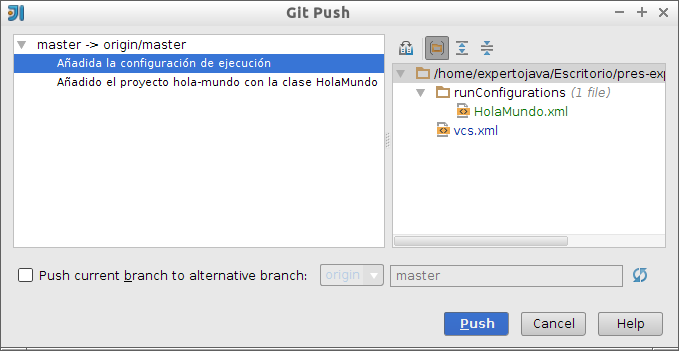
-
Comprobamos en el navegador que se han subido los cambios correctamente a Bitbucket:
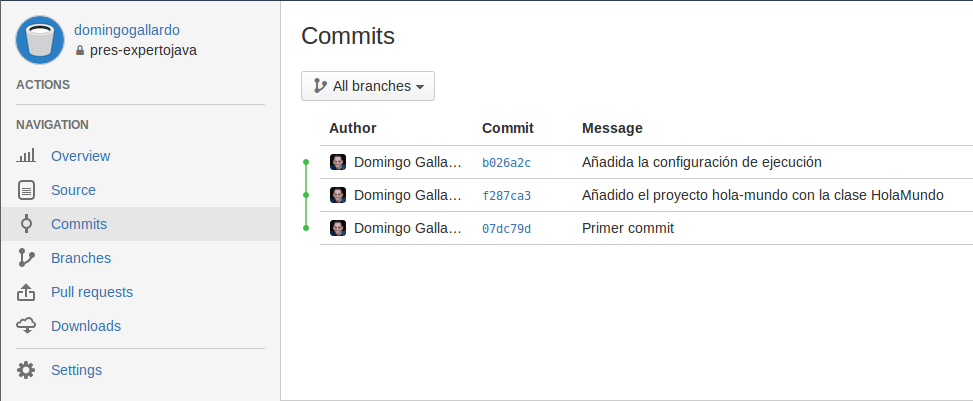
-
Ahora que ya has aprendido a crear proyectos y módulos en IntelliJ y trabajar con git y bitbucket, crea un nuevo módulo denominado
saludoque imprima por la salida estándarHola, soy <mi nombre>. Crea una configuración de ejecución y sube todo a Bitbucket.
Paso a paso: importar plantillas de bitbucket
Vamos a terminar explicando cómo trabajar con proyectos dejados en Bitbucket por los profesores, que servirán como plantillas de los ejercicios a realizar en la asignatura.
-
En tu cuenta de Bitbucket verás el repositorio
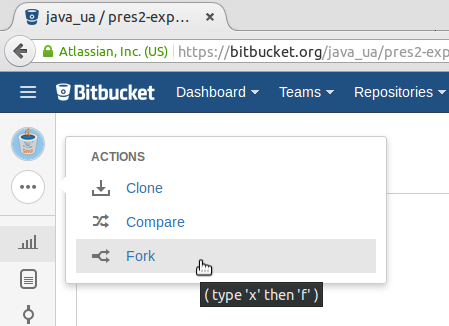
java_ua/pres2-expertojava. Ese repositorio está en la cuentajava_ua, usada por los profesores del experto para dejar repositorios accesibles a los alumnos. Allí dejaremos los repositorios con las plantillas de ejercicios de las asignaturas y con las soluciones, una vez concluida la fecha de entrega. Los repositorios tienen sólo permiso de lectura para los estudiantes. -
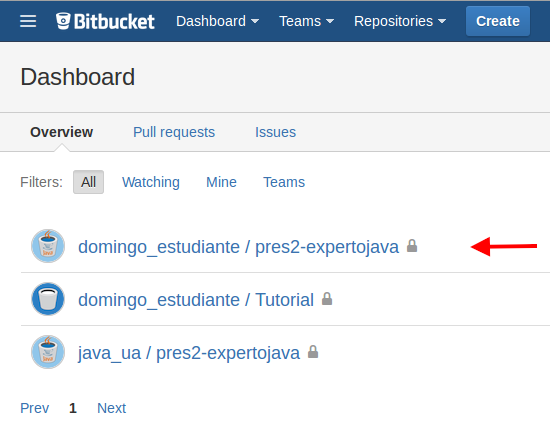
Copia el repositorio en tu cuenta, haciendo un fork del mismo. Para ello entra en el repositorio, pincha en los puntos suspensivos que hay en la esquina superior izquierda y escoge la opción Fork
El repositorio se copia en tu cuenta:
-
Descárgalo en tu ordenador desde línea de comando. Ve al directorio en el que quieras descargarlo, por ejemplo
Escritorio, y haz ungit clone:$ cd Escritorio $ git clone https://<usuario>@bitbucket.org/<usuario>/pres2-expertojava.git -
Abre el proyecto en IntelliJ seleccionando la opción File > Open.
-
El proyecto se llama
agenday contiene la siguiente claseorg.expertojava.pres.Tarjetaque define una tarjeta de contacto de una agenda, con un nombre y un correo electrónico de tipoString, y un identificador de tipoInteger:package org.expertojava.pres; public class Tarjeta { Integer id; String nombre; String eMail; public Tarjeta(String nombre, String eMail) { this.nombre = nombre; this.eMail = eMail; } public void setId(Integer id) { this.id = id; } public Integer getId() { return id; } public String getNombre() { return nombre; } public String geteMail() { return eMail; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Tarjeta tarjeta = (Tarjeta) o; if (!eMail.equals(tarjeta.eMail)) return false; if (id != null ? !id.equals(tarjeta.id) : tarjeta.id != null) return false; if (!nombre.equals(tarjeta.nombre)) return false; return true; } @Override public int hashCode() { int result = nombre.hashCode(); result = 31 * result + eMail.hashCode(); return result; } @Override public String toString() { return "Tarjeta{" + "id=" + id + ", nombre='" + nombre + '\'' + ", eMail='" + eMail + '\'' + '}'; } } -
Debes completar la clase
Mainescribiendo un guarde cuatro tarjetas en unArrayListy después lo recorra e imprima las tarjetas en la salida estándar. Cuando funcione correctamente haz un commit y sube los cambios a Bitbucket. -
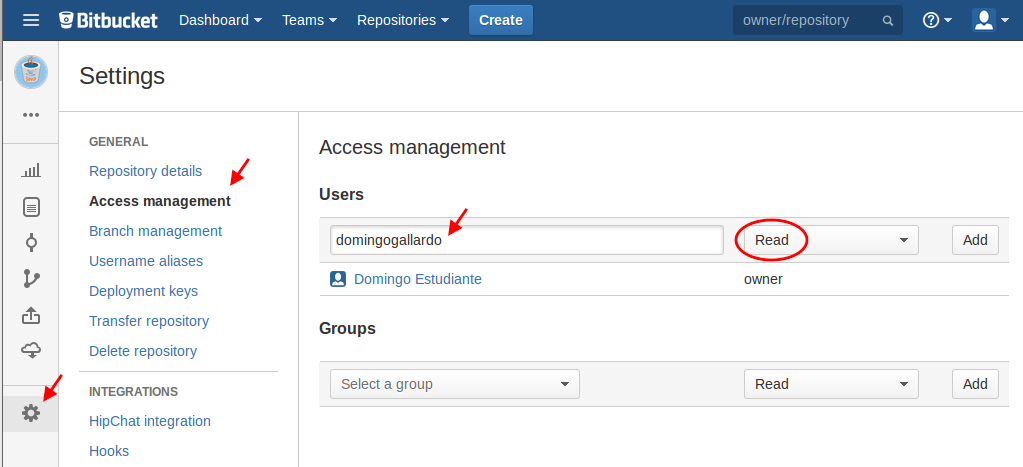
Para terminar debes compartir los repositorios creados en la sesión con el profesor de la asignatura. En Bitbucket selecciona la configuración del repositorio pulsando el botón Settings, la rueda dentada que hay abajo a la izquierda. Pulsa la opción Access management y añade al profesor de la asignatura con permiso de lectura:
2. (1,5 puntos) Caso de estudio
2.1. Introducción a Maven
Maven es una herramienta Java de gestión del proceso de desarrollo de proyectos software, que simplifica la complejidad de sus distintas partes: compilación, prueba, empaquetamiento y despliegue. Es una herramienta muy popular en proyectos open source que facilita:
-
La descarga de las librerías (ficheros JAR) externas de las que depende un proyecto
-
La construcción, prueba y despliegue del proyecto desarrollado, produciendo el fichero JAR o WAR final a partir de su código fuente y del fichero POM de descripción del proyecto
Maven se origina de hecho en la comunidad open source, en concreto en la Apache Software Foundation en la que se desarrolló para poder gestionar y minimizar la complejidad de la construcción del proyecto Jakarta Turbine en 2002. El diseñador principal de Maven fue Jason van Zyl, ahora en la empresa Sonatype. En 2003 el proyecto fue aceptado como proyecto de nivel principal de Apache. En octubre de 2005 se lanzó Maven 2. Desde entonces ha sido adoptado como la herramienta de desarrollo de software de muchas empresas y se ha integrado con muchos otros proyectos y entornos. Maven 3.0 se lanzó en octubre de 2010, siendo la mayoría de sus comandos compatibles con Maven 2.
Maven es una herramienta de línea de comando, similar a las herramientas habituales en Java como javac, jar o a proyectos como Ant. Aunque es posible utilizar Maven en IDEs como Eclipse o Glassfish, es muy útil conocer la utilización de Maven en línea de comandos porque es la base de cualquier adaptación gráfica.
Una de las características principales de Maven es su enfoque declarativo, frente al enfoque orientado a tareas de herramientas tradicionales como Make o Ant. En Maven, el proceso de compilación de un proyecto se basa en una descripción de su estructura y de su contenido. Maven mantiene el concepto de modelo de un proyecto y obliga a definir un identificador único para cada proyecto que desarrollemos, así como declarar sus características (URL, versión, librerías que usa, tipo y nombre del artefacto generado, etc.). Todas estas características deben estar especificadas en el fichero POM (Project Object Model, fichero pom.xml en el directorio raíz del proyecto). De esta forma es posible publicar el proyecto en un repositorio y ponerlo a disposición de la comunidad para que otros a su vez puedan usarlo como librería.
Maven impone una estructura de directorios en la que guardar los distintos elementos de un programa Java. En el caso de una aplicación web:
2.1.1. Instalación de Maven
Maven ya viene preinstalado en la máquina virtual del experto. La instalación en Linux es muy sencilla.
En primer lugar debemos descargar la última versión de la página web oficial y descomprimirla en algún directorio del sistema. En el caso de la MV, lo hemos instalado en /usr/local/maven.
Maven es una aplicación Java, y utiliza la variable JAVA_HOME para encontrar el path del JDK. También es necesario añadir el directorio bin de Maven al PATH del sistema. Se pueden definir en el fichero de configuración .profile de un usuario. En nuestro caso hemos modificado el único usuario de la MV expertojava. La variabel de entorno M2_HOME es utilizada por IntelliJ para localizar la ubicación de Maven. El código que hemos añadido ha sido este:
## Java
export JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
## Maven
export M2_HOME=/usr/local/maven
PATH=$PATH:/usr/local/maven/bin2.1.2. Dependencias de librerías en proyectos Java
Una característica del desarrollo de proyectos Java es la gran cantidad de librerías (ficheros JAR) necesarios para compilar y ejecutar un proyecto. Todas las librerías que se importan deben estar físicamente tanto en la máquina en la que se compila el proyecto como en la que posteriormente se ejecuta.
El proceso de mantener estas dependencias es tedioso y muy propenso a errores. Hay que obtener las librerías, cuidar que sean las versiones correctas, obtener las librerías de las que éstas dependen a su vez y distribuirlas todas ellas en todos los ordenadores de los desarrolladores y en los servidores en los que el proyecto se va a desplegar.
Por ejemplo, si nuestro proyecto necesita una implementación de JPA, como Hibernate, es necesario bajarse todos los JAR de Hibernate, junto con los JAR de los que depende, una lista de más de 15 ficheros. Es complicado hacerlo a mano y distribuir los ficheros en todos los ordenadores en los que el proyecto debe compilarse y ejecutarse. Para que Maven automatice el proceso sólo es necesario declarar en el fichero POM las siguientes líneas:
...
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>3.5.6-Final</version>
</dependency>
...Maven se encarga de descargar todas las bibliotecas necesarias para un proyecto cuando ejecutamos el comando mvn install. Las guarda en el denominado repositorio local, el directorio oculto .m2 en el directorio raíz del usuario.
2.1.3. El proceso de build de un proyecto
Los que hemos programado en C recordamos los ficheros Makefile en los que se especificaban las dependencias entre los distintos elementos de un proyecto y la secuencia de compilación necesaria para generar una librería o un ejecutable. En Java, el desarrollo de aplicaciones medianamente complejas es más complicado que en C. Estamos obligados a gestionar un gran número de recursos: código fuente, ficheros de configuración, librerías externas, librerías desarrolladas en la empresa, etc. Para gestionar este desarrollo es necesario algo de más nivel que las herramientas que proporciona Java (javac, jar, rmic, java, etc.)
¿En qué consiste el proceso de compilación y empaquetado en Java?. Básicamente en construir lo que Maven llama un artefacto (terminología de Maven que significa fichero) a partir de un proyecto Java definido con una estructura propia de Maven (apartado siguiente). Los posibles artefactos en los que podemos empaquetar un programa Java son:
- Fichero JAR
-
librería de clases o aplicación standalone. Contiene clases Java compiladas (.class) organizadas en paquetes, ficheros de recursos y (opcionalmente) otros ficheros JAR con bibliotecas usadas por las clases. En las aplicaciones enterprise, los EJB también se empaquetan en ficheros JAR que se despliegan en servidores de aplicaciones.
- Fichero WAR
-
aplicación web lista para desplegarse en un servidor web. Contiene un conjunto de clases Java, bibliotecas, ficheros de configuración y ficheros de distintos formatos que maneja el servidor web (HTML, JPG, etc.)
- Fichero EAR
-
aplicación enterprise que se despliega en un servidor de aplicaciones. Contiene bibliotecas, componentes EJB y distintas aplicaciones web (ficheros WAR).
Además, el ciclo de desarrollo de un proyecto es más complejo que esta construcción, ya que es necesario realizar un conjunto de tareas adicionales como gestionar las dependencias con librerías externas, integrar el código en repositorios de control de versiones (CVS, subversion o Git), lanzar tests o desplegar la aplicación en algún servidor de aplicaciones.
Podría pensarse que los entornos de desarrollo (Eclipse, Netbeans o IntelliJ) pueden dar una buena solución a la complejidad del proceso de construcción, pero no es así. Son imprescindibles para el desarrollo, pero no ayudan demasiado en la construcción del proyecto. La configuración de las dependencias se realiza mediante asistentes gráficos que no generan ficheros de texto comprensibles que podamos utilizar para comunicarnos con otros compañeros o equipos de desarrolladores y que pueden dar lugar a errores. El hecho de que sean entornos gráficos hacen complicado también usarlos en procesos de automatización y de integración continua.
2.1.4. Estructura de un proyecto Maven
La estructura de directorios de una aplicación web Maven es la que aparece en la siguiente figura.
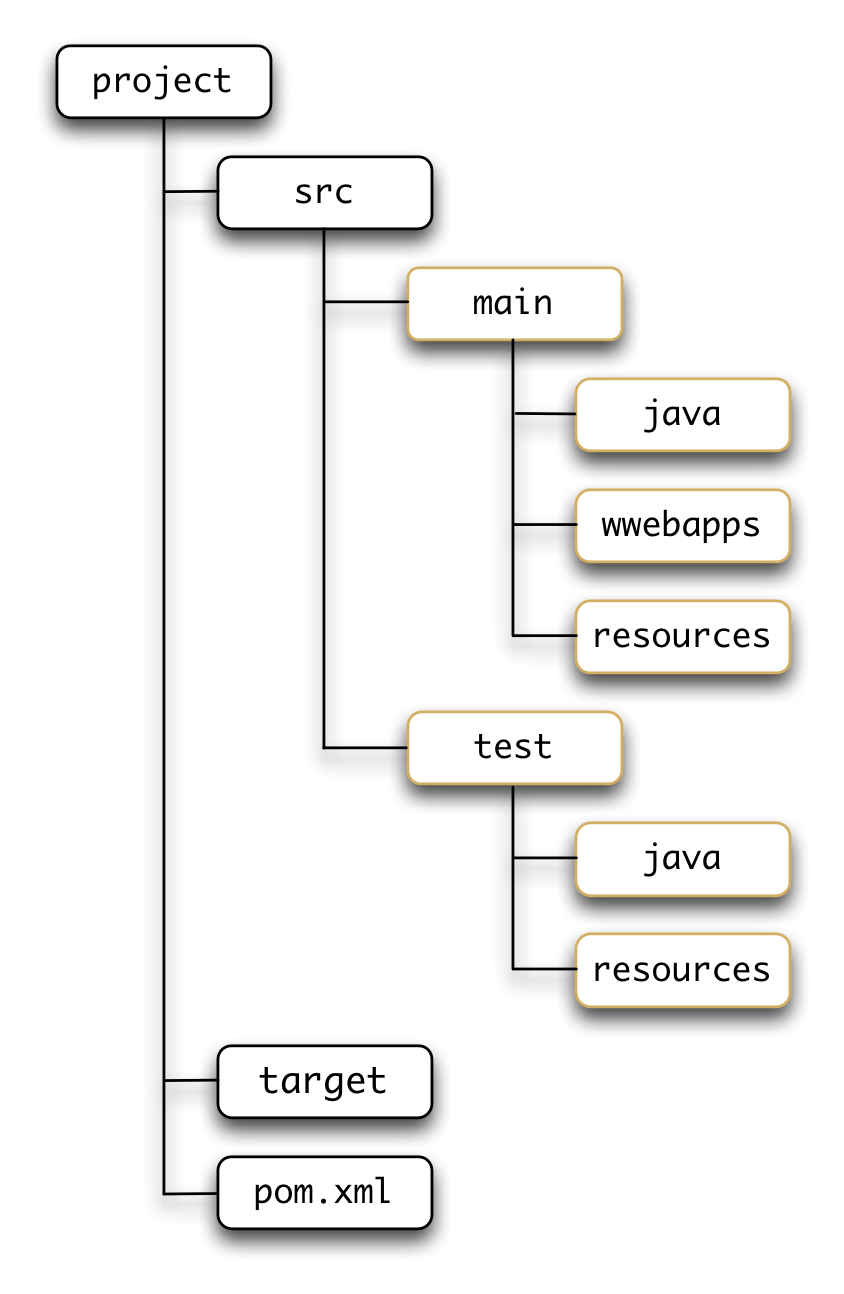
El nombre del directorio raíz no influye en el proyecto Maven, podemos cambiarlo sin que afecte a ninguno de sus elementos. En ese directorio raíz se definen los siguientes directorios:
-
src: código fuente del proyecto, tanto clases principales como clases de prueba. Dentro se define un directoriomainy otrotest, en donde van el código fuente de la aplicación y su código de prueba. Dentro de ambos se define un directoriojavacon los paquetes de código fuente de la aplicación, un directoriowebappscon los ficheros HTML, JSP y de configuración de la aplicación web y un directorioresourcesen el que se dejan ficheros de configuración. Ambos directorios se añaden al classpath. -
target: clases compiladas y artefactos generados a partir del código fuente y del resto de ficheros del directoriosrc. -
fichero
pom.xml: fichero con la descripción de los elementos necesarios para todo el ciclo de vida del proyecto: compilación, test, empaquetado, despliegue e instalación en el repositorio de la empresa.
2.1.5. POM: Project Object Model
El elemento más importante de un proyecto Maven, a parte de su estructura, es su fichero POM en el que se define completamente el proyecto. Este fichero define elementos XML preestablecidos que deben ser definidos para el proyecto concreto que estamos desarrollando. Viendo algunos de ellos podemos entender también más características de Maven.
Vamos a utilizar como ejemplo la versión inicial del POM del proyecto web que vamos a construir en un rato. Veamos su fichero pom.xml. Al comienzo nos encontramos con la cabecera XML y la definición del proyecto:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> (1)
<modelVersion>4.0.0</modelVersion>
<groupId>org.expertojava.jbibrest</groupId>
<artifactId>jbib-rest</artifactId>
<version>1.0-SNAPSHOT</version(2)
<packaging>war</packaging> (3)
<name>jbib-rest</name> (4)| 1 | La primera definición project xmlns es común para todos los ficheros pom.xml. En ella se declara el tipo de esquema XML y la dirección donde se encuentra el fichero de esquema XML. Se utiliza para que los editores de XML puedan validar correctamente el fichero. Esta sintaxis depende de la versión de Maven que se esté utilizando. |
| 2 | Después aparece la identificación del proyecto, en la que hay que definir el grupo que desarrolla el proyecto (groupId), el nombre del artefacto que genera el proyecto (artifactId), el tipo de empaquetamiento (packaging) y su versión (version). Estos campos representan las denominadas coordenadas del proyecto (hablaremos de ello más adelante). En nuestro caso son es.ua.jtech.proyint:jbib-modelo:jar:0.0.1-SNAPSHOT. |
| 3 | En el atributo packaging debemos definir el tipo de empaquetado del artefacto resultante. En nuestro caso, será un fichero WAR que contendrá toda la aplicación web. Este artefacto se generará cuando hagamos un mvn package. |
| 4 | Por último, el atributo name define el nombre lógico del proyecto. |
A continuación se definen algunas propiedades del proyecto, que se utilizarán en los distintos procesos de Maven. En nuestro caso, por ahora, sólo la codificación de caracteres que estamos utilizando en el código fuente de nuestro proyecto:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>Después vienen la definición de las dependencias del proyecto: librerías de las que dependen el proyecto. En nuestro caso:
-
Librerías Java EE:
javax:javaee-web-api:7.0 -
Librarías para logs logs_ :
log4j:log4j:1.2.17ycommons-logging:commons-logging:1.2 -
JUnit:
junit:junit:4.11
<dependencies>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-web-api</artifactId>
<version>7.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
</dependencies>Por último, definimos algunas características de los procesos de Maven que construyen el proyecto, definiendo parámetros para los pluging de Maven que se encargan de ejecutarlos.
<build>
<finalName>${project.name}</finalName> (1)
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId> (2)
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId> (3)
<artifactId>maven-war-plugin</artifactId>
<version>2.3</version>
<configuration>
<failOnMissingWebXml>false</failOnMissingWebXml>
</configuration>
</plugin>
<plugin>
<groupId>org.wildfly.plugins</groupId> (4)
<artifactId>wildfly-maven-plugin</artifactId>
<version>1.0.2.Final</version>
<configuration>
<hostname>localhost</hostname>
<port>9990</port>
</configuration>
</plugin>
</plugins>
</build>
</project>| 1 | En finalName definimos el nombre del artefacto generado cuando hagamos un mvn package. En nuestro caso será jbib-web.war. |
| 2 | En el plugin maven-compiler-plugin declaramos la versión de Java con la que queremos que se compilen las clases. En nuestro caso, la versión 1.7. |
| 3 | El plugin maven-war-plugin lo usamos únicamente para declarar que podemos no incluir un fichero web.xml en la aplicación. |
| 4 | Por último, el plugin de Maven de Wildfly wildfly-maven-plugin permite realizar el despliegue de la aplicación web en el servidor de aplicaciones. El despliegue se realiza con el comando mvn wildfly:deploy. |
POM padre
Es posible definir un conjunto de propiedades y dependencias en un único POM padre y cargarlas en distintos subproyectos, cada uno con su propio POM específico. Es útil para definir elementos comunes y evitar repetirlos en todos los POM. Por ejemplo, podríamos definir un POM en el que se declaren todas las librerías que se usan habitualmente por nuestros proyectos e incluir este POM en todos los proyectos utilizando herencia.
También se puede utilizar el POM padre como un POM agregador de varios subproyectos Maven. Cada subproyecto tiene su propio POM para construir su artefacto (por ejemplo JARs) y el POM padre coordina la construcción de todos ellos y, en su caso, la construcción de un WAR o un EAR en el que empaquetarlos.
En nuestro proyecto web no vamos a utilizar estas características, sino que vamos a definir un único POM en el que se especifica la generación de un único artefacto (el WAR con la aplicación web).
Maven define un super POM que por defecto es el padre de todos los POM. Allí se definen elementos comunes como la localización de los repositorios o la estructura de directorios por defecto de Maven. Se puede encontrar este super POM en el fichero llamado pom-4.0.0.xml en el JAR maven-2.2.1-uber.jar en el directorio lib de Maven.
Maven resuelve todas las relaciones de herencia entre POMs y genera internamente un POM efectivo (effective POM) en el que combinan todos los POMs que afectan a un determinado proyecto. Este POM efectivo es el que se utiliza para realizar la construcción del proyecto. Es posible consultar este POM efectivo con el comando:
mvn help:effective-pom2.1.6. Repositorios Maven
Los proyectos software modernos necesitan un gran número de clases y librerías definidas en otros proyectos. Esos proyectos pueden ser otros desarrollados por nosotros en la empresa o librerías open source bajadas de Internet.
