2. Entity Manager y contexto de persistencia
2.1. Introducción
En JPA todas las operaciones relacionadas con la persistencia de las entidades y el mapeado de estas entidades con la base de datos subyacente se realizan a través de un gestor de entidades (entity manager en inglés). El entity manager tiene dos responsabilidad fundamentales:
-
Define una conexión transaccional con la base de datos que debemos abrir y mantener abierta mientras estamos realizado operaciones. En este sentido realiza funciones similares a las de una conexión JDBC.
-
Además, mantiene en memoria una caché con las entidades que gestiona y es responsable de sincronizarlas correctamente con la base de datos cuando se realiza un flush. El conjunto de entidades que gestiona un entity manager se denomina su contexto de persistencia.
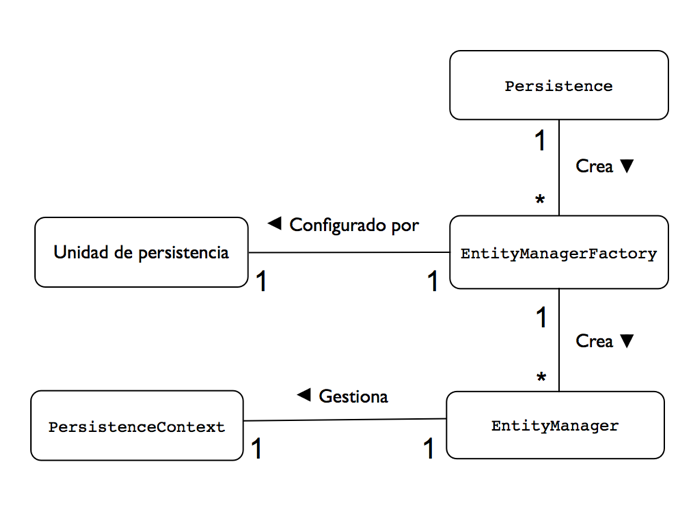
El entity manager se obtiene a través de una factoría del tipo EntityManagerFactory, que se configura mediante la especificación de una unidad de persistencia (persistence unit en inglés) definida en el fichero XML persistence.xml. En el fichero pueden haber definidas más de una unidad de persistencia, cada una con un nombre distinto. El nombre de la unidad de persistencia escogida se pasa a la factoría. La unidad de persistencia define las características concretas de la base de datos con la que van a trabajar todos los entity managers obtenidos a partir de esa factoría y queda asociada a ella en el momento de su creación. Existe, por tanto, una relación uno-a-uno entre una unidad de persistencia y su EntityManagerFactory concreto. Para obtener una factoría EntityManagerFactory debemos llamar a un método estático de la clase Persistence .
Las relaciones entre las clases que intervienen en la configuración y en la creación de entity managers se muestran en la siguiente figura.
2.1.1. Entidades gestionadas y desconectadas
Una vez creado el entity manager lo utilizaremos para realizar todas las operaciones de recuperación, consulta y actualización de entidades. Cuando un entity manager obtiene una referencia a una entidad, se dice que la entidad está gestionada (una managed entity en inglés) por él. El entity manager guarda internamente todas las entidades que gestiona y las utiliza como una caché de los datos en la base de datos. Por ejemplo, cuando va a recuperar una entidad por su clave primaria, lo primero que hace es consultar en su caché si esta entidad ya la ha recuperado previamente. Si es así, no necesita hacer la búsqueda en la base de datos y devuelve la propia referencia que mantiene. Al conjunto de entidades gestionadas por un entity manager se le denomina su contexto de persistencia (persistence context en inglés).
En un determinado momento, el entity manager debe volcar a la base de datos todos los cambios que se han realizado sobre las entidades. También debe ejecutar las consultas JPQL definidas. Para ello el entity manager utiliza un proveedor de persistencia (persistence provider en inglés) que es el responsable de generar todo el código SQL compatible con la base de datos.