La tarea de mantener las dependencias de un proyecto es complicada, tanto para las dependencias entre nuestros proyectos como las dependencias con otros proyectos open source disponibles en Internet. Por ejemplo, si queremos utilizar un framework como Spring, tendremos que descargarnos no sólo los JAR desarrollados en el proyecto, sino también un buen número de otras librerías open source que usa. Cada librería es un fichero JAR. ¿Qué pasa si alguna de esas librerías ya las estamos usando y las tenemos ya descargadas? O, peor aún, ¿Qué pasa si estamos usando otras versiones de esas librerías en nuestros proyectos? ¿Podremos detectar los posibles conflictos?. Maven se encarga de gestionar estas dependencias directas y las dependencias transitivas mediante los ficheros POM:
-
Descarga las librerías necesarias para construir el proyecto y los ficheros POM asociados a esas librerías
-
Resuelve dependencias transitivas, librerías que dependen de librerías de las que dependen nuestro proyecto
-
Resuelve conflictos entre librerías
Un elemento fundamental para gestionar las dependencias es poder identificar y nombrar un proyecto. En Maven el nombre de un proyecto se define mediante los siguientes elementos (que en Maven se denominan coordenadas):
- groupId
-
El grupo, compañía, equipo, organización, etc. Se utiliza una convención similar a la de los paquetes Java, comenzando por el nombre de dominio invertido de la organización que crea el proyecto. Por ejemplo, los
groupIdde la Apache Software Foundation comienzan conorg.apache - artifactId
-
Identificador único que representa de forma única el proyecto dentro del
groupId - version
-
Número de versión del proyecto, por ejemplo
1.3.5o1.3.6-beta-01 - packaging
-
Tipo de empaquetamiento del proyecto. Por defecto es
jar. Un tipojargenera una librería JAR, un tipowarse refiere a una aplicación web.
En Maven un proyecto genera un artefacto. El artefacto puede ser un fichero JAR, WAR o EAR. El tipo de artefacto viene indicado en el tipo de empaquetamiento del proyecto.
El nombre final del fichero resultante de la construcción del proyecto es por defecto: <artifactId>-<version>.<packaging>.
Por ejemplo, Apache ha desarrollado el proyecto commons-email que proporciona una serie de utilidades para la gestión de correos electrónicos en Java. Sus coordenadas son:
org.apache.commons:commons-email:1.1:jarEl artefacto (fichero JAR) generado por el proyecto tiene como nombre email-1.1.jar
Cuando ejecutamos Maven por primera vez veremos que descarga un número de ficheros del repositorio remoto de Maven. Estos ficheros corresponden a plugins y librerías que necesita para construir el proyecto con el que estamos trabajando. Maven los descarga de un repositorio global a un repositorio local donde están disponibles para su uso. Sólo es necesario hacer esto la primera vez que se necesita la librería o el plugin. Las siguientes ocasiones ya está disponible en el repositorio local.
La direcciones en las que se encuentran los repositorios son las siguientes:
- Repositorio central
-
El repositorio central de Maven se encuentra en http://repo1.maven.org/maven2. Se puede acceder a la dirección con un navegador y explorar su estructura.
- Repositorio local
-
El repositorio local se encuentra en el directorio
${HOME}/.m2/repository.
La estructura de directorios de los repositorios (tanto el central como el local) está directamente relacionada con las coordenadas de los proyectos. Los proyectos tienen la siguiente ruta, relativa a la raíz del repositorio:
/<groupId>/<artifactId>/<version>/<artifactId>-<version>.<packaging>Por ejemplo, el artefacto commons-email-1.1.jar, con coordenadas org.apache.commons:commons-email:1.1:jar está disponible en la ruta:
/org/apache/commons/commons-email/1.1/commons-email-1.1.jar]]2.1.7. Versiones
El estándar de Maven para los números de versiones es muy importante, porque permite definir reglas para gestionar correctamente las dependencias en caso de conflicto. El número de versión de un proyecto se define por un número principal, un número menor y un número incremental. También es posible definir un calificador, para indicar una versión alfa o beta. Los números se separan por puntos y el calificador por un guión. Por ejemplo, el número 1.3.5-alpha-03 define un número de versión principal 1, la versión menor 3, la versión incremental de 5 y el calificador de alpha-03.
Maven compara las versiones de una dependencia utilizando este orden. Por ejemplo, la versión 1.3.4 representa un build más reciente que la 1.0.9. Los clasificadores se comparan utilizando comparación de cadenas. Hay que tener cuidado, porque alpha10 es anterior a alpha2; habría que llamar al segundo alpha02.
Maven permite definir rangos de versiones en las dependencias, utilizando los operadores de rango exclusivos (, ) o inclusivos [, ]. Así, por ejemplo, si queremos indicar que nuestro proyecto necesita una versión de JUnit mayor o igual de 3.8, pero menor que 4.0, lo podemos indicar con el siguiente rango:
<version>[3.8,4.0)</version>Si una dependencia transitiva necesita la versión 3.8.1, esa es la escoge Maven sin crear ningún conflicto.
Es posible también indicar rangos de mayor que o menor que dejando sin escribir ningún número de versión antes o después de la coma. Por ejemplo, [4.0,) representa cualquier número mayor o igual que 4.0, (,2.0) representa cualquier versión menor que la 2.0 y [1.2] significa sólo la versión 1.2 y ninguna otra.
Cuando dos proyectos necesitan dos versiones distintas de la misma librería, Maven intenta resolver el conflicto, descargándose la que satisface todos los rangos. Si no utilizamos los operadores de rango estamos indicando que preferimos esa versión, pero que podríamos utilizar alguna otra. Por ejemplo, es distinto especificar 3.1 y [3.1]. En el primer caso preferimos la versión 3.1, pero si otro proyecto necesitara la 3.2 Maven se descargaría esa. En el segundo caso exigimos que la versión descargada sea la 3.1. Si otro proyecto especifica otra versión obligatoria, por ejemplo 3.2, entonces el proyecto no se compilará.
Es posible utilizar la palabra SNAPSHOT en el número de versión para indicar que es una versión en desarrollo y que todavía no está lanzada. Se utiliza internamente en los proyectos en desarrollo. La idea es que antes de que terminemos el desarrollo de la versión 1.0 (o cualquier otro número de versión), utilizaremos el nombre 1.0-SNAPSHOT para indicar que se trata de "1.0 en desarrollo".
La utilización de la palabra SNAPSHOT en una dependencia hace que Maven descargue al repositorio local la última versión disponible del artefacto. Por ejemplo, si declaramos que necesitamos la librería foo-1.0-SNAPSHOT.jar cuando construyamos el proyecto Maven intentará buscar en el repositorio remoto la última versión de esta librería, incluso aunque ya exista en el repositorio local. Si encuentra en el repositorio remoto la versión foo-1.0.-20110506.110000-1.jar (versión que fue generada el 2011/05/06 a las 11:00:00) la descarga y sustituye la que tiene en el local. De forma inversa, cuando ejecutamos el goal install y se despliega el artefacto en el servidor remoto, Maven sustituye el palabra SNAPSHOT por la fecha actual.
2.1.8. Gestión de dependencias
Hemos visto que una de las características principales de Maven es la posibilidad de definir las dependencias de un proyecto. En la sección dependencies del fichero POM se declaran las librerías necesarias para compilar, testear y ejecutar nuestra aplicación. Maven obtiene estas dependencias del repositorio central o de algún repositorio local configurado por nuestra empresa y las guarda en el directorio .$HOME/.m2/repository. Si utilizamos la misma librería en un varios proyectos, sólo se descargará una vez, lo que nos ahorrará espacio de disco y tiempo. Y lo que es más importante, el proyecto será mucho más ligero y portable, porque no llevará incluidas las librerías que necesita para su construcción.
Ya hemos visto en apartados anteriores cómo se declaran las dependencias en el fichero POM. Cada dependencia se define de forma unívoca utilizando sus coordenadas. El mecanismo de declaración de las dependencias es el mismo para las dependencias de librerías externas como para las definidas dentro de la organización.
Para definir una dependencia hay que identificar también el número de versión que se quiere utilizar, utilizando la nomenclatura del apartado anterior. Por ejemplo, la siguiente dependencia especifica una versión 3.0 o posterior de hibernate.
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate</artifactId>
<version>[3.0,)</version>
</dependency>Un concepto fundamental en Maven es el de dependencia transitiva. En los repositorios no solo se depositan los artefactos generados por los proyectos, sino también el fichero POM del proyecto. Y en ese fichero se definen las dependencias propias del proyecto. Por ejemplo, junto con el artefacto hibernate-3.0.jar se encuentra el fichero POM hibernate-3.0.pom.xml en el que se definen sus propias dependencias, librerías necesarias para Hibernate-3.0. Estas librerías son dependencias transitivas de nuestro proyecto. Si nuestro proyecto necesita Hibernate, e Hibernate necesita estas otra librería B, nuestro proyecto también necesita (de forma transitiva) la librería B. A su vez esa librería B tendrá también otras dependencias, y así sucesivamente.
Maven se encarga de resolver todas las dependencias transitivas y de descargar al respositorio local todos los artefactos necesarios para que nuestro proyecto se construya correctamente.
Otro elemento importante es el ámbito (scope) en el que se define la dependencia. El ámbito por defecto es compile y define librerías necesarias para la compilación del proyecto. También es posible especificar otros ámbitos. Por ejemplo test, indicando que la librería es necesaria para realizar pruebas del proyecto:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.8.1</version>
<type>jar</type>
<scope>test</scope>
</dependency>Otros ámbitos posibles son provided y runtime. Una dependencia se define provided cuando es necesaria para compilar la aplicación, pero que no se incluirá en el WAR y no será desplegada. Por ejemplo las APIs de servlets:
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.4</version>
<scope>provided</scope>
</dependency>Las dependencias runtime son dependencias que no se necesitan para la compilación, sólo para la ejecución. Por ejemplo los drivers de JDBC para conectarse a la base de datos:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>3.1.13</version>
<scope>runtime</scope>
</dependency>Una herramienta muy útil es el informe de dependencia. Este informe se genera cuando se ejecuta el objetivo site. Maven construye un sitio web con información sobre el proyecto y coloca el informe en el fichero target/dependencies.html:
$ mvn siteEl informe muestra una lista de dependencias directas y transitivas y su ámbito.
2.1.9. El ciclo de vida de Maven
El concepto de ciclo de vida es central para Maven. El ciclo de vida de un proyecto Maven es una secuencia de fases que hay que seguir de forma ordenada para construir el artefacto final.
Las fases principales del ciclo de vida por defecto son:
- validate
-
valida que el proyecto es correcto y que está disponible toda la información necesaria
- process-resources
-
procesar el código fuente, por ejemplo para filtrar algunos valores
- compile
-
compila el código fuente del proyecto
- test
-
lanza los tests del código fuente compilado del proyecto utilizando el framework de testing disponible. Estos tests no deben necesitar que el proyecto haya sido empaquetado o desplegado
- package
-
empaqueta el código compilado del proyecto en un formato distribuible, como un JAR
- integration-test
-
procesa y despliega el paquete en un entorno en donde se pueden realizar tests de integración
- verify
-
lanza pruebas que verifican que el paquete es válido y satisface ciertos criterios de calidad install: instala el paquete en el repositorio local, para poder ser usado como librería en otros proyectos locales
- deploy
-
realizado en un entorno de integración o de lanzamiento, copia el paquete final en el repositorio remoto para ser compartido con otros desarrolladores y otros proyectos.
Todas estas fases se lanzan especificándolas como parámetro en el comando mvn. Si ejecutamos una fase, Maven se asegura que el proyecto pasa por todas las fases anteriores. Por ejemplo:
$ mvn installEsta llamada realiza la compilación, los tests, el empaquetado los tests de integración y la instalación del paquete resultante en el repositorio local de Maven.
|
Para un listado completo de todas las opciones de un comando |
2.1.10. Ejecución de tests
Los tests de unidad son una parte importante de cualquier metodología moderna de desarrollo, y juegan un papel fundamental en el ciclo de vida de desarrollo de Maven. Por defecto, Maven obliga a pasar los tests antes de empaquetar el proyecto. Maven permite utilizar los frameworks de prueba JUnit y TestNG. Las clases de prueba deben colocarse en el directorio src/test.
Para ejecutar los tests se lanza el comando mvn test:
$ mvn test
[INFO] Scanning for projects...
...
-------------------------------------------------------
T E S T S
-------------------------------------------------------
Running org.expertojava.jbibrest.modelo.UsuarioTest
Tests run: 5, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.082 sec
Running org.expertojava.jbibrest.modelo.OperacionTest
Tests run: 5, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.141 sec
Tests run: 8, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.018 sec
Running org.expertojava.jbibrest.modelo.AvisoTest
Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.012 sec
Results :
Tests run: 19, Failures: 0, Errors: 0, Skipped: 0Maven compilará los tests si es necesario. Por defecto, los tests deben colocarse en el directorio src/test siguiendo una estructura idéntica a la estructura de clases del proyecto. Maven ejecutará todas las clases que comiencen o terminen con Test o que terminen con TestCase.
Los resultados detallados de los tests se producen en texto y en XML y se dejan en el directorio target/surefire-reports. Es posible también generar los resultados en HTML utilizando el comando:
$ mvn surefire-report:reportEl informe HTML se generará en el fichero target/site/surefire-report.html.
2.1.11. Uso de Maven en IntelliJ
IntelliJ reconoce los proyectos Maven a través del POM. Para importar un proyecto Maven en el IDE debes pulsar en el POM del proyecto. IntelliJ analiza el POM, descarga todas las librerías necesarias, identifica los directorios de la aplicación y los configura como directorios de fuentes, de tests, etc.
En la siguiente imagen vemos la estructura de directorios y las librerías de una versión inicial del proyecto web cargado. Podemos ver este panel en la parte superior izquierda de IntelliJ.
-
Bajo el directorio raíz vemos el directorio
srccon los subdirectoriosmainytest. También los ficherospom.xmlcon el POM de Maven y el fichero.gitignorecon los patrones a ignorar en el control de versiones. Y también se encuentra el directorio.ideay el ficherojbib-rest-expertojava.imlpropios del IDE. -
Debajo vemos las librerías declaradas en el POM y descargadas por Maven. IntelliJ las reconoce como librerías del proyecto y las incluirá en el paquete WAR cuando se realice el despliegue y ejecución del proyecto.
En la parte superior derecha de IntelliJ podemos ver el panel de Maven. Desde este panel podemos interactuar con el comando Maven.
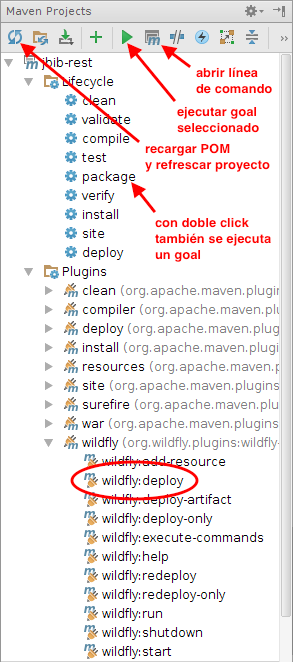
-
Para ejecutar un goal, por ejemplo
package, debemos seleccionar el objetivo y pulsar en el pequeño botón play, o hacer un doble click sobre el objetivo. Veremos que se abre en la parte inferior de IntelliJ un panel en el que se muestra la ejecución del comando Maven. El resultado es el mismo que si abrimos un terminal, nos movemos a la raíz del proyecto (que contiene el fichero POM) y ejecutamos desde línea de comando:$ mvn test -
El plugin
org.wildfly.pluginsproporciona goals adicionales relacionados con el despliegue del WAR en el servidor de aplicaciones. Los veremos más adelante. -
El icono Maven sirve para abrir una ventana de diálogo en la que podemos lanzar el comando Maven de forma textual, escribiendo los parámetros adicionales que necesitemos
-
El botón de refresco sirve para recargar el POM en IntelliJ y actualizar la estructura del proyecto y sus dependencias si hemos realizado algún cambio en el fichero.
Otra característica interesante de IntelliJ es que permite añadir dependencias en el POM de forma interactiva. Desde el fichero pom.xml pulsamos el botón derecho y seleccionamos Generate… (o pulsamos Alt+Insertar) y aparecerá el siguiente menú que permite modificar elementos del POM de forma interactiva:
Por ejemplo, seleccionando Dependency aparece una herramienta de búsqueda de librerías que permite filtrar por nombre y explorar las distintas versiones de las librerías disponibles en el repositorio central de Maven:
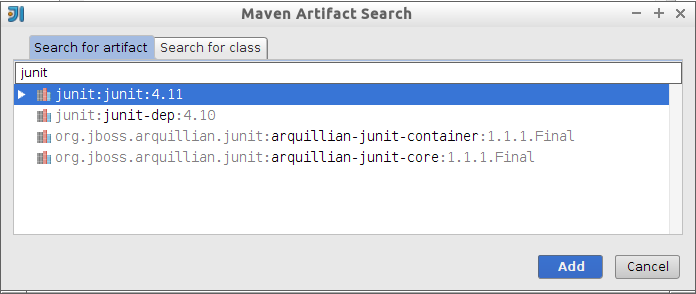
2.1.12. Maven con Git
Para crear un repositorio Git con un proyecto Maven, hay que hacer lo habitual: inicializar Git en la raíz del proyecto y añadir todos sus ficheros. Hay que tener cuidado de añadir en el repositorio sólo los ficheros fuente. Todos los ficheros de artefacto que crea Maven a partir de los ficheros fuente originales deben ser ignorados. Para ello basta con ignorar el directorio target.
El siguiente fichero .gitignore contiene las reglas que determinan los ficheros ignorados en un proyecto Maven en el que trabajamos con IntelliJ. Es recomendable ignorar también el fichero .idea/workspace.xml que contiene el estado de trabajo del IDE (pestañas abiertas, dimensiones de la ventana actual, etc.).
.gitignore# ignore Maven generated target folders
target
# ignore IDEA files
.idea/workspace.xml2.2. Paso a paso: despliegue con Maven
El proyecto de aplicación web que vamos a desarrollar a lo largo del curso se compone de dos partes principales:
-
Una aplicación Java que se despliega en un servidor Java EE (WildFly) e implementa un API REST que proporciona la lógica de negocio
-
Una aplicación JavaScript que proporciona la interfaz de usuario que se ejecuta en el navegador
Vamos a comenzar a construir la aplicación Java, un artefacto WAR que contendrá distintos paquetes que iremos desarrollando a lo largo de estas sesiones.
Comenzaremos con una aplicación muy básica, similar a la que has desarrollado en la asignatura de Componentes Web, que contiene algunos elementos iniciales básicos:
-
Fichero JSP con un formulario que envía una petición a un servlet
-
Servlet que procesa los parámetros de la petición y gestiona algún error e invoca a una clase del modelo
-
Clase del modelo que implementa una sencilla funcionalidad y realiza una mínima gestión de errores
-
Logging
-
Tests
Todo esto en un proyecto Maven con un POM que permite generar el WAR y desplegarlo en el servidor WildFly.
La mayor parte de esta aplicación básica ya está preparada y subida a la cuenta java_ua en Bitbucket, lista para que hagas un fork, te la descargues y comiences a trabajar con ella. Vamos a hacerlo paso a paso:
-
Haz un fork en tu cuenta de Bitbucket del proyecto
java_ua/jbibrest-proyint-expertojava -
Descarga a tu ordenador este proyecto recién copiado. Puedes usar un
git clonedesde el terminal o la opción de IntelliJ Check out from Version Control > Git: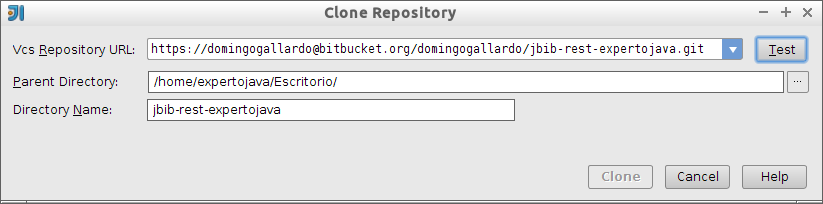
-
Vamos a comenzar probando a desplegar la aplicación web desde línea de comando. Abre dos terminales. En uno lanza WildFly con el comando:
$ standalone.shCuando haya arrancado WildFly, en el otro terminal muévete al directorio donde te has descargado el proyecto y ejecuta el goal
wildfly:deploy. Verás cómo el proyecto se compila, pasan los tests definidos y se despliega correctamente en el servidor de aplicaciones:$ cd jbib-rest-expertojava $ mvn wildfly:deploy [INFO] ------------------------------------------------------------------------ [INFO] Building jbib-rest 1.0-SNAPSHOT [INFO] ------------------------------------------------------------------------ ... ------------------------------------------------------- T E S T S ------------------------------------------------------- Running org.expertojava.jbibrest.modelo.NombreTest Tests run: 2, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.081 sec Results : Tests run: 2, Failures: 0, Errors: 0, Skipped: 0 [INFO] [INFO] --- maven-war-plugin:2.3:war (default-war) @ jbib-rest --- [INFO] Packaging webapp [INFO] Assembling webapp [jbib-rest] in [/home/expertojava/Escritorio/jbibrest-proyint-expertojava/target/jbib-rest] [INFO] Webapp assembled in [99 msecs] [INFO] Building war: /home/expertojava/Escritorio/jbibrest-proyint-expertojava/target/jbib-rest.war [INFO] --- wildfly-maven-plugin:1.0.2.Final:deploy (default-cli) @ jbib-rest --- ... [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 7.519 s [INFO] Finished at: 2014-10-26T19:36:24+01:00 [INFO] Final Memory: 15M/128M [INFO] ------------------------------------------------------------------------ -
Probamos ahora la aplicación desplegada. En un navegador accede a la URL http://localhost:8080/jbib-rest/ en la que estará respondiendo la aplicación. Aparecerá un sencillo formulario con el que puedes comprobar que la aplicación está funcionando. Rellénalo y pulsa Enviar. Verás la petición en la URL y la página resultante con un saludo.
-
Prueba a editar la URL de la petición a mano, cambiando algunos parámetros:
http://localhost:8080/jbib-rest/holamundo?nombre=Leia&edad=22&genero=mujer -
Prueba a introducir parámetros erróneos como un género que no existe o una edad negativa. En algunos casos el servlet detectará el error y devolverá un error 400 (BAD REQUEST) y en otros el error se detectará en la clase Java que implementa la lógica de negocio y se generará una excepción en tiempo de ejecución y un mensaje en el log. El fichero con los mensajes del log tiene la ruta
/home/expertojava/errors.log. -
En IntelliJ repasa el código de la aplicación:
-
El fichero
index.jspensrc/main/webapp -
El servlet
org.expertojava.jbibrest.HolaMundo.javaensrc/main/java/ -
La clase de modelo
org.expertojava.jbibrest.modelo.Nombretambién en el directorio de fuentesPiensa las siguientes preguntas sobre la aplicación: ¿Quién construye la cadena de saludo? ¿Qué parámetros hay que pasar? ¿Qué prerequisitos deben cumplir esos parámetros? ¿Desde dónde se invoca a esa construcción? ¿Quién, qué códigos de error HTTP se devuelven y en qué casos?
-
-
Los tests merecen mención especial. Son muy sencillos, se encuentran en el fichero
org.expertojava.jbib.modelo.NombreTest.javaen el directoriosrc/test/java. Comprueban el métodogetNombre()del modelo. El nombre de los tests sigue el convenio nombreFunciónShouldresultadoWhencondiciónInicial :@Test public void getNombreShouldReturnSrWhenHombre() throws Exception { Nombre nombre = new Nombre("Jack", 40, Genero.hombre); String nombreStr = nombre.getNombre(); assertTrue(nombreStr.equals("Sr. Jack (40 años)")); } @Test public void getNombreShouldReturnSraWhenMujer() throws Exception { Nombre nombre = new Nombre("Kate", 30, Genero.mujer); String nombreStr = nombre.getNombre(); assertTrue(nombreStr.equals("Sra. Kate (30 años)")); } } -
Elimina la aplicación WAR desplegada haciendo:
$ mvn wildfly:undeploy
|
Para comprobar si el WAR está desplegado puedes conectarte a la URL: http://localhost:9990/, entrar en la consola de administración del servidor y seleccionar Runtime > Manage Deployments. Desde esa pantalla puedes gestionar las aplicaciones desplegadas. |
-
Termina deteniendo el servidor WildFly haciendo Ctrl+c en el terminal
2.3. Paso a paso: despliegue con IntelliJ
Veamos ahora cómo hacer el despliegue de la aplicación web usando IntelliJ.
-
Empezamos abriendo el proyecto IntelliJ
jbib-rest-expertojava(en el directoriojbibrest-proyint-expertojava). En el repositorio Git se ha guardado también el fichero.ideaque hay en la raíz del directorio, por lo que IntelliJ reconoce el proyecto y sus características. En el caso en que no estuviera este fichero habría que importarlo como un proyecto Maven, haciendo un doble click en el fichero POM. -
Creamos una configuración de ejecución del tipo JBoss Server > Local. Le ponemos como nombre
jbib-rest, seleccionamos JBoss 8.1.0.Final como servidor de aplicaciones. Pulsamos en la pestaña de Deployment y en el símbolo + seleccionamos Artifact… > jbib-rest-expertojava:war. Seleccionamos también Hot Swap Classes para permitir desplegar en caliente las clases compiladas en las que hemos realizado cambios y marcamos la casilla Share para que se guarde en el repositorio Git la configuración de ejecución: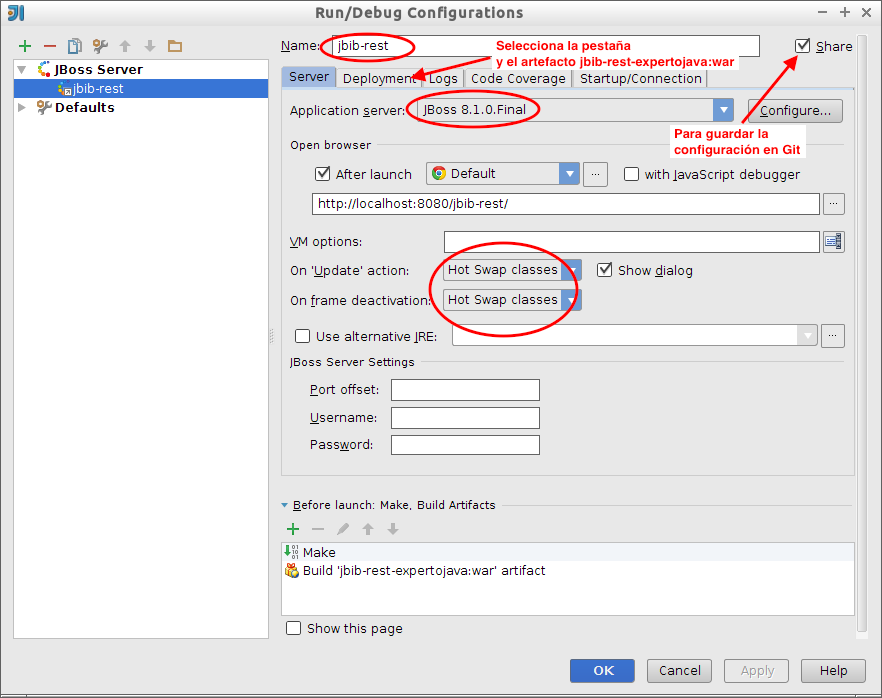
-
Ahora pulsamos el botón de ejecución junto al desplegable con el nombre de la configuración de ejecución.
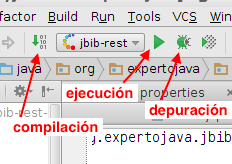
Veremos cómo se abre en la parte inferior el panel Run. Está dividido en dos zonas. En la zona derecha se muestra la consola del servidor de aplicaciones seleccionado en la configuración de ejecución (WildFly). El servidor se pone en marcha y vemos los mensajes que va escribiendo. En la parte izquierda está el panel de herramientas relacionadas con el despliegue de aplicación.
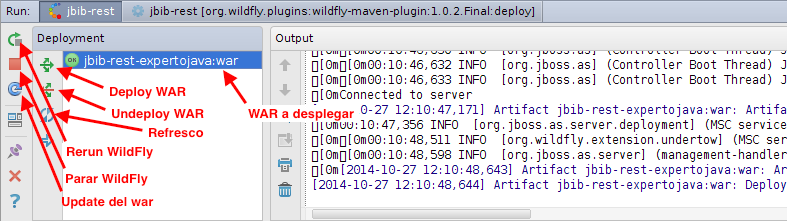
En la configuración de ejecución hemos seleccionado el artefacto
jbib-rest-expertojava:war. IntelliJ compila las clases, las deja en el directoriotarget/classesy las empaqueta en el ficherojbib-rest.warentarget(IntelliJ reutiliza los mismos directorios de Maven). Después lo despliega en WildFly y abre una navegador en la página definida en la configuración de ejecución. Si todo ha funcionado bien, veremos la página con el formulario. Cuando introducimos los datos vemos el saludo. -
Desde IntelliJ también podemos usar el panel de Maven y desplegar (o seleccionar cualquier otro objetivo) con él el WAR. Por ejemplo, una vez desplegado el WAR podemos pulsar en el objetivo Plugins > wildfly > wildfly:undeploy para eliminar el WAR. Cuando lo hacemos se abre una nueva pestaña en el panel de consola en la que aparece la salida del comando Maven. Podemos intentar cargar la página inicial para comprobar que la aplicación ya no está disponible.
|
Después de modificar el estado de un artefacto (desplegarla o eliminarla) con Maven, su estado no se actualiza correctamente en el panel de ejecución. Debes pulsar el botón de refresco para actualizarlo. |
2.4. Caso de estudio y modelo de dominio
2.4.1. Introducción
A partir de un supuesto básico de la gestión de una biblioteca, vamos a crear un caso de estudio completo que evolucionará conforme estudiemos las diferentes tecnologías de la plataforma Java Enterprise.
El objetivo de esta sesión es introducir el caso de estudio que vamos a desarrollar, obtener una visión global del proyecto, fijando los casos de uso y requisitos principales y definiendo el esqueleto inicial del problema.
2.4.2. Historias de usuario
El Instituto de Educación Secundaria "jUA" nos ha encargado que desarrollemos una aplicación para la gestión de los préstamos realizados en la biblioteca del centro, lo que implica tanto una gestión de los libros como de los alumnos y profesores que realizan estos prestamos.
Tras una serie de entrevistas y reuniones con diferente personal del centro, hemos decidido hacer un prototipo inicial que servirá para probar el funcionamiento de la parte de la aplicación destinada a los clientes de la biblioteca: profesores y alumnos que van a poder solicitar préstamos de libros a través de la aplicación.
En concreto, las características que vamos a implementar en este prototipo serán las siguientes:
-
La biblioteca contiene libros. El sistema debe guardar toda la información necesaria de cada libro: su título, autor, ISBN, etc. Puede existir más de un ejemplar de un mismo libro. Se quiere también guardar la información propia de cada ejemplar: fecha de adquisición, defectos que pueda tener, etc.
-
Los usuarios de la biblioteca (profesores y alumnos) utilizarán la aplicación para realizar una serie de acciones sobre estos libros: consultar su disponibilidad, pedirlos prestados, consultar la lista de libros prestados, etc. En concreto:
-
Pedir prestado un ejemplar disponible (que el bibliotecario le entregará cuando se pase por el mostrador)
-
Consultar el estado de los libros y sus ejemplares: un libro puede estar prestado (en sala, en casa o en el departamento) o disponible.
-
Consultar los libros que tiene prestados
-
Consultar los libros de la biblioteca
-
-
La fecha de devolución del ejemplar dependerá de si el usuario es alumno o profesor y empezará a contar a partir del momento en que el libro se toma prestado con la aplicación. El número máximo de libros que puede tener en préstamo un usuario dependerá también de si es profesor o alumno.
-
Existe un número máximo de préstamos y reservas (operaciones) que puede hacer un usuario. La suma del número de préstamos y reservas de un usuario no puede sobrepasar este máximo. El máximo depende de si el usuario es un profesor o un alumno.
-
El estado por defecto de un usuario es activo. Cuando el usuario se retrasa en la devolución de un préstamo pasa a estado moroso. En ese estado no puede pedir prestado ni reservar ningún otro libro. Cuando devuelve el libro se le crea una multa y pasa a estado multado.
-
De la multa nos interesa saber la fecha de inicio y de finalización de la misma. La finalización de la multa dependerá del tipo de usuario. Nos han comunicado que quieren mantener un histórico de las multas que ha tenido un usuario. Cuando pasa la fecha de finalización, el estado del usuario vuelve a activo.
Estas funcionalidades las vamos a convertir más adelante en casos de uso y las vamos a implementar a lo largo del curso, conforme vaya avanzando el proyecto de integración.
2.4.3. Requisitos de información (IRQ)
Los requisitos de información resumen la información persistente que nos interesa almacenar relacionada con el sistema.
Respecto a un usuario, nos interesa almacenar:
-
Tipo de usuario: profesor, alumno
-
Login y password
-
Nombre y apellidos
-
Correo electrónico
-
Lista de préstamos del usuario (actuales y pasados)
-
Estado de un usuario: activo, moroso o multado
-
Datos referentes a su dirección, como son calle, número, piso, ciudad y código postal.
-
Si el usuario es alumno, necesitaremos guardar quién es su profesor tutor
-
Si el usuario es profesor, necesitaremos el nombre de su departamento
Respecto a un libro, nos interesa almacenar:
-
ISBN
-
Título y autor
-
Número de páginas
-
Fecha de alta del libro
-
Número de ejemplares disponibles: cambiará conforme se presten y devuelvan ejemplares
-
Ejemplares de ese título
-
Tipo de finalización de la reserva: cancelada o préstamo
-
URI de la portada: dirección web de la imagen de donde se puede cargar la portada
Queremos que la aplicación realice también recomendaciones de libros, de forma que para un libro a prestar se muestre una lista de libros relacionados. Esta lista de libros se obtendrá a partir de los libros que han tomado prestado usuarios que han tomado prestado el libro original.
Para ello cada vez que un usuario tome prestado un libro -libro1- se incrementará en 1 la frecuencia de la pareja (libro1, libro-X) para todos los _libro-X- que ha tomado prestado el usuario en el curso actual. De esta forma obtendremos una tabla de frecuencias de préstamo conjunto de libros.
Respecto a un ejemplar, almacenaremos:
-
Identificador del ejemplar
-
Libro al que pertenece el ejemplar
-
Fecha de adquisición
-
Observaciones: texto sobre el estado del ejemplar
Un préstamo relaciona ejemplares y usuarios. En cada préstamo guardaremos:
-
Identificador del préstamo _ Ejemplar del préstamo _ Usuario del préstamo
-
Fecha de préstamo
-
Fecha en la que debería devolverse
-
Fecha en la que se ha devuelto en realidad
Cuando un usuario se retrase en la devolución de un libro, se le creará una multa. Nos han comunicado que quieren mantener un histórico de las multas que ha tenido un usuario. De cada multa nos interesa saber:
-
Usuario que tiene la multa
-
Fecha de inicio
-
Fecha de finalización
-
Identificador del préstamo causante de la multa
2.4.4. Casos de uso
Los casos de uso son bastante sencillos. Vamos a centrarnos sólo en la parte del usuario registrado en la biblioteca, dejando para otro momento la parte de la aplicación del bibliotecario en la que se realizaría una gestión (altas, bajas y modificaciones) de los libros, ejemplares y usuarios. El siguiente esquema muestra los casos de uso de un usuario logeado en el sistema:
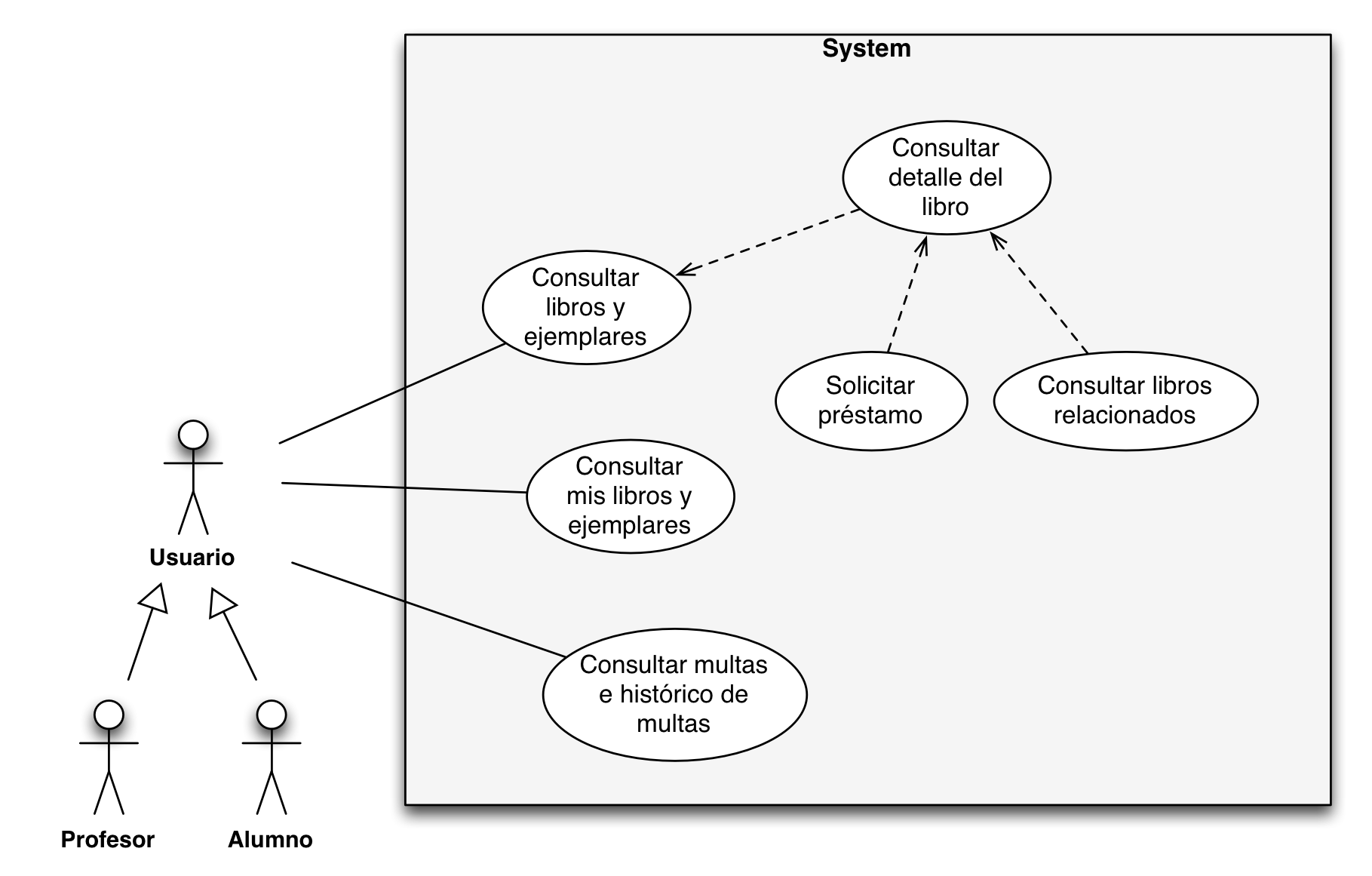
El usuario podrá consultar los libros disponibles en la biblioteca y obtener más información sobre aquellos en los que esté interesado, accediendo a la pantalla de detalle del libro. Desde esta pantalla de detalle podrá solicitar el préstamo del libro y ver la información de libros recomendados relacionados con el actual.
Para hacerse una idea mejor del funcionamiento de la aplicación es conveniente hacer diseños iniciales o mockups de estas pantallas, junto con un esquema de navegación de las mismas. Los vemos a continuación.
Esquema de navegación:
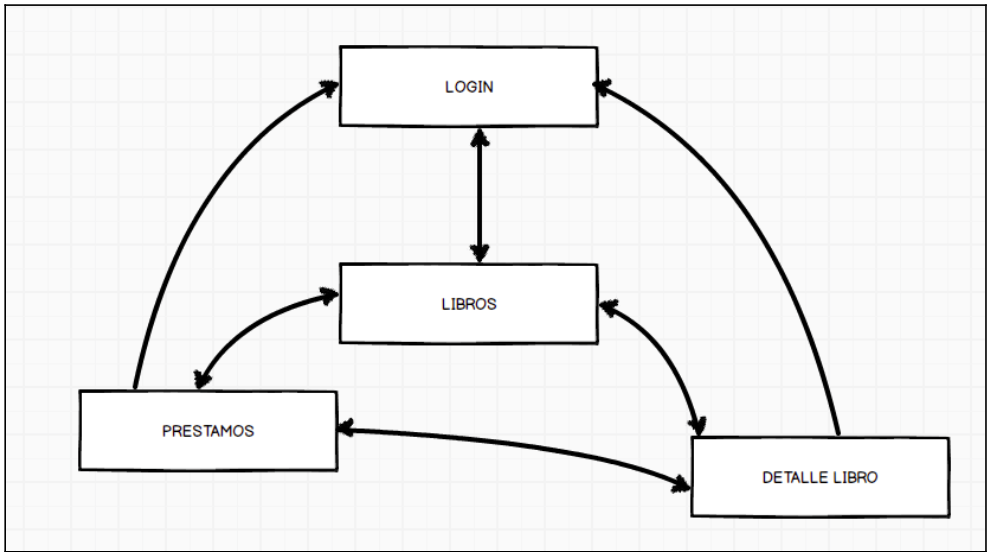
Pantalla con el listado de libros:
Pantalla con el detalle de libro:
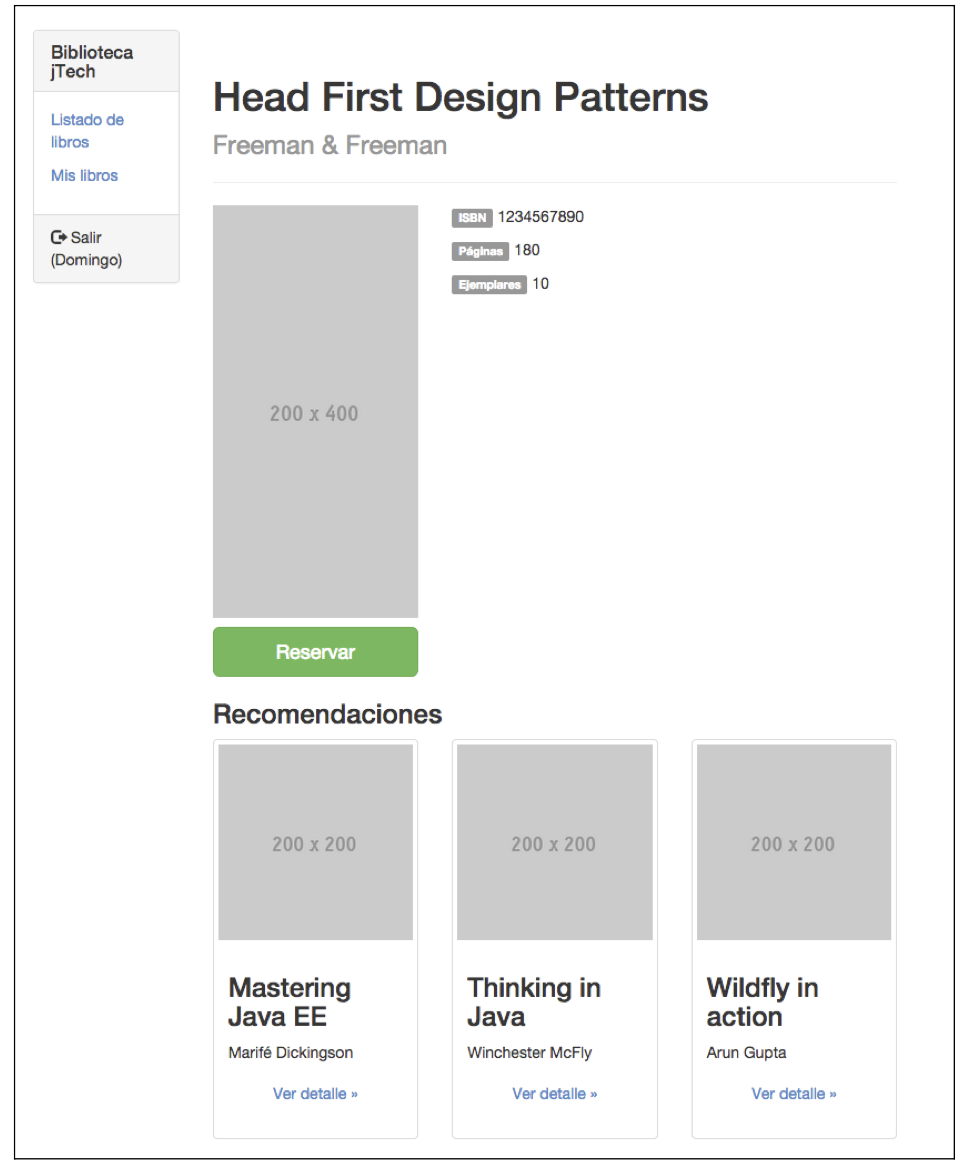
Pantalla con los libros que tiene prestados un usuario:
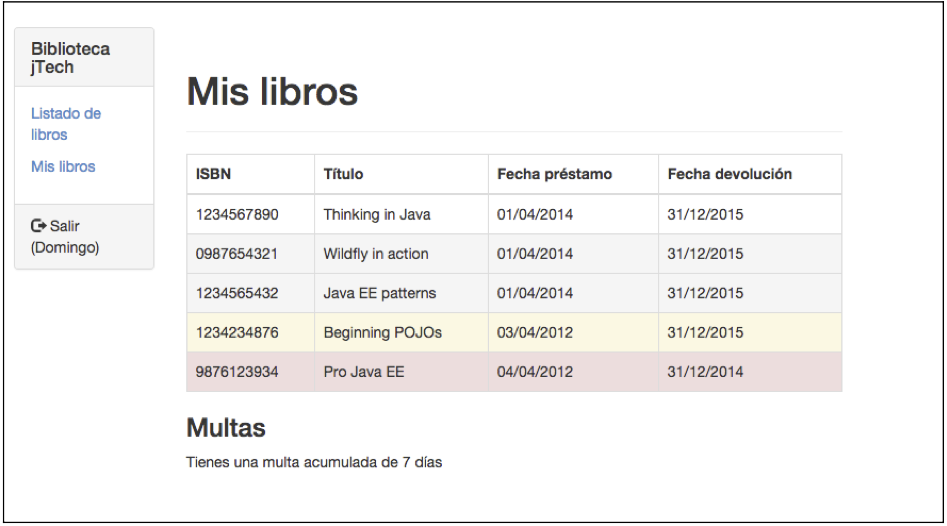
Estos son bocetos iniciales de pantallas. A partir de ellas, del modelo de datos y de las reglas de negocio que veremos más adelante, diseñaremos el API REST con las funcionalidades que ofrecerá nuestro servicio.
2.4.5. Requisitos de restricción (CRQ)
Podemos resumir en la siguiente tabla las restricciones a aplicar a los casos de uso anteriores:
| Tipo de usuario | Número máximo de préstamos | Días de préstamo |
|---|---|---|
Alumno |
5 |
7 |
Profesor |
8 |
30 |
El máximo de libros prestados de un alumno es 6. Los libros prestados los tiene que devolver antes de 7 días.
En el momento que un usuario tenga una demora en la devolución de un préstamo, se considerará al usuario moroso y se le impondrá una penalización del doble de días de desfase durante los cuales no podrá ni reservar ni realizar préstamos de libros.
2.4.6. Modelo de clases
A partir de los requisitos y tras unas sesiones de modelado, hemos llegado al siguiente modelo de clases conceptual representado mediante el siguiente diagrama UML:
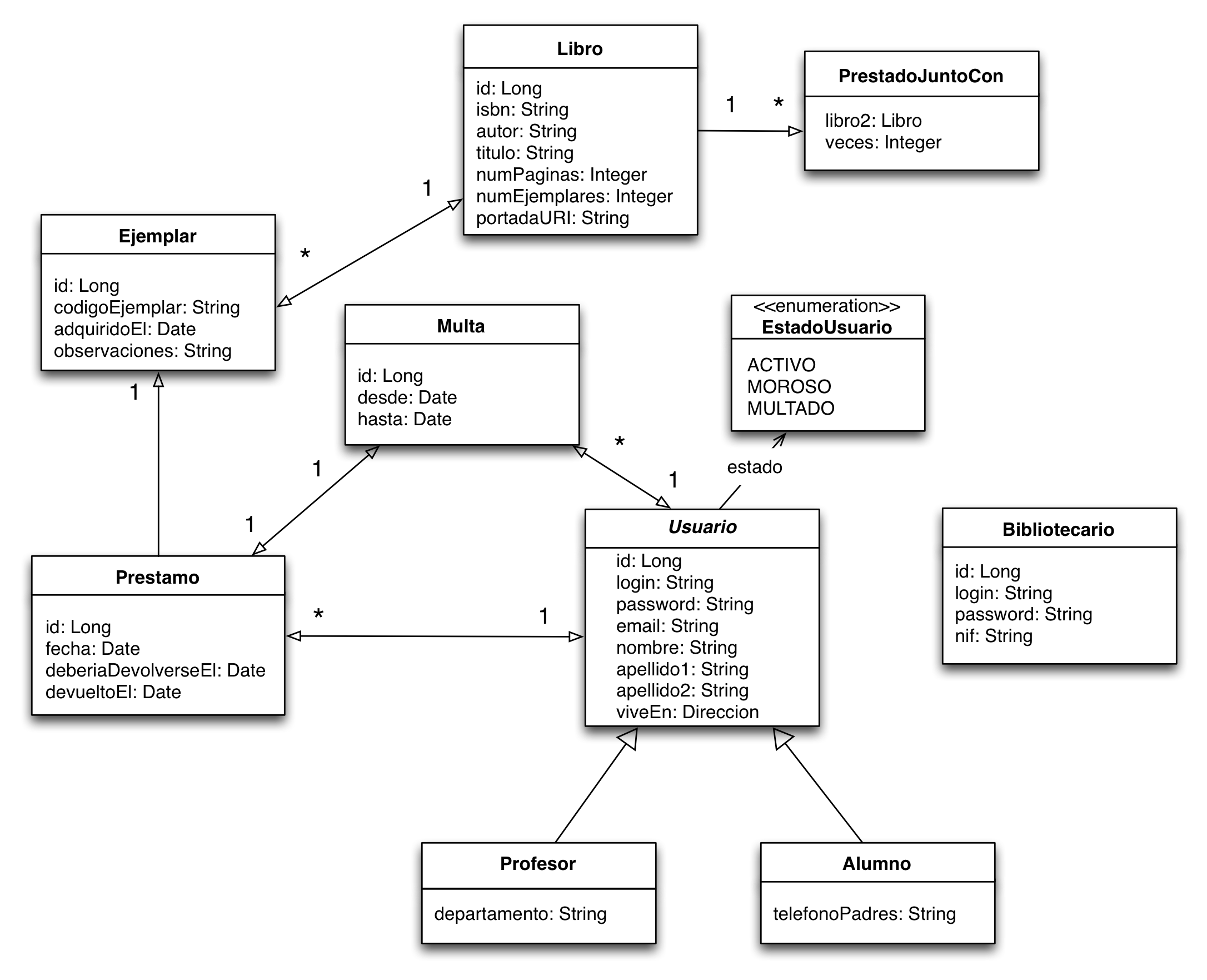
Utilizaremos un modelo de clases como punto de partida del modelo de datos. En la siguiente sesión construiremos el modelo de datos basándonos en este modelo de clases y utilizando JPA (Java Persistence API). Veremos que este enfoque se denomina ORM (Object Relational Mapping), porque permite definir una relación directa (mapping) entre clases Java y tablas de la base de datos. La relación entre clases Java y tablas se define por medio de anotaciones JPA añadidas en el código fuente de las clases.
Vemos que casi todas las clases tienen un atributo id de tipo Long. Será la clave primaria de la tabla asociada a la clase y será generado automáticamente por la base de datos. Durante un tiempo de la vida del objeto, antes de ser insertado en la base de datos, este identificador va a ser null. Tenemos que tener en cuenta esto a la hora de definir correctamente los métodos equals y hashCode.
|
¿Por dónde empezamos al hacer el diseño de la aplicación? ¿Por los datos o por las clases? Podemos empezar modelando los datos o las clases, y ambos modelos serán casi semejantes. Normalmente, la elección viene dada por la destreza del analista, si se siente más seguro comenzando por los datos, o con el modelo conceptual de clases. Otra opción es el modelado en paralelo, de modo que al finalizar ambos modelos, podamos compararlos y validar si hemos comprobado todas las restricciones. Daremos más detalles en la siguiente sesión. |
2.5. Desarrollo e implementación (parte guiada, 0,5 puntos)
El objetivo de la sesión de hoy es crear todas las clases anteriores (clases de dominio) en el paquete org.expertojava.jbibrest.modelo del proyecto inicial que ya te has descargado y has probado que funciona correctamente. Estas clases definirán los tipos de datos básicos que utilizaremos para trabajar con la capa de persistencia y de lógica de negocio de nuestra API REST.
A lo largo de las siguientes sesiones del proyecto construiremos nuevos módulos necesarios para el API REST con los métodos de negocio y la aplicación JavaScript que construye la interfaz de usuario.
Comentamos a continuación los pasos a seguir para desarrollar el esqueleto del dominio del proyecto, que incluye la clase Libro, algunas clases auxiliares, excepciones y pruebas. Al final de esta guía paso a paso tendrás una versión inicial del programa. Deberás entonces terminar de implementar el resto.
Es muy importante en esta parte guiada que no te limites a copiar y pegar el código, sino que reflexiones sobre lo que hace.
2.5.1. Clase de domino Libro
Las clases de dominio representan las entidades que van a hacerse persistentes y con las que van a trabajar las capas de persistencia y de lógica de dominio de la aplicación. En las siguientes sesiones, cuando veamos JPA, veremos cómo se podrán definir la capa de persistencia de la aplicación directamente a partir de estas clases y cómo se utilizarán para encapsular los datos pasados como parámetros y devueltos por las funciones de la capa de negocio implementadas por componentes EJB.
Para asegurarnos que todos nuestros objetos de dominio tienen una estructura común, definimos una clase abstracta, que será la clase padre de todas las clases de dominio. Definiremos en esa clase los métodos equals() y hashCode() para obligar a que las clases hijas implementen y redefinan la igualdad. Estos métodos son necesarios para poder guardar los objetos en colecciones.
public abstract class ClaseDominio {
private static final long serialVersionUID = 1L;
public abstract boolean equals(Object object);
public abstract int hashCode();
}Todas las entidades las vamos a definir dentro del paquete org.expertojava.jbibrest.modelo. Cada objeto de dominio se compone de sus atributos, relaciones y de todos los getter/setter que encapsulan al objeto.
Vamos a definir las clases Libro y Ejemplar. Define también la otra clase (pero vacía, sin incluir código) PrestadoJuntoCon para que no haya errores de compilación.
Empezamos por la clase Libro:
package org.expertojava.jbibrest.modelo;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import java.util.HashSet;
import java.util.Set;
public class Libro extends ClaseDominio {
Set<PrestadoJuntoCon> prestadoCon;
Set<Ejemplar> ejemplares;
private Long id;
private String isbn;
private String autor;
private String titulo;
private Integer numPaginas;
private Integer numEjemplares;
private String portadaURI;
private static Log logger = LogFactory.getLog(Libro.class);
public Libro(String isbn) {
this.isbn = isbn;
prestadoCon = new HashSet<PrestadoJuntoCon>();
ejemplares = new HashSet<Ejemplar>();
logger.debug("Nueva instancia de Libro: " + isbn);
}
public Long getId() { return id; }
public String getIsbn() {
return isbn;
}
public void setIsbn(String isbn) {
this.isbn = isbn;
}
public String getAutor() {
return autor;
}
public void setAutor(String autor) {
this.autor = autor;
}
public String getTitulo() {
return titulo;
}
public void setTitulo(String titulo) {
this.titulo = titulo;
}
public Integer getNumPaginas() {
return numPaginas;
}
public void setNumPaginas(Integer numPaginas) {
this.numPaginas = numPaginas;
}
public Integer getNumEjemplares() {
return numEjemplares;
}
public void setNumEjemplares(Integer numEjemplares) {
this.numEjemplares = numEjemplares;
}
public String getPortadaURI() {
return portadaURI;
}
public void setPortadaURI(String portadaURI) {
this.portadaURI = portadaURI;
}
public Set<PrestadoJuntoCon> getPrestadoCon() {
return prestadoCon;
}
public void setPrestadoCon(Set<PrestadoJuntoCon> prestadoCon) {
this.prestadoCon = prestadoCon;
}
public Set<Ejemplar> getEjemplares() {
return ejemplares;
}
public void setEjemplares(Set<Ejemplar> ejemplares) {
this.ejemplares = ejemplares;
}
// Dos libros son iguales cuando tienen el mismo ISBN
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Libro libro = (Libro) o;
if (!isbn.equals(libro.isbn)) return false;
return true;
}
@Override
public int hashCode() {
return isbn.hashCode();
}
@Override
public String toString() {
return "Libro{" +
"id=" + id +
", isbn='" + isbn + '\'' +
", autor='" + autor + '\'' +
", titulo='" + titulo + '\'' +
", numPaginas=" + numPaginas +
", numEjemplares=" + numEjemplares +
", portadaURI='" + portadaURI + '\'' +
'}';
}
}Y definimos también la clase Ejemplar:
package org.expertojava.jbibrest.modelo;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import java.util.Date;
import java.util.logging.Logger;
public class Ejemplar extends ClaseDominio {
private Long id;
private Libro libro;
private String codigoEjemplar;
private Date fechaAdquisicion;
private String observaciones;
private static Log logger = LogFactory.getLog(Ejemplar.class);
public Ejemplar(String codigoEjemplar, Libro libro) {
this.codigoEjemplar = codigoEjemplar;
this.libro = libro;
logger.debug("Nueva instancia de Ejemplar: " + codigoEjemplar);
}
public Long getId() {
return id;
}
public Libro getLibro() { return libro; }
public Date getFechaAdquisicion() {
return fechaAdquisicion;
}
public void setFechaAdquisicion(Date fechaAdquisicion) {
this.fechaAdquisicion = fechaAdquisicion;
}
public String getObservaciones() {
return observaciones;
}
public void setObservaciones(String observaciones) {
this.observaciones = observaciones;
}
// Dos ejemplares son iguales cuando tienen el mismo código
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Ejemplar ejemplar = (Ejemplar) o;
if (!codigoEjemplar.equals(ejemplar.codigoEjemplar)) return false;
return true;
}
@Override
public int hashCode() {
return codigoEjemplar.hashCode();
}
}Todos los métodos se pueden generar usando el asistente de IntelliJ, con la opción Generate….
Claves naturales y claves primarias autogeneradas
Es interesante hacer notar la forma en que están implementados los métodos hashCode y equals. Son métodos muy importantes porque son los que se utilizan para buscar en las colecciones. Los podemos generar con IntelliJ usando la opción Generate… > equals() and hashCode().
Para elegir los campos a usar en la comparación debemos tener en cuenta que el conjunto de todos ellos formen una clave única natural de los objetos de dominio, tal y como se explica en el esta nota de jBoss e Hibernate.
La ventaja de usar claves naturales frente a las claves generadas artificialmente (claves autogeneradas) para determinar la igualdad de objetos es que habrá veces que podemos no disponer de estas últimas. Las claves autogeneradas las genera normalmente la base de datos cuando hacemos persistente el objeto. Puede darse el caso que estemos trabajando con el objeto, lo insertemos en colecciones o realicemos alguna comparación con él y que no dispongamos de la clave primaria autogenerada.
También es importante que garanticemos que los campos que utilicemos en el equals siempre existan y nunca sean null. En el caso del Libro sólo hace falta un único campo: el ISBN.
El constructor lo podemos generar con la opción de IntelliJ Generate… > Constructor. En el constructor incluiremos todos aquellos atributos obligatorios que siempre van a existir en el objeto que no van ser null. Cuando utilicemos las clases de dominio para definir el modelo de datos (tablas de la base de datos) veremos que estos atributos definirán campos not null.
La próxima sesión, cuando realizemos el mapeado al modelo relacional, a la base de datos, comentaremos cómo trabajar con el identificador único autogenerado. En cada clase hay un campo id de tipo Long en el que se guardará la clave primaria autogenerada por la base de datos. Lo utilizaremos para garantizar la identidad de cada objeto y tener más flexibilidad. Pero es importante que esta identidad será sólo para trabajar con la base de datos. Desde el punto de vista de un objeto de dominio, la identidad debe estar basada en claves naturales propias del objeto.
Logging
Cuando estamos desarrollando la aplicación es cómodo poder ver sus mensajes de log en la consola, junto con los mensajes del servidor. Sería interesante modificar el fichero de configuración log4j.properties para que escribiera en la consola, en lugar de en un fichero auxiliar. Sin embargo, un bug de WildFly hace que no se muestren los logs si definimos como appender org.apache.log4j.ConsoleAppender.
Una forma de solucionarlo es eliminando los ficheros de configuración de logs en la aplicación web. Asegúrate de borrar los ficheros common-logging.properties y log4j.properties.
Donde sí podemos añadir los ficheros de configuración de logs es en el directorio de test, en concreto en test/resources. Los ponemos inicialmente en el nivel DEBUG:
org.apache.commons.logging.Log=org.apache.commons.logging.impl.Log4JLogger# Coloca el nivel root del logger en DEBUG (muestra mensajes de DEBUG hacia arriba)
# Añade appender A1
log4j.rootLogger=DEBUG, A1
# A1 se redirige a la consola
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.Threshold=DEBUG
#log4j.appender.A1.File=/home/expertojava/errores.log
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=[%d{dd/MM/yyyy HH:mm:ss}] - \
%p - %m %nPrimeros tests
Definimos los dos primeros test de la clase org.expertojava.jbibrest.model.LibroTest en el directorio src/test/java, con los que probamos el funcionamiento correcto de la igualdad en la clase Libro y la búsqueda en un HashSet de libros:
import org.junit.Test;
import java.util.HashSet;
import static org.junit.Assert.*;
public class LibroTest {
/* Comprobación de la búsqueda de un ejemplar en la lista
* de ejemplares de un libro
*/
@Test
public void testEquals() {
Libro libro1 = new Libro("123456789");
Libro libro2 = new Libro("123456789");
assertTrue(libro1.equals(libro2));
// Cambiando el ISBN de uno de ellos ya no son iguales
libro2.setIsbn("987654321");
assertFalse(libro1.equals(libro2));
}
/* Comprobación de la búsqueda de un ejemplar en la lista
* de ejemplares de un libro
*/
@Test
public void contieneEjemplarDespuesDeAñadirlo() {
Libro libro = new Libro("123456789");
HashSet<Ejemplar> ejemplares = new HashSet<Ejemplar>();
ejemplares.add(new Ejemplar("0000001", libro));
ejemplares.add(new Ejemplar("0000002", libro));
ejemplares.add(new Ejemplar("0000003", libro));
libro.setEjemplares(ejemplares);
assertTrue(libro.getEjemplares().contains(new Ejemplar
("0000002", libro)));
}
}Ejecutamos el test con el botón derecho sobre la clase o el paquete y Run tests. También los podemos lanzar usando el goal correspondiente de Maven.
2.5.2. Jerarquía de clases Usuario, Alumno, Profesor
Vamos a implementar una versión inicial de la jerarquía de clases usuario, definiendo un esqueleto de clases que ampliaremos más adelante.
En primer lugar la clase padre abstracta Usuario que hereda de ClaseDominio y que define los atributos comunes login y password. Los métodos equals y hashCode de todas las subclases se basan en estos atributos, porque definen unas claves naturales para estas clases. Definimos entonces esos métodos en la clase padre Usuario. Y escogemos como clave natural el login del usuario, de forma que dos usuarios serán iguales cuando tengan el mismo login.
package org.expertojava.jbibrest.modelo;
public abstract class Usuario extends ClaseDominio {
private String login;
private String password;
public String getLogin() {
return login;
}
public void setLogin(String login) {
this.login = login;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Usuario usuario = (Usuario) o;
if (!login.equals(usuario.login)) return false;
return true;
}
@Override
public int hashCode() {
return login.hashCode();
}
}Definimos las clases hijas, junto con su constructores:
package org.expertojava.jbibrest.modelo;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class Profesor extends Usuario {
private static Log logger = LogFactory.getLog(Profesor.class);
public Profesor(String login, String password) {
this.setLogin(login);
this.setPassword(password);
}
}package org.expertojava.jbibrest.modelo;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class Alumno extends Usuario {
private static Log logger = LogFactory.getLog(Alumno.class);
public Alumno(String login, String password) {
this.setLogin(login);
this.setPassword(password);
}
}2.5.3. Gestión de excepciones
Es conveniente definir una clase de excepciones para encapsular en ellas todos los errores generados en la aplicación. Vamos a definir una excepción genérica de tipo unchecked (BibliotecaException), que será la excepción padre de todas las excepciones de aplicación de la biblioteca.
En principio la definimos unchecked porque todos los errores que vamos a capturar tienen que ver con el mal uso del API. En general, un método debe realizar su funcionalidad y terminar correctamente cuando todo ha funcionado bien. Se lanzará una excepción si algo falla. Por ejemplo, cuando definamos un método prestar(libro,usuario) lanzaremos excepciones cuando no se cumplan las condiciones que hacen que el libro pueda ser prestado al usuario. Al lanzar excepciones no chequeadas permitimos que el programador chequee las condiciones antes de llamar al método y no tenga que obligatoriamente capturar una excepción que sabemos que no se va a producir. Si es necesario más adelante añadiremos una excepción checked.
Definimos las excepciones en el paquete org.expertojava.jbibrest.utils.
package org.expertojava.jbibrest.utils;
public class BibliotecaException extends RuntimeException {
private static final long serialVersionUID = 1L;
public BibliotecaException() {
super();
}
public BibliotecaException(String message) {
super(message);
}
public BibliotecaException(String message, Throwable cause) {
super(message, cause);
}
}Podemos observar como, al sobrecargar el constructor con los parámetros {String, Throwable}, nuestra excepción permitirá su uso como Nested Exception.
2.5.4. Reglas de negocio
Es común agrupar las reglas de negocio de una aplicación en una o más clases (dependiendo de los diferentes subsistemas de la aplicación), para evitar que estén dispersas por la aplicación y acopladas a un gran número de clases.
En nuestro caso, vamos a crear un Singleton, al que llamaremos BibliotecaBR (BR = Business Rules). En principio, los valores estarán escritos directamente sobre la clase, pero en un futuro podríamos querer leer los valores de las reglas de negocio de un fichero de configuración).
El código inicial de nuestras reglas de negocio será el siguiente:
package org.expertojava.jbibrest.utils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.expertojava.jbibrest.modelo.Alumno;
import org.expertojava.jbibrest.modelo.Profesor;
import org.expertojava.jbibrest.modelo.Usuario;
public class BibliotecaBR {
private int numDiasPrestamoAlumno = 7;
private int numDiasPrestamoProfesor = 30;
private int cupoOperacionesAlumno = 5;
private int cupoOperacionesProfesor = 8;
private static Log logger = LogFactory.getLog(BibliotecaBR.class);
private static BibliotecaBR me = new BibliotecaBR();
private BibliotecaBR() {
logger.debug("Creada instancia de " + BibliotecaBR.class);
}
public static BibliotecaBR getInstance() {
return me;
}
public int calculaNumDiasPrestamo(Usuario usuario)
throws BibliotecaException {
if (usuario instanceof Alumno) {
return numDiasPrestamoAlumno;
} else if (usuario instanceof Profesor) {
return numDiasPrestamoProfesor;
} else {
String msg = "Solo los alumnos y profesores pueden tener " +
"libros prestados";
logger.error(msg);
throw new BibliotecaException(msg);
}
}
public void compruebaNumDiasPrestamo(Usuario usuario, int numDias)
throws BibliotecaException {
String msg;
if (!(usuario instanceof Alumno)
&& !(usuario instanceof Profesor)) {
msg = "Solo los alumnos y profesores pueden tener libros " +
"prestados";
logger.error(msg);
throw new BibliotecaException(msg);
}
if ((usuario instanceof Alumno && numDias >
numDiasPrestamoAlumno) ||
(usuario instanceof Profesor && numDias >
numDiasPrestamoProfesor)) {
msg = "Devolución fuera de plazo";
logger.error(msg);
throw new BibliotecaException(msg);
}
}
public int cupoOperaciones(Usuario usuario)
throws BibliotecaException {
if (usuario instanceof Alumno)
return cupoOperacionesAlumno;
else if (usuario instanceof Profesor)
return cupoOperacionesProfesor;
else {
String msg = "Solo los alumnos y profesores pueden tener libros prestados";
logger.error(msg);
throw new BibliotecaException(msg);
}
}
public void compruebaCupoOperaciones(Usuario usuario, int numOp)
throws BibliotecaException {
String msg;
if (!(usuario instanceof Alumno)
&& !(usuario instanceof Profesor)) {
msg = "Solo los alumnos y profesores pueden tener libros prestados";
logger.error(msg);
throw new BibliotecaException(msg);
}
if ((usuario instanceof Alumno && numOp >
cupoOperacionesAlumno) ||
(usuario instanceof Profesor && numOp > cupoOperacionesProfesor)) {
msg = "El cupo de operaciones posibles esta lleno";
logger.error(msg);
throw new BibliotecaException(msg);
}
}
}Ampliamos los tests
Añadimos inicialmente algunos tests que comprueban el funcionamiento de algunas reglas de negocios.
package org.expertojava.jbibrest.modelo;
import org.expertojava.jbibrest.utils.BibliotecaBR;
import org.expertojava.jbibrest.utils.BibliotecaException;
import org.junit.Test;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.fail;
public class BibliotecaBRTest {
@Test
public void testCalculaNumDiasPrestamoProfesor() {
int diasProfesor = BibliotecaBR.getInstance()
.calculaNumDiasPrestamo(
new Profesor("severus.snape", "1234"));
assertEquals(30, diasProfesor);
}
@Test
public void testCompruebaCupoOperacionesProfesorCorrecto() {
try {
Profesor profesor =
new Profesor("severus.snape", "1234");
BibliotecaBR.getInstance()
.compruebaCupoOperaciones(profesor, 8);
BibliotecaBR.getInstance()
.compruebaCupoOperaciones(profesor, 1);
} catch (BibliotecaException e) {
fail("No debería fallar - el cupo de operaciones del" +
" PROFESOR es correcto");
}
}
@Test(expected = BibliotecaException.class)
public void testCompruebaCupoOperacionesProfesorIncorrecto()
throws BibliotecaException {
BibliotecaBR.getInstance()
.compruebaCupoOperaciones(
new Profesor("severus.snape", "1234"), 9);
}
}2.5.5. Página web de prueba
Como último paso de esta parte guiada del proyecto vamos a cambiar la página frontal para probar la aplicación se despliega correctamente. Modificamos la página index.jsp para recoger una cadena de texto que simula un ISBN de un libro
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>Start Page</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</head>
<body>
<h1>Hello World!</h1>
<form action="<%=request.getContextPath()%>/holamundo">
<p>ISBN: <input type="text" name="isbn"></p>
<input type="submit" value="Enviar">
</form>
</body>
</html>Y cambiamos también el servlet holamundo para que haga una acción muy sencilla como crear un libro y mostrarlo:
// imports
@WebServlet(name="holamundo", urlPatterns="/holamundo")
public class HolaMundo extends HttpServlet {
protected void doPost(HttpServletRequest request,
HttpServletResponse response) throws
ServletException, IOException {
}
protected void doGet(HttpServletRequest request,
HttpServletResponse response) throws
ServletException, IOException {
response.setContentType("text/html");
String isbnStr = request.getParameter("isbn");
// Comprobamos entradas no nulas
int errorStatus = 0;
String errorMsg = "";
if (isbnStr == null) {
errorStatus = HttpServletResponse.SC_BAD_REQUEST;
errorMsg = "Faltan parámetros en la petición";
}
if (errorStatus == 0) {
// Llamamos al modelo para construir la respuesta
Libro libro = new Libro(isbnStr);
libro.setAutor("J. K. Rowling");
libro.setTitulo("Harry Potter y la piedra filosofal");
libro.setNumEjemplares(7);
PrintWriter out = response.getWriter();
out.println("<!DOCTYPE HTML PUBLIC \"" +
"-//W3C//DTD HTML 4.0 " +
"Transitional//EN\">");
out.println("<HTML>");
out.println("<BODY>");
out.println("<h1>Creado un nuevo libro</h1>");
out.println("<p>");
out.println(libro.toString());
out.println("</p>");
out.println("</BODY>");
out.println("</HTML");
}
// errorStatus > 0
else {
response.setStatus(errorStatus);
PrintWriter out = response.getWriter();
out.println(errorMsg);
}
}
}Con esto terminamos la parte guiada.
Los tests estarán funcionando correctamente y la página web de prueba deberá mostrar el libro creado correctamente. Puedes borrar las clases Nombre, Genero y NombreTest del principio de la clase.
2.6. Desarrollo e implementación (parte no guiada, 1 punto)
-
Para terminar el ejercicio debes implementar el resto del modelo de dominio:
-
Completa las clases de la jerarquía de
Usuarioe implementa el resto de clases de domino como hemos hecho con la claseLibro:-
Define los constructores con los atributos no nulos de las clases
-
Define los métodos
hashCodeyequalsusando los atributos que constituyan claves naturales. -
Las relaciones X-a-muchos las definimos del tipo
Set. De esta forma nos aseguramos que no existen objetos duplicados en las relaciones. La identidad en un conjunto se define con el métodoequalsde sus elementos (definido anteriormente).
-
-
Define la clase
Direccioncomo una clase normal (no una subclase deClaseDomino)
-
-
Completa los tests de las clases y de
BibliotecaBR.En los tests de las clases de dominio debemos comprobar las relaciones de igualdad y errores de inicialización. Por ejemplo, a continuación puedes ver el test de la clase
Prestamo:/src/test/java/org.expertojava.jbibrest.modelo.PrestamoTestpackage org.expertojava.jbibrest.modelo; import org.expertojava.jbibrest.utils.BibliotecaException; import org.junit.Before; import org.junit.BeforeClass; import org.junit.Test; import java.util.Calendar; import java.util.Date; import static org.junit.Assert.*; public class PrestamoTest { static Libro libro1; static Ejemplar ejemplar1, ejemplar2; static Usuario usuario1, usuario2; static Date fecha1, fecha2, fecha3; @BeforeClass public static void oneTimeSetUp() { libro1 = new Libro("123223343434"); ejemplar1 = new Ejemplar("000001", libro1); ejemplar2 = new Ejemplar("000002", libro1); usuario1 = new Profesor("quirinus.quirrell","1234"); usuario2 = new Alumno("neville.longbottom","1234"); // fecha1 = fecha actual // fecha2 = fecha actual + 7 días // fecha3 = fechaFin + 1 día fecha1 = new Date(); Calendar calendar = Calendar.getInstance(); calendar.setTime(fecha1); calendar.add(Calendar.DATE, 7); fecha2 = calendar.getTime(); calendar.add(Calendar.DATE, 1); fecha3 = calendar.getTime(); } /* Dos préstamos son iguales cuando tienen el mismo usuario, * ejemplar y fecha de inicio */ @Test public void testEquals() { Prestamo prestamo1 = new Prestamo(usuario1, ejemplar1, fecha1, fecha2); Prestamo prestamo2 = new Prestamo(usuario1, ejemplar1, fecha1, fecha3); assertTrue(prestamo1.equals(prestamo2)); // Cambiando ejemplar al segundo ya no son iguales prestamo2.setEjemplar(ejemplar2); assertFalse(prestamo1.equals(prestamo2)); // Cambiando el usuario al segundo tampoco son iguales prestamo2.setEjemplar(ejemplar1); prestamo2.setUsuario(usuario2); assertFalse(prestamo1.equals(prestamo2)); } @Test(expected = BibliotecaException.class) public void testExcepcionFechaInicioMayorDevolucion() throws BibliotecaException { new Prestamo(usuario1, ejemplar1, fecha2, fecha1); } }Para los tests de
BibliotecaBRpuedes rellenar los siguientes:BibliotecaBRTestpublic class BibliotecaBRTest { @Test public void testCalculaNumDiasPrestamoAlumno() { // TODO } @Test public void testCupoOperacionesProfesor() { // TODO } @Test public void testCupoOperacionesAlumno() { // TODO } @Test public void testCompruebaCupoOperacionesAlumnoCorrecto() { // TODO } @Test(expected = BibliotecaException.class) public void testCompruebaCupoOperacionesAlumnoIncorrecto() throws BibliotecaException { // TODO } }
A continuación puedes ver una imagen de cómo queda el aspecto del panel del proyecto cuando hayas terminado el ejercicio:
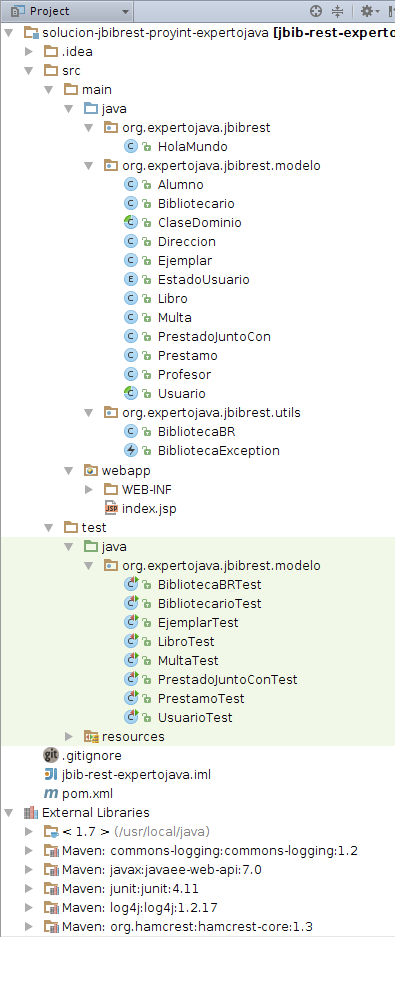
3. (2,5 puntos) Capa de persistencia y capa de negocio
En esta segunda sesión del proyecto web, una vez definidas las clases de modelo de la biblioteca, vamos a desarrollar la capa de persistencia de la aplicación usando JPA y clases DAO y la capa de métodos de negocio utilizando enterprise beans de sesión.
Recordemos que el objetivo de la aplicación es gestionar una biblioteca de un centro educativo y proporcionar distintas funcionalidades a los usuarios de la biblioteca y a sus bibliotecarios.
Avisamos de una modificación que hay que realizar en el proyecto resultante de la fase anterior: hay que eliminar el atributo password de las clases Usuario y Bibliotecario. En la sesión de despliegue en PaaS se implementará una autenticación basada en una tabla independiente de las entidades.
|
3.1. API del servicio
Es conveniente remarcar que el objetivo final del desarrollo de la parte del servidor es proporcionar todas las funcionalidades de la aplicación en forma de API RESTful.
En concreto, las funcionalidades que vamos a proporcionar son las siguientes, agrupadas por la restricción de acceso.
| Debido a la complejidad de realizar tests sobre EJBs con restricciones de seguridad, definiremos las restricciones de acceso en la capa REST. De esta forma todas las funciones de la capa de negocio (EJB) se podrán testear sin realizar ninguna autenticación. |
Operaciones restringidas a usuarios y bibliotecarios:
-
Obtener información actual de un usuario: se pasa el login del usuario y se obtienen sus datos, su identificador, su estado, num. préstamos activos, multa activa, etc.
-
Obener lista de préstamos de un un usuario: se pasa el identificador del usuario y devuelve la colección de libros (libro y ejemplar) que tiene prestados un usuario
-
Solicitar un préstamo de un libro: se pasa el identificador del usuario y el identificador del libro y se realiza el préstamo de un ejemplar disponible si el ejemplar está disponible. Se lanza un error si no hay ejemplares disponibles, si el usuario está multado o si supera el número de préstamos permitidos. Si se ha realizado el préstamo con éxito se devuelve el nuevo préstamo.
Operación restringida a bibliotecarios:
-
Realizar la devolución de un ejemplar: se pasa el identificador de usuario y el identificador de ejemplar, se cierra el préstamo y se crea una multa si la devolución está fuera de plazo. Se devuelve un enumerado con el resultado de la devolución:
DEVOLUCIÓN_CORRECTAoDEVOLUCIÓN_FUERA_DE_PLAZO.
Operaciones no restringidas:
-
Listado de libros: se devuelve la lista de todos los libros
-
Búsqueda de libros por autor: se pasa una cadena de texto y se devuelve la lista de libros que tienen un autor cuyo nombre contiene esa cadena de texto
-
Búsqueda de libros por título: se pasa una cadena de texto y se devuelve la lista de libros cuyo título contiene esa cadena de texto
-
Búsqueda de libro por identificador: se pasa el identificador del libro y se devuelven los detalles del libro y una colección con sus ejemplares
-
Libros recomendados: se pasa el identificador del libro y un número n de recomendaciones deseadas. Se devuelve la lista de esos n libros que más se han prestado junto con el libro inicial.
Vamos a centrar el desarrollo de la capa de servicios y de persistencia en estas funcionalidades.
-
Implementaremos la capa de persistencia utilizando JPA y Bean Validation y realizaremos las pruebas de esta capa usando DbUnit
-
Para los métodos de negocio utilizaremos enterprise beans que nos proporcionan transaccionalidad. Haremos las pruebas con Arquillian.
Vamos a realizar una primera iteración guiada en la que implementaremos algunas de las funcionalidades relacionadas con libros y ejemplares. Después deberás implementar el resto de funcionalidades.
3.2. Iteración 1
En esta primera iteración vamos a implementar las dos funcionalidades:
-
Listado de libros: se devuelve la lista de todos los libros
-
Libros recomendados: se pasa el identificador del libro y un número n de recomendaciones deseadas. Se devuelve la lista de esos n libros que más se han prestado junto con el libro inicial.
3.2.1. Capa de persistencia
En la capa de persistencia tenemos que convertir las clases de modelo en entidades, utilizando las anotaciones JPA y bean validation necesarias. Crearemos también las clases DAO que encapsulan las operaciones sobre estas entidades.
Creación de la base de datos
Antes de empezar a trabajar con el código debemos crear la base de datos biblioteca en nuestro ordenador y la fuente de datos BibliotecaDS en nuestro servidor WildFly en donde vamos a hacer las pruebas.
Para crear la base de datos desde IntelliJ utiliza el panel Database situado en el lateral derecho:
-
Abre el panel Database en la parte derecha.
-
Crea una nueva conexión con la base de datos MySQL con la opción + > Data Source > MySQL
-
Inicializa los parámetros de la conexión, sólo tienes que indicar el usuario
rooty la contraseñaexpertojava. Aparecerá también un aviso indicando que no está descargado el driver de acceso a MySQL, pincha el enlace y lo descargará e instalará.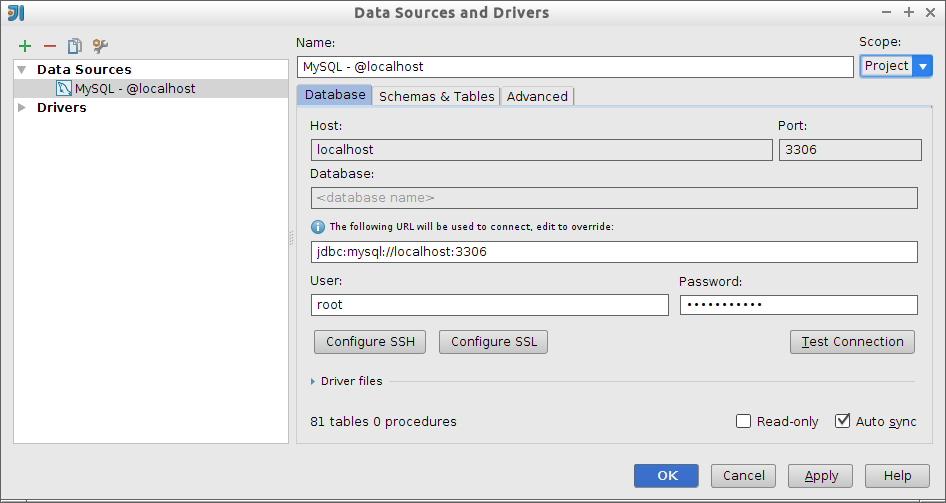
Una vez configurada la conexión, vamos a utilizarla para crear la base de datos biblioteca. En el panel de base de datos podremos ver un desplegable con las bases de datos existentes. Para crear la nueva base de datos abre la consola SQL pulsando el icono correspondiente del panel de base de datos:
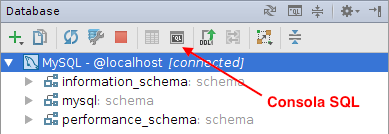
Y ejecuta el comando:
CREATE DATABASE biblioteca;Verás que se ha creado una base de datos con ese nombre bajo las ya existentes por defecto en MySQL.
Otra forma de crear la base de datos es hacerlo desde línea de comando:
$ echo "CREATE DATABASE biblioteca" > create.sql
$ mysql -u root -p"expertojava" < create.sqlConfiguración de la fuente de datos MySQL en WildFly
Recuerda que para trabajar con JPA en una aplicación web el acceso a la base de datos hay que hacerlo a través de una fuente de datos creada y gestionada por el servidor de aplicaciones.
Vamos a ver cómo configurar una fuente de datos MySQL en WildFly. Algunos de los pasos siguientes no serán necesarios si estás trabajando con el mismo servidor de aplicaciones con el que has hecho los módulos de JPA o de Componentes EJB. Los incluimos por completitud, por si estás trabajando con un servidor recién instalado.
-
En primer lugar localiza el driver MySQL
mysql-connector-java-5.1.33.jar(lo puedes encontrar en el repositorio local de Maven.m2/repository/mysql/mysql-connector-java/5.1.33/ -
Conéctate a la consola de administración de WildFly y selecciona la opción Runtime > Manage Deployments > Add y añade el JAR. Ponle como nombre mysql_connector (no es importante)
-
Pulsa en el botón En/Disable para activar el driver
-
En Configuration > Connector > Datasources > XA DATASOURCES tenemos que crear una nueva fuente de datos. Pulsa el botón Add e introduce los siguientes nombres:
-
Name:
BibliotecaDS -
JNDI Name:
java:/datasources/BibliotecaDS
-
-
Selecciona el driver que acabamos de añadir y escribe como nombre de clase XA DataSource:
com.mysql.jdbc.jdbc2.optional.MysqlXADataSource:
-
Añade la propiedad
URLy el valorjdbc:mysql://localhost:3306/biblioteca -
Y en la última pantalla define el usuario y la contraseña de la conexión
-
Username:
root -
Password:
expertojava
-
Y prueba la conexión pulsando el botón.
-
Por último activamos la fuente de datos:
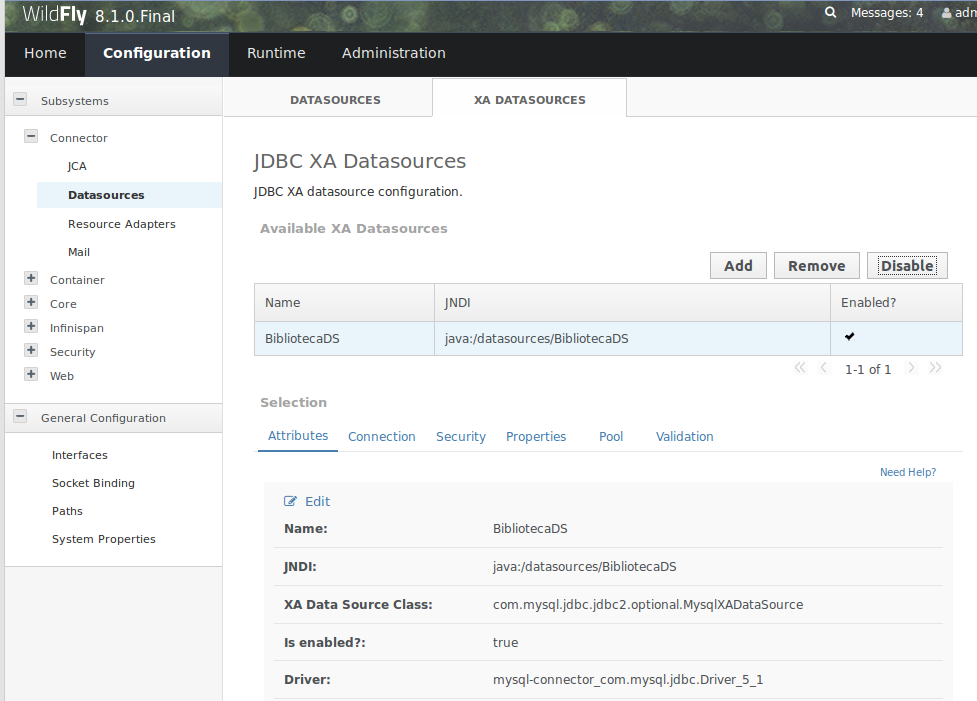
Configuración de JPA
Vamos a añadir al proyecto la configuración JPA:
-
Dependencias en el POM
-
Fichero
persistence.xmlen la configuración de ejecución -
Fichero
persistence.xmlen la configuración de test
Empezamos con el POM de Maven. Hay que añadir al fichero pom.xml las dependencias relacionadas con Hibernate y DbUnit, para poder ejecutar los tests. El fichero completo es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.expertojava.proyint</groupId>
<artifactId>jbib-rest</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging>
<name>jbib-rest</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-web-api</artifactId>
<version>7.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<!-- Tests -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- Hibernate -->
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.1-api</artifactId>
<version>1.0.0.Final</version>
<scope>test</scope>
</dependency>
<!-- Quitamos el scope test para que no de error el
elemento provider del persistence.xml de runtime-->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.3.7.Final</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.33</version>
<scope>test</scope>
</dependency>
<!-- DbUnit -->
<dependency>
<groupId>org.dbunit</groupId>
<artifactId>dbunit</artifactId>
<version>2.5.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.7</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>test</scope>
</dependency>
<!-- Bean Validation -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.1.3.Final</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>javax.el</groupId>
<artifactId>javax.el-api</artifactId>
<version>2.2.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>el-impl</artifactId>
<version>2.2</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<finalName>${project.name}</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>2.3</version>
<configuration>
<failOnMissingWebXml>false</failOnMissingWebXml>
</configuration>
</plugin>
<plugin>
<groupId>org.wildfly.plugins</groupId>
<artifactId>wildfly-maven-plugin</artifactId>
<version>1.0.2.Final</version>
<configuration>
<hostname>localhost</hostname>
<port>9990</port>
</configuration>
</plugin>
</plugins>
</build>
</project>En el fichero src/main/resources/META-INF/persistence.xml definimos la configuración de JPA y definimos la unidad de persistencia biblioteca.
Incluimos la declaración de las clases de entidad que vamos a implementar en esta primera iteración.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0"
xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="biblioteca">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<jta-data-source>java:/datasources/BibliotecaDS</jta-data-source>
<class>org.expertojava.jbibrest.modelo.Libro</class>
<class>org.expertojava.jbibrest.modelo.Ejemplar</class>
<class>org.expertojava.jbibrest.modelo.PrestadoJuntoCon</class>
<properties>
<property name="hibernate.dialect"
value="org.hibernate.dialect.MySQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="update" />
<property name="hibernate.show_sql" value="true" />
</properties>
</persistence-unit>
</persistence>Y en la configuración de test de Maven añadimos la configuración de JPA que se va a utilizar para lanzar las pruebas. El fichero es src/test/resources/META-INF/persistence.xml
<persistence version="2.1"
xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence">
<persistence-unit name="biblioteca-local"
transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<class>org.expertojava.jbibrest.modelo.Ejemplar</class>
<class>org.expertojava.jbibrest.modelo.Libro</class>
<class>org.expertojava.jbibrest.modelo.PrestadoJuntoCon</class>
<properties>
<!-- JPA properties -->
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/biblioteca"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password"
value="expertojava"/>
<!-- Hibernate properties -->
<property name="hibernate.dialect"
value="org.hibernate.dialect.MySQLDialect"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="false"/>
<property name="hibernate.hbm2ddl.auto" value="create"/>
</properties>
</persistence-unit>
</persistence>Clases de entidades
Vamos ahora a modificar un pequeño conjunto de clases del modelo, añadiendo las anotaciones necesarias para convertirlas en clases de entidad JPA. En concreto, las clases son:
-
Libro -
Ejemplar -
PrestadoJuntoCon
Añadiremos anotaciones JPA y anotaciones Bean Validation.
Listamos a continuación las clases.
package org.expertojava.jbibrest.modelo;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import javax.persistence.*;
import javax.validation.constraints.Min;
import javax.validation.constraints.NotNull;
import java.util.HashSet;
import java.util.Set;
@Entity
public class Libro extends ClaseDominio {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
@NotNull
@Column(unique=true, nullable = false)
private String isbn;
private String autor;
private String titulo;
@Min(0)
private Integer numPaginas;
@Min(0)
private int numEjemplares = 0;
private String portadaURI;
@OneToMany(mappedBy = "libro1")
private Set<PrestadoJuntoCon> prestadoCon = new HashSet<>();
@OneToMany(mappedBy = "libro")
private Set<Ejemplar> ejemplares = new HashSet<>();
private static Log logger = LogFactory.getLog(Libro.class);
public Libro() {}
public Libro(String isbn) {
this.isbn = isbn;
}
//
// Getters y setters
//
// Dos libros son iguales cuando tienen el mismo ISBN
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Libro libro = (Libro) o;
if (isbn != null ? !isbn.equals(libro.isbn) : libro.isbn != null)
return false;
return true;
}
@Override
public int hashCode() {
return isbn != null ? isbn.hashCode() : 0;
}
@Override
public String toString() {
return "Libro{" +
"id=" + id +
", isbn='" + isbn + '\'' +
", autor='" + autor + '\'' +
", titulo='" + titulo + '\'' +
", numPaginas=" + numPaginas +
", numEjemplares=" + numEjemplares +
", portadaURI='" + portadaURI + '\'' +
'}';
}
}package org.expertojava.jbibrest.modelo;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import javax.persistence.*;
import javax.validation.constraints.NotNull;
import java.util.Date;
@Entity
public class Ejemplar extends ClaseDominio {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
@NotNull
@Column(nullable = false)
private String codigoEjemplar;
@NotNull
@ManyToOne
private Libro libro;
@Temporal(TemporalType.DATE)
private Date fechaAdquisicion;
private String observaciones;
private static Log logger = LogFactory.getLog(Ejemplar.class);
public Ejemplar() {}
public Ejemplar(String codigoEjemplar, Libro libro) {
this.codigoEjemplar = codigoEjemplar;
this.libro = libro;
logger.debug("Nueva instancia de Ejemplar: " + codigoEjemplar);
}
//
// Getters y setters
//
// Dos ejemplares son iguales cuando tienen el mismo código y son
// del mismo libro
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Ejemplar ejemplar = (Ejemplar) o;
if (codigoEjemplar != null ?
!codigoEjemplar.equals(ejemplar.codigoEjemplar) :
ejemplar.codigoEjemplar != null) return false;
if (libro != null ? !libro.equals(ejemplar.libro) :
ejemplar.libro != null) return false;
return true;
}
@Override
public int hashCode() {
int result =
codigoEjemplar != null ? codigoEjemplar.hashCode() : 0;
result = 31 * result + (libro != null ? libro.hashCode() : 0);
return result;
}
}package org.expertojava.jbibrest.modelo;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import javax.persistence.*;
@Entity
public class PrestadoJuntoCon extends ClaseDominio {
private static Log logger = LogFactory.getLog(PrestadoJuntoCon.class);
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
@ManyToOne
private Libro libro1;
@OneToOne
private Libro libro2;
@NotNull
@Column(nullable = false)
private Integer numVeces;
public PrestadoJuntoCon() {}
public PrestadoJuntoCon(Libro libro1, Libro libro2, Integer numVeces) {
this.libro1 = libro1;
this.libro2 = libro2;
this.numVeces = numVeces;
}
//
// Getters y setters
//
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
PrestadoJuntoCon that = (PrestadoJuntoCon) o;
if (libro1 != null ? !libro1.equals(that.libro1) : that.libro1 != null) return false;
if (libro2 != null ? !libro2.equals(that.libro2) : that.libro2 != null) return false;
return true;
}
@Override
public int hashCode() {
int result = libro1 != null ? libro1.hashCode() : 0;
result = 31 * result + (libro2 != null ? libro2.hashCode() : 0);
return result;
}
}
Puedes comprobar que en los métodos equals y hashcode hemos permitido que los atributos sean null para que funcione correctamente el lanzamiento de la excepción de bean validation.
|
Pruebas con DbUnit
Vamos a probar estas tres primeras entidades utilizando DbUnit. Empezamos por crear el fichero src/test/resources/datasets/dataset1.xml con un conjunto de datos de prueba.
<?xml version='1.0' encoding='UTF-8'?>
<dataset>
<Libro id="1" titulo="Patterns Of Enterprise Application Architecture"
autor="Martin Fowler" isbn="0321127420" numEjemplares="2"
numPaginas="533" portadaURI="0321127420.jpg"/>
<Libro id="2" titulo="Clean Code" autor="Robert C. Martin"
isbn="0132350882" numEjemplares="1" numPaginas="288"
portadaURI="0132350882.jpg"/>
<Libro id="3" titulo="Test Driven Development" autor="Kent Beck"
isbn="0321146530" numEjemplares="1" numPaginas="192"
portadaURI="0321146530.jpg"/>
<Ejemplar id="1" codigoEjemplar="001" fechaAdquisicion="2014-10-01"
libro_id="1"/>
<Ejemplar id="2" codigoEjemplar="002" fechaAdquisicion="2014-10-01"
libro_id="1"/>
<Ejemplar id="3" codigoEjemplar="001" fechaAdquisicion="2014-11-01"
libro_id="2"/>
<Ejemplar id="4" codigoEjemplar="001" fechaAdquisicion="2014-11-21"
libro_id="3"/>
<PrestadoJuntoCon id="1" libro1_id="1" libro2_id="2" numVeces="4"/>
<PrestadoJuntoCon id="2" libro1_id="2" libro2_id="1" numVeces="4"/>
<PrestadoJuntoCon id="3" libro1_id="1" libro2_id="3" numVeces="2"/>
<PrestadoJuntoCon id="4" libro1_id="3" libro2_id="1" numVeces="2"/>
</dataset>Par empezar definimos dos tests sencillos. Uno que carga la unidad de persistencia y otro que comprueba el método find del DAO. Los creamos en el fichero src/test/java/org.expertojava.jbibrest.persistencia.PersistenciaTest.java.
package org.expertojava.jbibrest.persistencia;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import org.dbunit.database.DatabaseConfig;
import org.dbunit.database.DatabaseConnection;
import org.dbunit.database.IDatabaseConnection;
import org.dbunit.dataset.IDataSet;
import org.dbunit.dataset.xml.FlatXmlDataSetBuilder;
import org.dbunit.ext.mysql.MySqlDataTypeFactory;
import org.dbunit.operation.DatabaseOperation;
import org.expertojava.jbibrest.modelo.*;
import org.junit.AfterClass;
import org.junit.Before;
import org.junit.BeforeClass;
import org.junit.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import static org.junit.Assert.assertTrue;
import static org.junit.Assert.fail;
public class PersistenciaTest {
private static IDatabaseConnection connection;
private static IDataSet dataset;
private static EntityManagerFactory emf;
private static Log logger = LogFactory
.getLog(PersistenciaTest.class);
@BeforeClass
public static void initDatabaseTest() {
logger.info("Obteniendo JPA EntityManagerFactory para los tests");
try {
emf = Persistence
.createEntityManagerFactory("biblioteca-local");
// Inicializamos la conexión a la BD necesaria para
// que DBUnit cargue los datos de los tests
Class.forName("com.mysql.jdbc.Driver");
Connection jdbcConnection = (Connection) DriverManager
.getConnection(
"jdbc:mysql://localhost:3306/biblioteca",
"root", "expertojava");
connection = new DatabaseConnection(jdbcConnection);
// added this 2 lines to get rid of the warning
DatabaseConfig dbConfig = connection.getConfig();
dbConfig.setProperty(DatabaseConfig.PROPERTY_DATATYPE_FACTORY,
new MySqlDataTypeFactory());
FlatXmlDataSetBuilder flatXmlDataSetBuilder =
new FlatXmlDataSetBuilder();
flatXmlDataSetBuilder.setColumnSensing(true);
dataset = flatXmlDataSetBuilder.build(Thread.currentThread()
.getContextClassLoader()
.getResourceAsStream("datasets/dataset1.xml"));
} catch (Exception ex) {
ex.printStackTrace();
fail("Excepción al inicializar el emf y DbUnit");
}
}
@Before
public void cleanDB() throws Exception {
// Se hace un "clean insert" de los datos de prueba
// definidos en el fichero XML. El "clean insert" vacía las
// tablas de los datos de prueba y después inserta los datos
DatabaseOperation.CLEAN_INSERT.execute(connection, dataset);
}
@Test
public void entityManagerTest() { (1)
EntityManager em = emf.createEntityManager();
assertTrue(em != null);
}
// Primer test de Libro
@Test
public void findDevuelveLibro() { (2)
EntityManager em = emf.createEntityManager();
Libro libro = em.find(Libro.class, 1L);
assertTrue(libro.getTitulo().equals(
"Patterns Of Enterprise Application Architecture"));
em.close();
}
@AfterClass
public static void closeEntityManagerFactory() {
logger.info("Closing JPA EntityManagerFactory");
if (emf != null)
emf.close();
}
}Probamos los tests desde IntelliJ y desde el panel de Maven, para comprobar que funcionan correctamente en ambas configuraciones.
Añadimos el resto de tests, que comprueban el método find y las relaciones entre las entidades:
@Test
public void findDevuelveLibroConEjemplares() { (3)
EntityManager em = emf.createEntityManager();
Libro libro = em.find(Libro.class, 1L);
assertTrue(libro.getEjemplares().size() == 2);
em.close();
}
// Tests de Ejemplar
@Test
public void findDevuelveEjemplar() { (4)
EntityManager em = emf.createEntityManager();
Ejemplar ejemplar = em.find(Ejemplar.class, 2L);
assertTrue(ejemplar.getLibro().getTitulo().equals(
"Patterns Of Enterprise Application Architecture"));
em.close();
}
// Tests de PrestadoJuntoCon
@Test
public void prestadoVecesConmutativo() {(5)
EntityManager em = emf.createEntityManager();
Libro libro1 = em.find(Libro.class, 1L);
for (PrestadoJuntoCon juntoCon : libro1.getPrestadoCon()) {
Libro libro2 = juntoCon.getLibro2();
for (PrestadoJuntoCon juntoCon2 : libro2.getPrestadoCon()) {
if (juntoCon.getLibro1().equals(juntoCon2.getLibro2())) {
logger.info(juntoCon.getLibro1().getTitulo() +
" - " + juntoCon2.getLibro1().getTitulo() +
" : " + juntoCon.getNumVeces());
assertTrue(juntoCon.getNumVeces()
.equals(juntoCon2.getNumVeces()));
}
}
}
em.close();
}Clases DAO
Añadimos ahora las clases DAO correspondientes a las entidades anteriores. Lo hacemos en el paquete org.expertojava.persistencia:
-
org.expertojava.persistencia.Dao -
org.expertojava.persistencia.LibroDAO -
org.expertojava.persistencia.EjemplarDAO -
org.expertojava.persistencia.PrestadoJuntoConDAO
La clase abstracta Dao:
package org.expertojava.jbibrest.persistencia;
import javax.persistence.EntityManager;
abstract class Dao<T, K> {
EntityManager em;
public Dao(EntityManager em) {
this.em = em;
}
public EntityManager getEntityManager() {
return this.em;
}
public T create(T t) {
em.persist(t);
em.flush();
em.refresh(t);
return t;
}
public T update(T t) {
return (T) em.merge(t);
}
public void delete(T t) {
t = em.merge(t);
em.remove(t);
}
public abstract T find(K id);
}La clase LibroDao:
package org.expertojava.jbibrest.persistencia;
import org.expertojava.jbibrest.modelo.Libro;
import javax.persistence.EntityManager;
import java.util.List;
public class LibroDao extends Dao<Libro, Long> {
private static final String QUERY_ALL_LIBROS =
"SELECT l FROM Libro l";
public LibroDao(EntityManager em) {
super(em);
}
public Libro find(Long id) {
EntityManager em = this.getEntityManager();
return em.find(Libro.class, id);
}
@SuppressWarnings("unchecked")
public List<Libro> getAllLibros() {
EntityManager em = this.getEntityManager();
return (List<Libro>) em.createQuery(QUERY_ALL_LIBROS)
.getResultList();
}
}La clase EjemplarDao:
package org.expertojava.jbibrest.persistencia;
import org.expertojava.jbibrest.modelo.Ejemplar;
import javax.persistence.EntityManager;
import java.util.List;
public class EjemplarDao extends Dao<Ejemplar, Long> {
private static final String QUERY_ALL_EJEMPLARES =
"SELECT e FROM Ejemplar e";
public EjemplarDao(EntityManager em) {
super(em);
}
public Ejemplar find(Long id) {
EntityManager em = this.getEntityManager();
return em.find(Ejemplar.class, id);
}
@SuppressWarnings("unchecked")
public List<Ejemplar> getAllEjemplares() {
EntityManager em = this.getEntityManager();
return (List<Ejemplar>) em.createQuery(QUERY_ALL_EJEMPLARES)
.getResultList();
}
}Y la clase PrestadoJuntoConDao que nos permite obtener el número de veces que un libro se ha prestado junto con otros.
package org.expertojava.jbibrest.persistencia;
import org.expertojava.jbibrest.modelo.Ejemplar;
import javax.persistence.EntityManager;
import java.util.List;
public class PrestadoJuntoConDao extends Dao<PrestadoJuntoCon, Long> {
private static final String QUERY_PRESTADOS_JUNTO_CON =
"SELECT p FROM PrestadoJuntoCon p " +
"WHERE p.libro1.id = :id " +
"ORDER BY p.numVeces DESC";
public PrestadoJuntoConDao(EntityManager em) {
super(em);
}
public PrestadoJuntoCon find(Long id) {
EntityManager em = this.getEntityManager();
return em.find(PrestadoJuntoCon.class, id);
}
@SuppressWarnings("unchecked")
public List<PrestadoJuntoCon> getLibrosPrestadosJuntoCon(Long libroId) {
EntityManager em = this.getEntityManager();
return (List<PrestadoJuntoCon>)
em.createQuery(QUERY_PRESTADOS_JUNTO_CON)
.setParameter("id", libroId)
.getResultList();
}
}Pruebas de las clases Dao
Para probar que las clases Dao funcionan correctamente, creamos una clase de test para cada clase Dao. En cada clase realizamos alguna pruebas, sin ser demasiado exhaustivos. Todas las pruebas las definimos en el paquete org.expertojava.jbibrest.persistencia.
Vamos a trabajar con el mismo conjunto de datos que hemos creado en las pruebas de las entidades.
Por ejemplo, podemos probar:
-
Método
find -
Métodos de actualización
-
Consulta
getAll -
Restricciones Bean Validation
-
Relaciones con otras entidades
Empezamos con las pruebas sobre LibroDao. Fíjate en los nombres de los tests, porque son bastante descriptivos.
package org.expertojava.jbibrest.persistencia;
//
// Imports
//
public class LibroDaoTest {
private static IDatabaseConnection connection;
private static IDataSet dataset;
private static EntityManagerFactory emf;
private static Log logger = LogFactory
.getLog(LibroDaoTest.class);
@BeforeClass
public static void initDatabaseTest() {
//
// Inicialización
//
}
@Before
public void cleanDB() throws Exception {
// Se hace un "clean insert" de los datos de prueba
// definidos en el fichero XML. El "clean insert" vacía las
// tablas de los datos de prueba y después inserta los datos
DatabaseOperation.CLEAN_INSERT.execute(connection, dataset);
}
@Test
public void findLibroDaoTest() { (1)
EntityManager em = emf.createEntityManager();
LibroDao libroDao = new LibroDao(em);
Libro libro = libroDao.find(2L);
assertTrue(libro.getTitulo().equals("Clean Code"));
em.close();
}
@Test
public void updateLibroDaoActualizaBienElAutor() { (2)
String nuevoAutor = "Kent Beck";
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
LibroDao libroDao = new LibroDao(em);
Libro libro = libroDao.find(1L);
libro.setAutor(nuevoAutor);
em.getTransaction().commit();
em.close();
em = emf.createEntityManager();
libroDao = new LibroDao(em);
libro = libroDao.find(1L);
assertTrue(libro.getAutor().equals(nuevoAutor));
em.close();
}
@Test
public void getAllLibrosDevuelveTodosLosLibros() { (3)
EntityManager em = emf.createEntityManager();
LibroDao libroDao = new LibroDao(em);
List<Libro> libros = libroDao.getAllLibros();
assertTrue(libros.size() == 3);
em.close();
}
@Test(expected = ConstraintViolationException.class)
public void createLibroLanzaExcepcionConIsbnNull() { (4)
EntityManager em = emf.createEntityManager();
try {
em.getTransaction().begin();
LibroDao libroDao = new LibroDao(em);
Libro libro = new Libro(null);
libroDao.create(libro);
em.getTransaction().commit();
} catch (RuntimeException ex) {
logger.info("Excpeción: " + ex.getMessage());
em.getTransaction().rollback();
throw ex;
} finally {
em.close();
}
}
@Test
public void numEjemplaresSeCorrespondeConEjemplaresAsociados() { (5)
EntityManager em = emf.createEntityManager();
LibroDao libroDao = new LibroDao(em);
List<Libro> libros = libroDao.getAllLibros();
for (Libro libro : libros) {
int nEjempRelacion = libro.getEjemplares().size();
assertEquals((long) nEjempRelacion, (long) libro.getNumEjemplares());
}
em.close();
}
@AfterClass
public static void closeEntityManagerFactory() {
logger.info("Closing JPA EntityManagerFactory");
if (emf != null)
emf.close();
}
}Las pruebas de la clase EjemplarDao:
package org.expertojava.jbibrest.persistencia;
//
// Imports
//
public class EjemplarDaoTest {
private static IDatabaseConnection connection;
private static IDataSet dataset;
private static EntityManagerFactory emf;
private static Log logger = LogFactory
.getLog(EjemplarDaoTest.class);
@BeforeClass
public static void initDatabaseTest() {
//
// Inicialización
//
}
@Before
public void cleanDB() throws Exception {
// Se hace un "clean insert" de los datos de prueba
// definidos en el fichero XML. El "clean insert" vacía las
// tablas de los datos de prueba y después inserta los datos
DatabaseOperation.CLEAN_INSERT.execute(connection, dataset);
}
@Test
public void findEjemplarDaoTest() { (1)
EntityManager em = emf.createEntityManager();
EjemplarDao ejemplarDao = new EjemplarDao(em);
Ejemplar ejemplar = ejemplarDao.find(3L);
assertTrue(ejemplar.getLibro().getTitulo().equals("Clean Code"));
em.close();
}
@Test
public void updateEjemplarDaoActualizaBienCodigo() { (2)
String nuevoCodigo="002";
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
EjemplarDao ejemplarDao = new EjemplarDao(em);
Ejemplar ejemplar = ejemplarDao.find(3L);
ejemplar.setCodigoEjemplar(nuevoCodigo);
ejemplarDao.update(ejemplar);
em.getTransaction().commit();
em.close();
em = emf.createEntityManager();
ejemplarDao = new EjemplarDao(em);
assertTrue(ejemplarDao.find(3L).getCodigoEjemplar().equals(nuevoCodigo));
em.close();
}
@Test
public void getAllEjemplaresDevuelveTodosLosEjemplares() { (3)
EntityManager em = emf.createEntityManager();
EjemplarDao ejemplarDao = new EjemplarDao(em);
List<Ejemplar> ejemplares = ejemplarDao.getAllEjemplares();
assertTrue(ejemplares.size() == 4);
em.close();
}
@Test(expected = ConstraintViolationException.class)
public void createEjemplarLanzaExcepcionConLibroNull() { (4)
EntityManager em = emf.createEntityManager();
try {
em.getTransaction().begin();
EjemplarDao ejemplarDao = new EjemplarDao(em);
Ejemplar ejemplar = new Ejemplar("001", null);
ejemplarDao.create(ejemplar);
em.getTransaction().commit();
} catch (RuntimeException ex) {
logger.info("Excpeción: " + ex.getMessage());
em.getTransaction().rollback();
throw ex;
} finally {
em.close();
}
}
@AfterClass
public static void closeEntityManagerFactory() {
logger.info("Closing JPA EntityManagerFactory");
if (emf != null)
emf.close();
}
}Y las pruebas de la clase PrestadoJuntoCon:
public class PrestadoJuntoConDaoTest {
private static IDatabaseConnection connection;
private static IDataSet dataset;
private static EntityManagerFactory emf;
private static Log logger = LogFactory
.getLog(PrestadoJuntoConDaoTest.class);
@BeforeClass
public static void initDatabaseTest() {
//
// Inicialización
//
}
@Before
public void cleanDB() throws Exception {
// Se hace un "clean insert" de los datos de prueba
// definidos en el fichero XML. El "clean insert" vacía las
// tablas de los datos de prueba y después inserta los datos
DatabaseOperation.CLEAN_INSERT.execute(connection, dataset);
}
@Test
public void findPrestadoJuntoConDaoTest() {
EntityManager em = emf.createEntityManager();(1)
PrestadoJuntoConDao juntoConDao = new PrestadoJuntoConDao(em);
PrestadoJuntoCon juntoCon = juntoConDao.find(2L);
assertTrue(juntoCon.getLibro1().getTitulo().equals("Clean Code"));
assertTrue(juntoCon.getLibro2().getTitulo()
.equals("Patterns Of Enterprise Application Architecture"));
assertEquals(4L, (long) juntoCon.getNumVeces());
em.close();
}
@Test
public void librosPrestadosJuntoConDevuelveListaTest() {
EntityManager em = emf.createEntityManager();(2)
PrestadoJuntoConDao juntoConDao = new PrestadoJuntoConDao(em);
Libro libro = new LibroDao(em).find(1L);
List<PrestadoJuntoCon> listaJuntoCon = juntoConDao
.getLibrosPrestadosJuntoCon(libro.getId());
assertEquals(2L, listaJuntoCon.size());
long total = 0;
for (PrestadoJuntoCon juntoCon : listaJuntoCon) {
total = total + juntoCon.getNumVeces();
}
assertEquals(6L, total);
em.close();
}
@Test
public void librosPrestadosJuntoConDevuelveOrdenadosTest() {
EntityManager em = emf.createEntityManager();(3)
PrestadoJuntoConDao juntoConDao = new PrestadoJuntoConDao(em);
Libro libro = new LibroDao(em).find(1L);
List<PrestadoJuntoCon> listaJuntoCon = juntoConDao
.getLibrosPrestadosJuntoCon(libro.getId());
assertEquals(2L, listaJuntoCon.size());
boolean ordenado = true;
Integer nVecesPrevio = Integer.MAX_VALUE;
for (PrestadoJuntoCon juntoCon : listaJuntoCon) {
if (juntoCon.getNumVeces() > nVecesPrevio) {
ordenado = false;
break;
}
nVecesPrevio = juntoCon.getNumVeces();
}
assertTrue(ordenado);
em.close();
}
@AfterClass
public static void closeEntityManagerFactory() {
logger.info("Closing JPA EntityManagerFactory");
if (emf != null)
emf.close();
}
}| ¡¡No te limites a copiar y pegar!! Es imprescindible que leas bien el código y entiendas qué se está probando en cada test. |
3.2.2. Capa de lógica de negocio
Una vez definida la capa de persistencia, vamos a implementar los siguientes métodos de negocio en esta primera iteración:
-
Listado de libros: se devuelve la lista de todos los libros
-
Libros recomendados: se pasa el identificador del libro y un número n de recomendaciones deseadas. Se devuelve la lista de esos n libros que más se han prestado junto con el libro inicial.
Los métodos de negocio los vamos a definir en enterprise beans, que van a proporcionar transaccionalidad en las llamadas a distintas clases DAOs.
Vamos a probar la capa de negocio de dos formas. Primero lo haremos accediendo al método desde un servlet y mostrando los resultados en una página web. Y la otra, más correcta, usando Arquillian.
3.2.3. Clase de servicio
Creamos en el paquete org.expertojava.proyint.servicio la clase LibroServicio, un bean de sesión sin estado que contiene los métodos listaLibros() y listaRecomendaciones():
package org.expertojava.jbibrest.servicio;
import org.expertojava.jbibrest.modelo.Libro;
import org.expertojava.jbibrest.modelo.PrestadoJuntoCon;
import org.expertojava.jbibrest.persistencia.LibroDao;
import org.expertojava.jbibrest.persistencia.PrestadoJuntoConDao;
import javax.ejb.Stateless;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import java.util.ArrayList;
import java.util.List;
@Stateless
public class LibroServicio {
@PersistenceContext(unitName = "biblioteca")
EntityManager em;
public List<Libro> listaLibros() {
LibroDao libroDao = new LibroDao(em);
return libroDao.getAllLibros();
}
public List<PrestadoJuntoCon> listaRecomendaciones(Long libroId, int n) {
List<PrestadoJuntoCon> listaDevuelta = new ArrayList<>();
PrestadoJuntoConDao juntoConDao = new PrestadoJuntoConDao(em);
List<PrestadoJuntoCon> listaJuntoCon = juntoConDao
.getLibrosPrestadosJuntoCon(libroId);
// Llenamos la lista a devolver hasta el número de
// libros solicitados
int anyadidos = 0;
for (PrestadoJuntoCon juntoCon : listaJuntoCon) {
if (anyadidos == n) break;
listaDevuelta.add(juntoCon);
anyadidos++;
}
return listaDevuelta;
}
}Tal y como hemos visto en el módulo de componentes enterprise, el bean obtiene el entity manager por inyección de dependencias y lo utiliza en los métodos de negocio. Cada método de negocio se ejecuta dentro de una transacción que crea automáticamente el servidor de aplicaciones.
3.2.4. Prueba desde un servlet
Para probar el bean desde un servlet debemos añadir en el módulo el directorio src/main/webapp con el directorio WEB-INF que contiene el fichero web.xml vacío:
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"
version="3.0">
</web-app>Añadimos también el fichero src/main/webapp/index.jsp desde donde lanzamos las peticiones a los servlets:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>Start Page</title>
<meta http-equiv="Content-Type" content="text/html">
</head>
<body>
<h1>Pruebas métodos de negocio</h1>
<hr/>
<p><a href="<%=request.getContextPath()%>/listalibros">Listado de libros</a></p>
<hr/>
<form action="<%=request.getContextPath()%>/listarecomendaciones">
<p>Identificador del libro: <input type="text" name="libroId"></p>
<p>Número de recomendaciones: <input type="text" name="numRecomendaciones"></p>
<input type="submit" value="Enviar">
</form>
</form>
<hr/>
</body>
</html>Y añadimos los dos servlets que realizan la llamada a los métodos de negocio. En primer lugar src/main/java/org.expertojava.jbibrest.ListadoLibros:
package org.expertojava.jbibrest;
import org.expertojava.jbibrest.modelo.Libro;
import org.expertojava.jbibrest.servicio.LibroServicio;
import javax.ejb.EJB;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.List;
@WebServlet(name="listalibros", urlPatterns="/listalibros")
public class ListadoLibros extends HttpServlet {
@EJB
LibroServicio libroServicio; (1)
protected void doPost(HttpServletRequest request,
HttpServletResponse response) throws
ServletException, IOException {
}
protected void doGet(HttpServletRequest request,
HttpServletResponse response) throws
ServletException, IOException {
List<Libro> listaLibros
= libroServicio.listaLibros(); (2)
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.println("<!DOCTYPE HTML PUBLIC \"" +
"-//W3C//DTD HTML 4.0 " +
"Transitional//EN\">");
out.println("<HTML>");
out.println("<BODY>");
out.println("<ul>");
for (Libro libro : listaLibros ) {
out.println("<li>");
out.println(libro.getAutor() + " : " + libro.getTitulo());
out.println("</li>");
}
out.println("</ul>");
out.println("</BODY>");
out.println("</HTML");
}
}| 1 | Inyección del bean enterprise |
| 2 | Llamada al método de negocio del bean |
Y en segundo lugar src/main/java/org.expertojava.jbibrest.ListaRecomendaciones:
package org.expertojava.jbibrest;
import org.expertojava.jbibrest.modelo.PrestadoJuntoCon;
import org.expertojava.jbibrest.servicio.LibroServicio;
import javax.ejb.EJB;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.List;
@WebServlet(name="listarecomendaciones", urlPatterns="/listarecomendaciones")
public class ListaRecomendaciones extends HttpServlet {
@EJB
LibroServicio libroServicio;
protected void doPost(HttpServletRequest request,
HttpServletResponse response) throws
ServletException, IOException {
}
protected void doGet(HttpServletRequest request,
HttpServletResponse response) throws
ServletException, IOException {
Long libroId = Long.valueOf(request.getParameter("libroId"));
int nRec = Integer.valueOf(request.getParameter("numRecomendaciones"));
List<PrestadoJuntoCon> listaRecomendaciones
= libroServicio.listaRecomendaciones(libroId,nRec);
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.println("<!DOCTYPE HTML PUBLIC \"" +
"-//W3C//DTD HTML 4.0 " +
"Transitional//EN\">");
out.println("<HTML>");
out.println("<BODY>");
out.println("<p> El libro " + listaRecomendaciones
.get(0).getLibro1().getTitulo() +
" se ha prestado junto con: </p>");
out.println("<ul>");
for (PrestadoJuntoCon prestadoCon : listaRecomendaciones ) {
out.println("<li>");
out.println(prestadoCon.getLibro2().getTitulo() + " : " +
prestadoCon.getNumVeces() + " veces");
out.println("</li>");
}
out.println("</ul>");
out.println("</BODY>");
out.println("</HTML");
}
}3.2.5. Prueba con Arquillian
Para probar los métodos de servicio desde Arquillian debemos seguir los siguientes pasos.
En primer lugar, añadimos las dependencias necesarias en el fichero POM del proyecto Maven:
...
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.jboss.arquillian</groupId>
<artifactId>arquillian-bom</artifactId>
<version>1.1.4.Final</version>
<scope>import</scope>
<type>pom</type>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
...
<!-- Arquillian -->
<dependency>
<groupId>org.jboss.arquillian.junit</groupId>
<artifactId>arquillian-junit-container</artifactId>
<version>1.1.5.Final</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.wildfly</groupId>
<artifactId>wildfly-arquillian-container-remote</artifactId>
<version>8.1.0.Final</version>
<scope>test</scope>
</dependency>
...Después añadimos en el directorio test/resources el fichero persistence-datasource.xml que es una copia del persistence.xml usado en tiempo de ejecución. Lo usaremos para que Arquillian lo copie en el war que despliega en el servidor de aplicaciones.
Configuramos el modo de cargar la base de datos con update para mantener los datos que introduce DbUnit en la ejecución de los tests de persistencia.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0"
xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="biblioteca">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<jta-data-source>java:/datasources/BibliotecaDS</jta-data-source>
<class>org.expertojava.jbibrest.modelo.Libro</class>
<class>org.expertojava.jbibrest.modelo.Ejemplar</class>
<class>org.expertojava.jbibrest.modelo.PrestadoJuntoCon</class>
<class>org.expertojava.jbibrest.modelo.Usuario</class>
<class>org.expertojava.jbibrest.modelo.Alumno</class>
<class>org.expertojava.jbibrest.modelo.Profesor</class>
<class>org.expertojava.jbibrest.modelo.Prestamo</class>
<class>org.expertojava.jbibrest.modelo.Multa</class>
<properties>
<property name="hibernate.dialect"
value="org.hibernate.dialect.MySQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="update" /> (1)
<property name="hibernate.show_sql" value="true" />
</properties>
</persistence-unit>
</persistence>| 1 | Configuramos el modo de cargar la base de datos con update para mantener los datos que introduce DbUnit en la ejecución de los tests de persistencia. |
Por último, definimos el test con Arquillian:
package org.expertojava.jbibrest.servicio;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.expertojava.jbibrest.modelo.Libro;
import org.expertojava.jbibrest.persistencia.LibroDao;
import org.expertojava.jbibrest.utils.BibliotecaBR;
import org.jboss.arquillian.junit.Arquillian;
import org.jboss.arquillian.container.test.api.Deployment;
import org.jboss.shrinkwrap.api.Archive;
import org.jboss.shrinkwrap.api.ShrinkWrap;
import org.jboss.shrinkwrap.api.asset.EmptyAsset;
import org.jboss.shrinkwrap.api.spec.WebArchive;
import org.junit.Test;
import org.junit.runner.RunWith;
import javax.ejb.EJB;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertTrue;
@RunWith(Arquillian.class)
public class LibroServicioTest {
private static Log logger = LogFactory
.getLog(LibroServicioTest.class);
@EJB
LibroServicio libroServicio;
@Deployment
public static Archive<?> deployment() {
return ShrinkWrap.create(WebArchive.class, "test.war")
.addPackage(Libro.class.getPackage())
.addPackage(BibliotecaBR.class.getPackage())
.addPackage(LibroDao.class.getPackage())
.addPackage(LibroServicio.class.getPackage())
.addAsResource("persistence-datasource.xml",
"META-INF/persistence.xml")
.addAsWebInfResource(EmptyAsset.INSTANCE, "beans.xml");
}
@Test
public void listaLibrosTraeTodosLosLibrosTest() {
logger.info("Test: listaLibrosTraeTodosLosLibros");
assertEquals(3L, (long) libroServicio.listaLibros().size());
}
@Test
public void listaRecomendacionesTraeRecomendaciones() {
List<PrestadoJuntoCon> prestadoCon =
libroServicio.listaRecomendaciones(1L, 3);
assertEquals(2L, prestadoCon.size());
}
}3.3. Resto de iteraciones
Una vez que hemos realizado de forma guiada la primera iteración, debes completar el resto del proyecto siguiendo las pautas anteriores.
| Debido a la complejidad de realizar tests sobre EJBs con restricciones de seguridad, definiremos las restricciones de acceso en la capa REST. De esta forma todas las funciones de la capa de negocio (EJB) se podrán testear sin realizar ninguna autenticación. |
Las funcionalidades que faltan por implementar son:
Operaciones en la clase UsuarioServicio (que restringiremos en la capa REST a usuarios y bibliotecarios):
-
Obtener información actual de un usuario: se pasa el login del usuario y se obtienen sus datos, su identificador, su estado, num. todos sus préstamos, todas sus multas (incluidos préstamos y multas históricas), etc.
-
Obener lista de préstamos de un un usuario: se pasa el identificador del usuario y devuelve la colección de libros (libro y ejemplar) que tiene prestados un usuario
-
Solicitar un préstamo de un libro: se pasa el identificador del usuario y el identificador del libro y se realiza el préstamo de un ejemplar disponible si el ejemplar está disponible. Se lanza un error si no hay ejemplares disponibles, si el usuario está multado o si supera el número de préstamos permitidos. Si se ha realizado el préstamo con éxito se devuelven los datos del nuevo préstamo.
Operación en la clase BibliotecarioServicio (que restringiremos en la capa REST a bibliotecarios):
-
Realizar la devolución de un ejemplar: se pasa el identificador de ejemplar, se cierra el préstamo y se crea una multa si la devolución está fuera de plazo. Se devuelve un enumerado con el resultado de la devolución:
DEVOLUCIÓN_CORRECTAoDEVOLUCIÓN_FUERA_DE_PLAZO.
Operaciones en la clase LibroServicio (que no restringiremos en la capa REST):
-
Búsqueda de libros por autor: se pasa una cadena de texto y se devuelve la lista de libros que tienen un autor cuyo nombre contiene esa cadena de texto
-
Búsqueda de libros por título: se pasa una cadena de texto y se devuelve la lista de libros cuyo título contiene esa cadena de texto
-
Búsqueda de libro por identificador: se pasa el identificador del libro y se devuelven los detalles del libro y una colección con sus ejemplares
Para implementar estas funcionalidades tendrás que:
-
Añadir las anotaciones JPA a las clases restantes y completar el fichero de pruebas
PersistenciaTestcon pruebas de las relaciones y de las restricciones:-
Usuario(abstracta) y su relación de herencia conAlumnoyProfesor -
Prestamo -
Multa -
Bibliotecario
-
-
Crear las clases DAO y los ficheros de pruebas correspondientes:
-
UsuarioDao -
PrestamoDao -
MultaDao -
BibliotecarioDao
-
-
Crear los enterprise beans con los métodos de negocio:
-
UsuarioServicio:-
recuperarUsuario(String login) -
prestamosActivos(Long idUsuario) -
obtenerPrestamo(Long idUsuario, Long idLibro)
-
-
BibliotecarioServicio:-
devolverEjemplar(Long idUsuario, Long idEjemplar)
-
-
LibroServicio(completar):-
buscarLibrosAutor(String autor) -
buscarLibrosTitulo(String titulo) -
obtenerLibro(Long idLibro)Para devolver resultados erróneos (por ejemplo, si se llama a
obtenerPrestamopor un usuario multado) deberás lanzar una excepción en el método del bean. Puedes añadir nuevas excepciones, que hereden de la claseBibliotecaException. Esas excepciones se capturarán en la capa de servicio REST y se devolverán formateadas y con un código de error HTTP.
-
-
-
Deberás crear los tests Arquillian correspondientes para comprobar que funcionan correctamente los métodos de negocio. Si lo crees conveniente puedes también añadir algún servlet adicional con el que probarlos manualmente.
En las pruebas de Arquillian en las que debas modificar la base de datos deberás hacer un rollback una vez terminado el test, para dejar todos los datos sin modificar y que un test no afecte al resto. Por ejemplo, el siguiente test comprueba que un libro se crea (llamando a un supuesto método de negocio
nuevoLibro) y que después se obtiene correctamente. Al final se hace unsetRollbackOnlypara que el servidor de aplicaciones deshaga la transacción y deje la base de datos como estaba al principio.@Test public void creaNuevoLibroYEncuentraloTest() throws SystemException, NotSupportedException { userTransaction.begin(); Libro libro = libroServicio.nuevoLibro("0201485672", "Martin Fowler", "Refactoring: Improving the Design of Existing Code"); Libro libro2 = libroServicio.obtenerLibro(libro.getId()); assertTrue(libro.equals(libro2)); userTransaction.setRollbackOnly(); }
3.3.1. Entrega
La fecha de entrega del proyecto será el jueves 8 de enero.
Añade la etiqueta sesion-2 al respositorio después de hacer el último commit y sube los cambios al repositorio jbibrest-proyint-expertojava en Bitbucket:
$ git tag -a sesion-2 -m "Sesión 2"
$ git push origin --tagsRecuerda dar premiso de lectura al usuario entregas-expertojava y confirmar la entrega en Moodle. <<<
4. (1,5 puntos) Servicio REST
En esta sesión continuaremos trabajando con la parte del servidor del proyecto de integración. Implementaremos la capa REST del proyecto, utilizando JAX-RS para definir el API y basándonos en las funcionalidades implementadas en la capa de negocio de la sesión anterior. Las características básicas del API REST a desarrollar serán:
-
Interfaz REST a las funcionalidades implementadas por los EJBs de la capa de negocio
-
Trabaja con objetos JSON
-
Implementa el login y las restricciones de seguridad usando el método BASIC
-
Convierte las excepciones generadas por las capas inferiores en códigos de error HTTP
Todas las clases necesarias las crearemos en el paquete org.expertojava.jbibrest.rest.
Todas las URIs de las peticiones tendrán el prefijo /jbib-rest/api/. Por ejemplo: GET http://<servidor>/jbib-rest/api/libros/0321127420.
Es interesante consultar algunos ejemplos de APIs REST que trabajan con JSON. Algunas sencillas:
-
The Star Wars API: http://swapi.co
-
Pokemon API: http://pokeapi.co
Otras algo más complicadas:
-
OpenWeatherMap: http://openweathermap.org/api
-
Marvel: http://developer.marvel.com
4.1. Pantallas y esquema de navegación del cliente
Para poner en contexto el API REST que vamos a desarrollar, es conveniente considerar cómo va a ser utilizada desde la aplicación cliente. La aplicación cliente tendrá las siguientes pantallas:
-
Login
-
Listado de libros
-
Listado de préstamos activos y multa activa
-
Detalle de libro
Se podrá navegar entre ellas según el siguiente esquema:
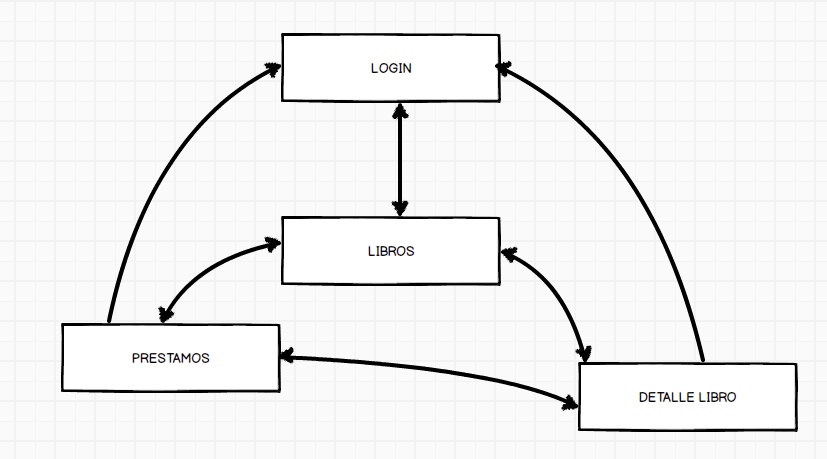
4.1.1. Acceso
Llamará al método GET /usuarios/{usuario}. {usuario} es el login del usuario, no su ID. Si devuelve error 401 nos mantenemos en la página. Cualquier error 401 en cualquier otra petición redirige aquí, Si devuelve información del usuario, vamos al listado de libros.
4.1.2. Listado de libros
Se devuelven todos los libros y se hace la paginación en el cliente.
4.1.3. Detalle de libro
Llamará tanto a GET /libros/{isbn} como a GET /libros/{isbn}/recomendaciones?numrec=3. Aprovecharemos el mismo componente del listado de libros para las recomendaciones.
El botón de pedir préstamo sólo aparecerá si el libro tiene ejemplares disponibles (lo debe indicar la información devuelta por el GET /libros) y si el usuario logeado en el cliente no tiene multas pendientes. Si la petición POST a prestamos devuelve un error se mostrará un alert indicando el motivo del error.
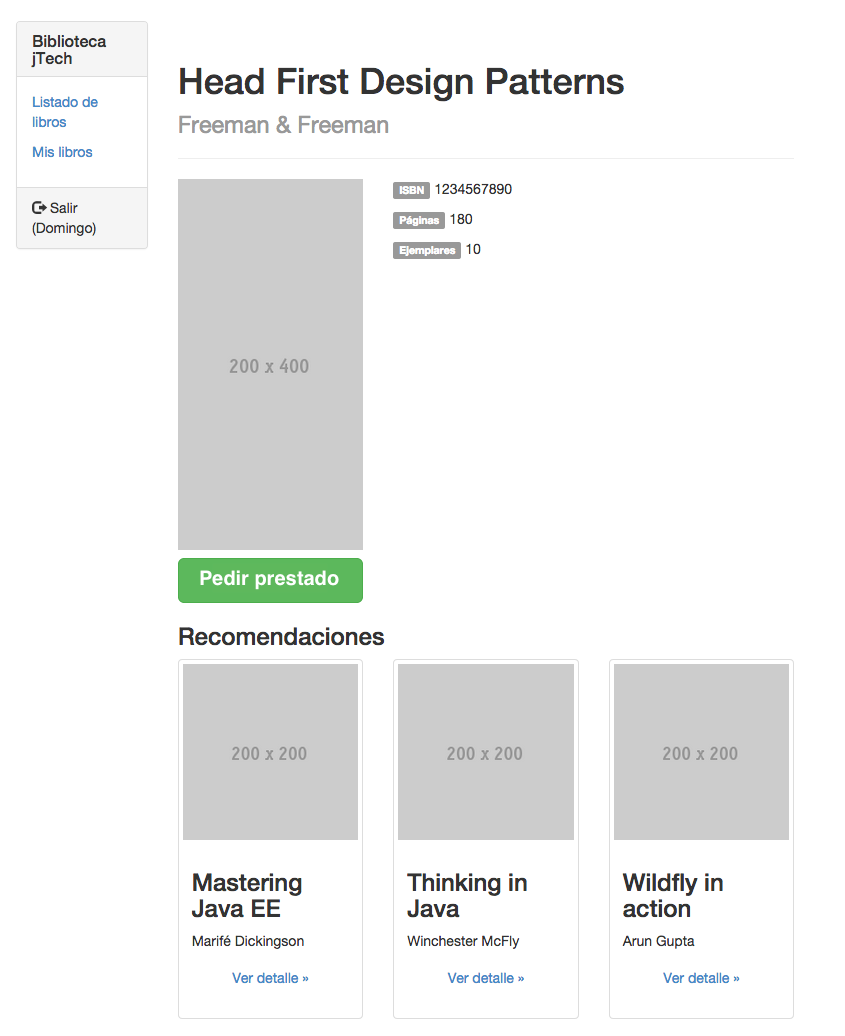
4.1.4. Mis libros
Muestra el listado de reservas del usuario. En la tabla, saldrán en rojo aquellos libros cuya fecha de devolución ha vencido, y en amarillo aquellos cuya fecha de devolución sea igual o inferior a tres días.
4.2. API REST
4.2.1. Clases JSON
El API REST trabajará con representaciones JSON de los objetos. Utilizaremos JAXB para mapear JSON en objetos y definiremos las clases necesarias también el paquete org.expertojava.jbibrest.rest.
Recomendamos usar clases específicas para cada caso de uso, nombrándolas con el nombre del modelo como prefijo y un sufijo relacionado con el caso de uso o pantalla de la aplicación cliente en la que se van a mostrar los datos. Por ejemplo: LibroDetalle para los datos devueltos por GET /libros/{isbn} o LibroItem para los elementos de la colección devuelta por GET /libros.
4.2.2. Seguridad
Utilizaremos la autenticación HTTP BASIC en cada petición, enviando una cabecera Authorization con la cadena usuario:contraseña codificada en base64. Ejemplo: Authorization: Basic bG9naW46cGFzc3dvcmQ=.
4.2.3. Usuarios
-
GET /usuarios/{usuario}: Restringida al usuario. Devuelve la info actual del usuario, su estado, num. préstamos activos, días de multa, etc.
Ejemplo:
GET http://localhost:8080/jbib-rest/api/usuario/antonioperezResultado:
{
"id": 1,
"email": "antonio.perez@gmail.com"
"nombre": "Antonio",
"apellido1": "Pérez",
"apellido2": "Barrio",
"estado": "multado",
"tipo_usuario": "alumno",
"multas": [{"fecha": "2015-01-25"}],
"num_prestamos": 1
}-
GET /usuarios/{usuario}/prestamos: Restringida al usuario. El usuario es el identificador. Devuelve colección de libros (libro y ejemplar) que tiene prestados un usuario. Cada ítem contiene la URI que representa el enlace al recurso correspondiente (HATEOAS)
Ejemplo:
GET http://localhost:8080/jbib-rest/api/usuarios/1/prestamosResultado:
[
{
"fecha_prestamo": "2015-01-01",
"fecha_devolucion": 2015-01-31",
"libro": {
"resource_uri": "http://localhost:8080/jbib-rest/api/libros/0321127420",
"isbn": "0321127420",
"titulo": "Patterns Of Enterprise Application Architecture",
"ejemplar_id": 1
}
},
{
"fecha_prestamo": "2014-12-20",
"fecha_devolucion": 2015-01-20",
"libro": {
"resource_uri": "http://localhost:8080/jbib-rest/api/libros/0132350882",
"isbn": "0132350882",
"titulo": "Clean Code",
"ejemplar_id": 3
}
}
]-
POST /usuarios/{usuario}/prestamos: Restringida al usuario. Se envía por POST el isbn del libro (no la información del ejemplar como se decía en una versión anterior de este enunciado) y se realiza un préstamo. Se devuelve OK o un error cuando el ejemplar no está disponible o el usuario está multado. -
POST /usuarios/{usuario}/devoluciones: Restringida al bibliotecario. Se envía por POST el identificador del ejemplar y se realiza la devolución.
4.2.4. Libros
-
GET /libros: Devuelve la lista de todos los libros. Cada ítem de libro contiene un enlace al recurso (HATEOAS). Búsqueda por autor o título:?autor=`y `?titulo=.
Ejemplo:
GET http://localhost:8080/jbib-rest/api/libros?autor=MartinResultado:
[
{
"resource_uri": "http://localhost:8080/jbib-rest/api/libros/0321127420",
"isbn": "0321127420",
"titulo": "Patterns Of Enterprise Application Architecture",
"autor": "Martin Fowler",
"image": "http://localhost:8080/jbib-rest/media/img/0321127420.png",
},
{
"resource_uri": "http://localhost:8080/jbib-rest/api/libros/0132350882",
"isbn": "0132350882",
"titulo": "Clean code"
"autor": "Robert C. Martin",
"image": "http://localhost:8080/jbib-rest/media/img/0132350882.png"
}
]-
GET /libros/{isbn}: Datos de un libro, número de ejemplares totales y número de ejemplares disponibles. -
GET /libros/{isbn}/recomendaciones?numrec=: Lista de libros recomendados relacionados con un libro dado (HATEOAS).
4.3. Pruebas
Debido a la extensión de esta sesión (y de las anteriores), no son obligatorias las pruebas automáticas del API REST. Puedes probar el API de forma manual usando el cliente REST de IntelliJ o el plug-in Postman de Google Chrome.
4.4. Entrega
La fecha de entrega del proyecto será el jueves 22 de enero.
Añade la etiqueta sesion-3 al respositorio después de hacer el último commit y sube los cambios al repositorio jbibrest-proyint-expertojava en Bitbucket:
$ git tag -a sesion-3 -m "Sesión 3"
$ git push origin --tagsRecuerda dar premiso de lectura al usuario entregas-expertojava y confirmar la entrega en Moodle.
5. (1,5 puntos) Despliegue en plataforma en la nube
En esta sesión vamos a utilizar los conocimientos que hemos adquirido durante las sesiones de PaaS para desplegar la parte del servidor en la nube, utilizando OpenShift.
Como resumen realizaremos las siguientes tareas:
-
Revisión del proyecto pom.xml del proyecto.
-
Revisión del entorno local de pruebas.
-
Configuración y despliegue de la capa de servidor en OpenShift.
-
Utilizar Integración Continua mediante Shippable a partir de nuestro repositorio en Bitbucket.
5.1. Revisión del proyecto pom.xml
La definición actual del proyecto pom.xml tiene algunos aspectos que debemos mejorar, sobre todo pensando en que vamos a intentar realizar un despliegue lo más cercano a lo que podríamos hacer en un proyecto "real".
-
El proyecto trabaja con dependencias codificadas con versiones que no tienen porqué ser las que incluye el servidor de aplicaciones. Salvo causa de fuerza mayor ya sabemos que es recomendable utilizar el conjunto de librerías del servidor pues entre otras cosas están validadas para trabajar en conjunto.
-
No está pensado para utilizar diferentes versiones del servidor de aplicaciones según la plataforma destino. Recordad que actualmente desarrollamos con WildFly 8.1 pero en OpenShift se trabaja con WildFly 8.2.
-
Perfiles. El pom.xml original no define ningún perfil. En el escenario en el que nos vamos a mover necesitaremos tres perfiles distintos:
-
arq-remote que será el perfil que hemos utilizado hasta ahora para realizar la compilación y pruebas del proyecto. En este perfil Arquillian trabaja contra un servidor de aplicaciones que se encuentre en ejecución en nuestro equipo.
-
arq-managed este perfil será el que se utilice para compilar y probar el proyecto en Shippable. La diferencia con el perfil anterior es que Arquillian se encargará de ejecutar WildFly para lanzar las pruebas, y que además generaremos informes de Cobertura de pruebas. Este perfil se puede utilizar en local siempre y cuando tengamos definido la variable de entorno JBOSS_HOME apuntando a la carpeta de WildFly /usr/local/wildfly/.
-
openshift como ya sabemos es el perfil que utilizará OpenShift para compilar el proyecto: mvn clean package -Popenshift -DskipTests
-
En su lugar proponemos el siguiente fichero pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.expertojava.proyint</groupId>
<artifactId>jbib-rest</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging>
<name>jbib-rest</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- Define the version of the JBoss BOMs we want to import to specify tested stacks. -->
<wildfly.version>8.1.0.Final</wildfly.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.wildfly.bom</groupId>
<artifactId>jboss-javaee-7.0-with-tools</artifactId>
<version>${wildfly.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.wildfly.bom</groupId>
<artifactId>jboss-javaee-7.0-with-hibernate</artifactId>
<version>${wildfly.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-web-api</artifactId>
<version>7.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<scope>provided</scope>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<scope>provided</scope>
<version>1.2</version>
</dependency>
<!-- Tests -->
<!-- Import the JPA API, we use provided scope as the API is included in JBoss WildFly -->
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.1-api</artifactId>
<scope>test</scope>
</dependency>
<!-- Quitamos el scope test para que no de error el
elemento provider del persistence.xml de runtime-->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.33</version>
<scope>test</scope>
</dependency>
<!-- DbUnit -->
<dependency>
<groupId>org.dbunit</groupId>
<artifactId>dbunit</artifactId>
<version>2.5.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.7</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>test</scope>
</dependency>
<!-- Bean Validation -->
<!-- JSR-303 (Bean Validation) Implementation -->
<!-- Provides portable constraints such as @Email -->
<!-- Hibernate Validator is shipped in JBoss WildFly -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Arquillian -->
<dependency>
<groupId>org.jboss.arquillian.junit</groupId>
<artifactId>arquillian-junit-container</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<profiles>
<profile>
<id>arq-remote</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<dependencies>
<dependency>
<groupId>org.wildfly</groupId>
<artifactId>wildfly-arquillian-container-remote</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<finalName>${project.name}</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.17</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>2.3</version>
<configuration>
<failOnMissingWebXml>false</failOnMissingWebXml>
</configuration>
</plugin>
<plugin>
<groupId>org.wildfly.plugins</groupId>
<artifactId>wildfly-maven-plugin</artifactId>
<version>1.0.2.Final</version>
<configuration>
<hostname>localhost</hostname>
<port>9990</port>
</configuration>
</plugin>
</plugins>
</build>
</profile>
<profile>
<id>arq-managed</id>
<dependencies>
<dependency>
<groupId>org.wildfly</groupId>
<artifactId>wildfly-arquillian-container-managed</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<finalName>${project.name}</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>cobertura-maven-plugin</artifactId>
<version>2.6</version>
<configuration>
<format>xml</format>
<maxmem>256m</maxmem>
<aggregate>true</aggregate>
<outputDirectory>shippable/codecoverage</outputDirectory>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.17</version>
<configuration>
<redirectTestOutputToFile>true</redirectTestOutputToFile>
<reportsDirectory>shippable/testresults</reportsDirectory>
</configuration>
<dependencies>
<dependency>
<groupId>org.apache.maven.surefire</groupId>
<artifactId>surefire-junit4</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>2.3</version>
<configuration>
<failOnMissingWebXml>false</failOnMissingWebXml>
</configuration>
</plugin>
<plugin>
<groupId>org.wildfly.plugins</groupId>
<artifactId>wildfly-maven-plugin</artifactId>
<version>1.0.2.Final</version>
<configuration>
<hostname>localhost</hostname>
<port>9990</port>
</configuration>
</plugin>
</plugins>
</build>
</profile>
</profiles>
</project>5.1.1. Tareas
-
Reemplazar el pom.xml antiguo por el propuesto.
-
Añadir el perfil openshift para que se pueda desplegar correctamente en PaaS
-
Definir un MANIFEST.MF que referencie a los módulos org.apache.commons.logging y org.apache.log4j que forman parte del paquete de librerías de WildFly y no es necesario incluirlos en el WAR.
Con estos cambios conseguiremos que la aplicación pase de unos 6Mb a 56kb aproximadamente gracias al uso de paquetes de dependencias tipo BOM . Ademas el pom admitirá una serie de parámetros:
mvn [goal]… -P[perfil] -Dwildfly.version[versión]
Por defecto el perfil será arq-remote y la versión 8.1.0.Final
5.2. Revisión del entorno local de pruebas
El objetivo final es que utilicemos Integración continua para desplegar nuestra aplicación con lo que debemos modificar ciertos aspectos de la configuración actual del proyecto de modo que sea más portable:
-
Utilizar una base de datos distinta de la de trabajo para pruebas y que coincida con la que Shippable nos proporciona.
-
Deshabilitar los test de Arquillian. Esta es una cuestión que nos hemos encontrado al probar contra Shippable. El orden de ejecución de los test no tiene porqué ser el esperado en local y en algunos casos se producen errores si los test no se ejecutan en orden.
5.2.1. Tareas
-
Exportar el contenido actual de la base de datos biblioteca a un fichero SQL mediante el comando:
mysqldump -u root -p biblioteca > fichero.sqlEl fichero.sql lo necesitaremos para cargar la instancia de MySQL de OpenShift.
-
Crear una base de datos local de nombre test y un usuario shippable sin password que tenga permisos de administrador sobre ella. Podéis utilizar cualquier herramienta como MySQL WorkBench.
-
Modificar la configuración de acceso a base de datos de los Test de los DAO’s de modo que apunten a la BD de pruebas que acabamos de crear:
.getConnection(
"jdbc:mysql://localhost/test",
"shippable", "");-
Modificar la unidad de persistencia persistence.xml de pruebas de modo que apunte a la nueva base de datos de test.
value="jdbc:mysql://localhost:3306/test"/>-
Modificar los test de Arquillian UsuarioServicioTest,LibroServicioTest y BibliotecarioServicioTest
-
Crear un Datasource de nombre test-ds.xml en /src/test/resources:
-
<?xml version="1.0" encoding="UTF-8"?>
<datasources xmlns="http://www.jboss.org/ironjacamar/schema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.jboss.org/ironjacamar/schema http://docs.jboss.org/ironjacamar/schema/datasources_1_0.xsd">
<xa-datasource jndi-name="java:/datasources/test" pool-name="MySQLTest" enabled="true" use-ccm="true">
<xa-datasource-property name="URL">
jdbc:mysql://localhost/test
</xa-datasource-property>
<xa-datasource-class>com.mysql.jdbc.jdbc2.optional.MysqlXADataSource</xa-datasource-class>
<driver>mysql-connector-java-5.1.34-bin.jar_com.mysql.jdbc.Driver_5_1</driver>
<security>
<user-name>shippable</user-name>
</security>
</xa-datasource>
</datasources>-
Incluir el datasource en el war de pruebas:
.addAsResource("persistence-datasource.xml",
"META-INF/persistence.xml")
.addAsWebInfResource("test-ds.xml",
"test-ds.xml") // Incluir el datasource
.addAsWebInfResource(EmptyAsset.INSTANCE, "beans.xml");-
Deshabilitar los test de la capa de Servicio temporalmente para que no den error en Shippable (hasta nueva orden)
@RunWith(Arquillian.class)
@Ignore("not ready yet") // Nueva anotación
public class BibliotecarioServicioTest {
Con estos cambios podréis ejecutar en local las pruebas contra la nueva base de datos. Ahora os saldrán menos casos de pruebas ejecutados al haber deshabilitado los de la capa servicio.
5.3. Configuración y despliegue de la capa de servidor en OpenShift
En esta parte crearemos una aplicación escalable con soporte de BD MySQL y añadiremos el código fuente de la capa REST.
5.3.1. Tareas
-
Crear una aplicación escalable, de nombre jbibrest con los cartridges de WildFly 8 y MySQL. (Si por lentitud os tardase demasiado podéis configurarla como no escalable, es una buena práctica pero no es requerido por el ejercicio).
-
Eliminar el código fuente de ejemplo (pom.xml y carpeta src).
git rm -r src/ pom.xml
git commit -m "borrado plantilla"-
Inicializar manualmente el contenido de la BD MySQL de OpenShift a partir del fichero de backup que creamos en el primer apartado.
-
Añadir un repositorio Git remoto (el de bitbucket):
git remote add bitbucket https://[usuario]@bitbucket.org/[usuario]/[repositorio].git-
Hacer un "pull" del repositorio de Bitbucket para traernos los fuentes de nuestro proyecto:
git pull bitbucket master-
Definir en el fichero standalone.xml de la configuración, el datasource XA BibliotecaDS. Fijaos que OpenShift por defecto crea una BD de WildFly con el mismo nombre que la aplicación (jbibrest) por tanto utilizad esta BD en el datasource. Recordad que debéis trabajar con las variables de entorno en lugar de con valores fijos.
-
Hacer un push al repositorio de Bitbucket para almacenar el proyecto actualizado con los ficheros de configuración de OpenShift.
git add .
git commit -m "integración con OpenShift"
git push bitbucket master-
Hacer un push al repositorio de OpenShift y asegurarnos de que la aplicación está funcionando correctamente en http://jbibrest-[usuario].rhcloud.com.
git push origin master-
Por último, dar de alta dos usuarios en el ApplicationRealm de WildFly:
| Usuario | Password | Rol |
|---|---|---|
usu1 |
expertojava |
usuario |
biblio1 |
expertojava |
bibliotecario |
5.4. Utilizar Integración Continua mediante Shippable a partir de nuestro repositorio en Bitbucket.
Dada la lentitud de los gear gratuitos de OpenShift es preferible utilizar un proveedor de CI externo, como pueda ser Shippable. Shippable tiene varias ventajas sobre otras opciones.
-
Nos proporciona una instancia de CI de forma gratuita.
-
Integración con OpenShift, GitHub y BitBucket.
-
Uso muy sencillo, mediante un script YAML.
-
Uso de imágenes de Docker como base para realizar las pruebas. Se configura el entorno de pruebas desde cero en cada prueba con los elementos que necesitamos.
-
Acceso simple mediante Oauth utilizando vuestras credenciales de Bitbucket.
La idea es que ante cualquier cambio que subáis a vuestro repositorio de BitBucket, se active una instancia de Shippable, recoja estos cambios, haga las pruebas que hayamos definido y si todo es correcto, lo despliegue en el gear de OpenShift.
5.4.1. Tareas
-
Crear un script de integración continua donde se detallan los pasos para configurar el entorno y realizar las pruebas. El fichero se llamará shippable.yml y se situará al mismo nivel que el fichero pom.xml.
El contenido del fichero será el siguiente:
language: java
jdk:
- openjdk7
env:
global:
- JBOSS_HOME=/tmp/wildfly-8.2.0.Final
- JBOSS_SERVER_LOCATION=http://download.jboss.org/wildfly/8.2.0.Final/wildfly-8.2.0.Final.tar.gz
- OPENSHIFT_REPO=ssh://54bd8f985973ca36b6000025@jbibrest-jlzamora.rhcloud.com/~/git/jbibrest.git
- MYSQL_DRIVER=http://www.jtech.ua.es/experto/publico/mysql-connector-java-5.1.34-bin.jar
- MYSQL_DRIVER_DEST=/tmp/wildfly-8.2.0.Final/standalone/deployments/mysql-connector-java-5.1.34-bin.jar
before_install:
- if [ ! -e $JBOSS_HOME ]; then curl -s $JBOSS_SERVER_LOCATION | tar zx -C /tmp; fi
- curl -s $MYSQL_DRIVER >$MYSQL_DRIVER_DEST
- git remote -v | grep ^openshift || git remote add openshift $OPENSHIFT_REPO
before_script:
- mkdir -p shippable/testresults
- mkdir -p shippable/codecoverage
- mysql -e 'create database test;'
script:
- mvn clean test cobertura:cobertura -Parq-managed -Dwildfly.version=8.2.0.Final
after_success:
- git push -f openshift $BRANCH:masterEste script descarga y descomprime la misma versión de WildFly que se utilizará en OpenShift, prepara el entorno para lanzar las pruebas y si las pruebas concluyen con éxito hace un push del código al respositorio Git de OpenShift. También hemos subido a la web de Jtech el driver de MySQL que utilizaremos en las pruebas, y que el script copia diretamente a deployments.
Debeis modificar el script con la ruta SSH a vuestro gear concreto
-
Acceder a http://www.shippable.com autenticándonos con el usuario/password de Bitbucket. Esto nos permitirá listar nuestros proyectos.
-
En el panel de la derecha saldrá nuestro usuario de BitBucket y podremos seleccionar un repositorio para habilitar integración continua. Seleccionar el repositorio del proyecto de la capa REST.
-
Obtener la "Developer Key" de nuestra sesión en Shippable. Esta clave se debe registrar en WildFly para que quede constancia de que damos permisos a Shippable para subir código a los repositorios Git gestionados por OpenShift. Dentro de Shippable, pulsaremos en Organizations → bitbucket/<usuario> Y luego en deployment key.
-
En Settings de OpenShift, daremos de alta esta clave como public key. El nombre asociado puede ser el que queráis, por ejemplo Shippable
Hacer un push únicamente al repositorio de Bitbucket. Si lo hemos hecho todo bien, se iniciará una tarea de compilación en Shippable y podremos seguir paso a paso todo el proceso. Si falla algo, revisad la ejecuión de los pasos en busca del error concreto que se haya producido.
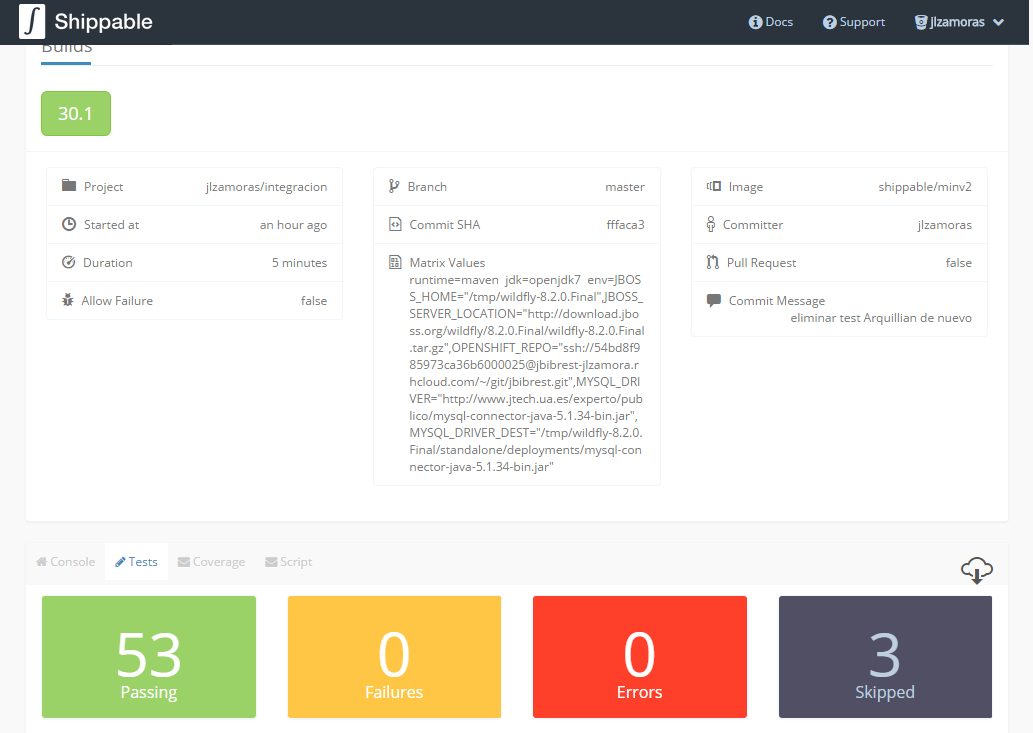
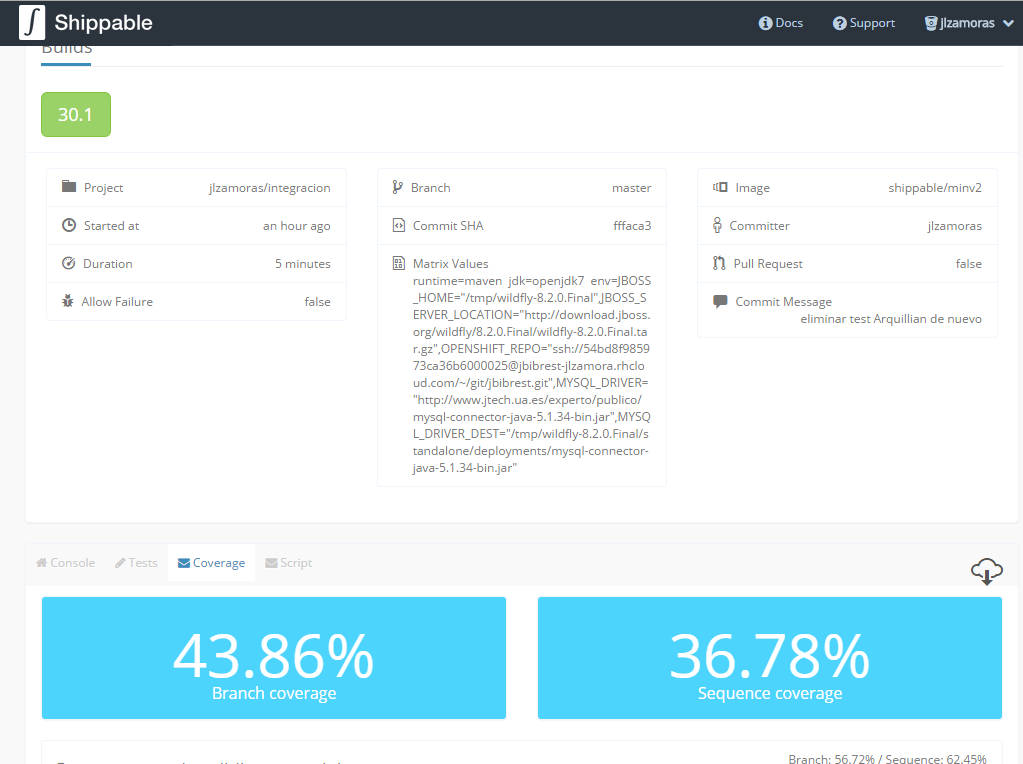
Si todo es correcto, para trabajar en futuras sesiones de integración bastaría con clonarnos el repositorio de Bitbucket a local y gracias a Shippable podremos desplegar nuestros cambios en OpenShift sin necesidad de tener nada configurado, únicamente subiendo los cambios a Bitbucket.
5.5. Entrega
La fecha de entrega del proyecto será el jueves 12 de marzo.
Añade la etiqueta sesion-4 al respositorio después de hacer el último commit y sube los cambios al repositorio jbibrest-proyint-expertojava en Bitbucket:
$ git tag -a sesion-4 -m "Sesión 4"
$ git push origin --tagsRecuerda dar premiso de lectura/escritura al usuario entregas-expertojava y confirmar la entrega en Moodle. Una de las pruebas será modificar el código fuente y comprobar que los cambios se despliegan correctamente en OpenShift.
Adicionalmente revisaremos que la aplicación esté desplegada correctamente en OpenShift accediendo a la URL convenida:
http://jbibrest-[usuario].rhcloud.com.
Para verificar que la parte de integración continua funciona correctamente os pediremos un fichero de log de Shippable. Este se puede obtener pulsando en el icono en forma de nube que se muestra junto con la información de cada build:

Si os diese errores la parte de integración continua con Shippable u os resulta compleja de configurar, podéis entregar el ejercicio simplemente activando la opción de Integración continua con Jenkins que integra OpenShift, pero tendrá las siguientes limitaciones:
-
La aplicación jbibrest no puede ser escalable porque sólo para pruebas ya vamos a necesitar 2 gears.
-
Los test de Arquillian son costosos de ejecutar sobre los gears gratuitos así que es posible que las tareas de Jenkins no acaben correctamente.
-
No vais a tener integración entre Bitbucket y el repositorio de Git por tanto debéis copiar los fuentes manualmente de un repositorio a otro.
-
Mucho más fácil = Menos puntuación y menos interesante…
5.6. Referencias
6. (3 puntos) Cliente AngularJS
En esta sesión vamos a hacer uso de los servicios REST implementados, y vamos a crear una interfaz web realizada en HTML5 + Bootstrap + AngularJS para consumir dichos servicios a través de una aplicación web SPA.
Dado que estamos trabajando con clientes ricos y aplicaciones desacopladas, nuestra aplicación web se desarrollará en un proyecto independiente del proyecto java, y también se ejecutará en otro servidor.
Las ventajas de esta arquitectura son múltiples. Al tratarse nuestra aplicación web de un consumidor de servicios, sería muy fácil crear una aplicación móvil con Apache Cordova, o una aplicación de escritorio con NW.js. Simplemente habría que introducir el código del ejercicio en la carpeta webapps de cada plataforma.
|
Aunque la aplicación es responsive, la maquetación llevada a cabo no se adapta del todo bien a dispositivos móviles. Aunque las aplicaciones se puedan adaptar correctamente, en mi opinión los dispositivos móviles suelen utilizar otros patrones y el desarrollo de la interfaz no debería ser adaptable, sino específico para éstos. Es por ello que considere a ionic framework algo imprescindible para las interfaces de aplicaciones móviles, pudiendo reaprovechar lógica de negicio existente en servicios, filtros y algunas directivas.. |
Mediante el uso de Bootstrap, estamos garantizando un diseño responsive que se adapta de manera adecuada a todo tipo de dispositivos. Aunque la solución idónea para dispositivos móviles pasa por Ionic Framework: un framework basado en AngularJS y con ui-router como gestor de rutas que se ha convertido en el framework de referencia a la hora de desarrollar aplicaciones móviles híbridas.
6.1. Fork del repositorio
Empezaremos realizando un fork del repositorio https://bitbucket.org/java_ua/angular-proyint-expertojava. Éste tiene una base de código sobre la que empezaremos.
6.2. Instalación de las dependencias del proyecto
Fijémonos en los ficheros .bowerrc y package.json. En éstos se definen las dependencias de nuestro proyecto, de igual manera que maven lo hace con los paquetes java que podamos necesitar. El hecho de usar un gestor de dependencias hace que el tamaño de nuestro repositorio sea mucho más liviano, que podamos ver las versiones de nuestras dependencias de una manera sencilla (el fichero indica la versión), y que todos los desarrolladores trabajen con las mismas versiones de las librerías dependientes.
Para instalarnos las dependencias, ejecutaremos, desde la línea de comandos y poniéndonos en la raíz de nuestro proyecto:
$ npm installCon esto habremos instalado las librerías que necesitamos para automatizar tareas. Ahora, para instalar las dependencias de nuestra aplicación web, ejecutaremos el comando:
$ bower installYa tenemos instaladas todas las dependencias. El gestor también nos habrá instalado un pequeño servidor web, que utilizaremos para probar nuestra aplicación. Podemos lanzarlo mediante el comando:
$ node node_modules/webserver/webserver.jsSi todo va bien, deberíamos obtener la salida:
WEBROOT.
Listening @ 8003Así, ya tenemos un servidor corriendo y escuchando en el puerto 8003, y otro servidor con un WildFly escuchando en el puerto 8080. También podemos utilizar el servidor que tenemos desplegado en OpenShift para probar y tener más presente el desacoplamiento. Sin embargo, y por comodidad, el ejercicio se corregirá probándolo contra un servidor local y toda la configuración deberá dejarse preparada de esta manera.
6.3. CORS en clientes web
En sesiones anteriores, se ha creado un filtro para que la aplicación soporte CORS (Cross-Origin Resource Sharing). Vamos a tener que realizar alguna modificación más sobre nuestro código Java.
Esto se debe a que muchas peticiones requieren una comunicación extra entre el cliente y el servidor antes de realizar una petición GET, POST, PUT o DELETE. A esto se le conoce como preflight request, y es una llamada al servidor, sin payload, y que se envía con una cabecera OPTIONS.
Es por ello que debemos preparar nuestro código Java para que acepte este tipo de llamadas. Esto podríamos resolverlo de dos maneras:
-
Creando una función para cada llamada con la anotación
@OPTIONSy devuelva un código de respuesta200 OK. -
Creando un filtro que devuelva una respuesta
200 OKen cada petición con cabeceraOPTIONSdirectamente desde el filtro, sin llegar a pasar por la lógica de negocio.
Para el ejercicio, se ha optado por la primera opción, al considerarla más restrictiva.
Un ejemplo concreto, para la clase UsuarioResource, sería el siguiente:
@OPTIONS
@Consumes({"application/json"})
@Path("{usuario}/prestamos")
public Response realizarPrestamoOptions(@PathParam("usuario") String login) {
return Response.ok().build();
}Antes de realizar un préstamo, se enviará una petición sin payload al servidor y con la cabecera OPTIONS. Si la respuesta es correcta, será entonces cuando se envíe la petición POST.
Para aliviar la tarea de implementar estos servicios, se adjuntan versiones modificadas de las clases de recursos, con estas anotaciones añadidas:
6.4. Aplicación web
Como hemos dicho, la aplicación web estará desarrollada en AngularJS, y hará uso de los servicios REST implementados.
El código de la aplicaión (javascript y HTML) está incompleto, y tendremos que terminarlo para que ésta funcione.
Se ha puesto un TODO allá donde haga falta realizar algo. IntelliJ Idea tiene una vista de TO-DOs, donde podemos verlos todos juntos para que no se nos pase ninguno:
La funcionalidad se corresponderá con las funcionalidades asocidadas a un usuario, y pasamos a ver en los siguientes pantallazos:
6.4.1. Login
Será el punto de entrada a la aplicación, y desde la que el usuario introducirá sus credenciales de acceso:
Si las credenciales introducidas son incorrectas, se indicará al usuario mediante un mensaje:
El sistema de autenticación
6.4.2. Listado de libros
Inmediatamente después de acceder a la aplicación, veremos el listado de libros:
Cada libro es una directiva que tendremos que terminar de implementar. Además, como el serivcio REST nos devuelve la miniatura de la imagen, vamos a implementar un filtro que modifique la cadena para que devuelva la imagen a tamaño completo. No queremos modificar el servicio, sino lo que éste nos devuelve y por eso lo vamos a hacer desde el lado del cliente.
6.4.3. Detalle de un libro
Muestra el detalle de un libro:título, autor, isbn, número de ejemplares total y número de ejemplares disponibles. Además, habrá un botón Volver que hará un history.back() del navegador y un botón Reservar, que invocará al servicio de reservas.
Si se puede realizar la reserva de manera correcta, se mostrará una alerta en verde. Si por el contrario no se puede realizar la reserva, se mostrará un mensaje en rojo y el motivo (por ejemplo: usuario no válido porque tiene una multa). El fichero UsuarioResource ya captura excepciones y manda un mensaje de error junto con una cabecera 403 (Forbidden) en caso de no poder realizar una reserva.
El detalle del libro es una directiva. Ésta muestra en rojo el número de ejemplares disponibles cuando es cero. Además, el botón de reservas deberá quedar deshabilitado si el número de ejemplares disponibles es cero. Si se está haciendo una reserva, el botón de reservar también se deshabilitará para evitar el doble click, y mostrará una rueda girando. La clase CSS de la rueda girando está preparada y se llama glyphicon-cog.
A continuación del detalle del libro tenemos la lista de libros relacionados. Deberá ser un máximo de 8, y reaprovecharemos la misma directiva empleada en el listado principal de libros.
6.4.4. Listado de préstamos
Mostrará todos los préstamos del usuario:
Aunque están marcados en azul sólo los títulos de los libros, haciendo click en cualquier lugar de la fila seremos llevados al detalle del libro.
Si la fecha de devolución de un préstamo ha vencido, el texto tendrá la clase text-alert para mostrarse en rojo.
En caso de no tener ningún préstamo, en lugar de mostrar la tabla, se enseñará un mensaje informativo:

Habrá que intentar que la vista no haga flickering, mostrando una cosa un milisegundo y luego mostrando otra.
6.4.5. Devoluciones.
La funcionalidad de devolución es responsabilidad del bibliotecario y queda fuera de este proyecto. En caso de necesitar hacer una devolución lo haremos a través de la aplicación Postman, o cualquier otro cliente REST.
6.5. Control de acceso
Se ha implementado un sencillo control de acceso en la aplicación. Lo podemos ver en el fichero jbib.js, en el método run de la aplicación. Básicamente consiste en que si no estamos en los states de nombre login o logout se mirará si el usuario está logado. Si no lo está, redirigirá a la pantalla de login.
6.6. Comunicación con el servidor
Toda la comunicación con el servidor se hará con el módulo ngResource, que hemos visto que facilita la integración con servicios REST.
Deberemos terminar la implementación de los siguientes servicios, que son los que favorecerán dicha comunicación:
-
booksResource.js
-
borrowService.js
-
relatedBooksResource.js
Observad en el código que borrowsService se ha concebido de manera ligeramente distinta: mientras los otros dos devuelven el propio recurso, éste implementa una factoría como las que hemos visto en clase.
6.7. Estructura del proyecto
Se ha tenido en cuenta algunas de las best practices a la hora de elaborar la estructura del proyecto. Cada funcionalidad está en una carpeta distinta (préstamos, libros, acceso, dashboard). Dentro de cada una de ellas, habrá una carpeta para servicios, directivas, controladores, filtros y vistas.
Las funcionalidades de login y gestión de acceso se han creado como módulos independientes, con la idea de poder ser reutilizados en otros proyectos.
.
├── books
│ ├── controllers
│ │ ├── bookController.js
│ │ └── booksController.js
│ ├── directives
│ │ ├── book
│ │ │ ├── book.html
│ │ │ └── book.js
│ │ └── book-detail
│ │ ├── book-detail.html
│ │ └── bookDetail.js
│ ├── filters
│ │ └── largeImg.js
│ ├── services
│ │ ├── booksResource.js
│ │ ├── borrowService.js
│ │ └── relatedBooksResource.js
│ └── views
│ ├── book.html
│ └── books.html
├── borrows
│ ├── controllers
│ │ └── borrowsController.js
│ └── views
│ └── borrows.html
├── bower_components
├── bower.json
├── components
│ ├── auth
│ │ ├── authInterceptor.js
│ │ ├── auth.module.js
│ │ └── authService.js
│ └── images
│ └── nophoto.png
├── dashboard
│ ├── directives
│ │ ├── navbar
│ │ │ ├── navbar.html
│ │ │ └── navbar.js
│ │ └── sidebar
│ │ ├── sidebar.html
│ │ └── sidebar.js
│ └── views
│ └── dashboard.html
├── dist
├── Gruntfile.js
├── index.html
├── jbib.css
├── jbib.js
├── login
│ ├── directives
│ │ ├── login-form.html
│ │ └── loginForm.js
│ ├── login.module.js
│ └── views
│ └── login.html
├── node_modules
├── package.json
├── tree.txt
└── tsd.json6.8. Automatización
Se han creado unas reglas de linting y minificación. En las etapas iniciales del desarrollo será complicado de usar, pero a medida que vayamos avanzando será necesario. La prueba de la aplicación se hará sobre el código minificado, y éste no se minificará si no pasa el linting.
Lanzado el siguiente comando desde la raíz del proyecto:
$ gruntSe ejecutará un listener que intentará pasar las reglas de JSHint y minificar el código cada vez que realizamos una modificación en el mismo. Así, sólo tendremos que refrescar el navegador cuando estas tareas se hayan realizado.
Si sólo queremos minificar el código sin que se ejecute ningún listener, haremos uso del comando:
$ grunt dist|
La carpeta |
6.9. Corrección
Aplica el tag FINAL al commit que quieras que se te corrija.