En esta sesión estudiaremos las distintas operaciones que realiza el entity manager, así como el concepto de contexto de persistencia y las distintas problemáticas relacionadas con la gestión de esta caché de objetos persistentes y la sincronización con la base de datos subyacente.
Una vez que se cierra la transacción y se cierra el entity manager, éste desaparece pero las entidades gestionadas siguen estando en memoria, pero ahora en estado desconectado (detached en inglés). Podrían volverse a gestionar por un entity manager usando el método merge.
2.1.2. APIs de Java EE 7
Veremos una parte de la completa APIs de Java EE 7 sobre estas clases. Los siguientes métodos de la interfaz EntityManager son los más importantes y los estudiaremos en detalle en los siguientes apartados:
-
void clear(): borra el contexto de persistencia, desconectando todas sus entidades -
boolean contains(Object entity): comprueba si una entidad está gestionada en el contexto de persistencia -
Query createNamedQuery(String name): obtiene una consulta JPQL precompilada -
void detach(Object entity): elimina la entidad del contexto de persistencia, dejándola desconectada de la base de datos -
<T> T find(Class<T>, Object key): busca por clave primaria -
void flush(): sincroniza el contexto de persistencia con la base de datos -
<T> T getReference(Class<T>, Object key): obtiene una referencia a una entidad, que puede haber sido recuperada de forma lazy -
EntityTransaction getTransaction(): devuelve la transacción actual -
<T> T merge(T entity): incorpora una entidad al contexto de persistencia, haciéndola gestionada -
void persist(Object entity): hace una entidad persistente y gestionada -
void refresh(Object entity): refresca el estado de la entidad con los valores de la base de datos, sobreescribiendo los cambios que se hayan podido realizar en ella -
void remove(Object entity): elimina la entidad
Puedes consultar el API completo de estas clases en los siguientes enlaces:
2.1.3. Obtención del entity manager factory y de los entity manager
La forma de obtener un entity manager o un entity manager factory varía dependiendo de si estamos utilizando JPA desde una aplicación standalone (lo que se denomina JPA gestionado por la aplicación) o desde un servidor de aplicaciones Java EE (en lo que se denomina JPA gestionado por el contenedor). En el segundo caso se obtienen mediante inyección de dependencias, siendo el servidor el responsable de obtener el entity manager e inyectarlo en una variable que tiene una determinada anotación. En el caso de JPA gestionado por la aplicación, es el programador el que debe llamar de forma explícita a las instrucciones para obtener estos objetos.
Obtención del entity manager factory
En el primer caso, cuando estamos usando JPA gestionado por la aplicación, lo primero que debemos hacer es crear un EntityManagerFactory, para lo que hay que invocar al método createEntityManagerFactory() pasando por parámetro el nombre de la unidad de persistencia definida en el fichero persistence.xml. En este fichero, como ya hemos visto, se especifican los parámetros de configuración de la conexión con la base de datos (URL de la conexión, nombre de la base de datos, usuario, contraseña, gestor de base de datos, características del pool de conexiones, etc.). Por ejemplo:
EntityManagerFactory emf =
Persistence.createEntityManagerFactory("mensajes-mysql");Esta creación es un proceso costoso, ya que incluye el procesamiento de todas las anotaciones de las clases de entidad declaradas en el persistence.xml, la generación del esquema de datos asociados para compararlo con el existente en la base de datos con la que se realiza la conexión y bastantes otros procesos relacionados con el mapeo de las entidades con la base de datos.
Es conveniente llamar al método sólo una vez y guardar el entityManagerFactory resultante en una variable estática o en un singleton para reusar la misma factoría durante el tiempo de vida de la aplicación. Por ejemplo, el siguiente código define un singleton que inicializa el entityManagerFactory sólo una vez. Lo llamamos EmfSingleton y lo definimos en el paquete org.expertojava.jpa.mensajes.persistencia:
package org.expertojava.jpa.mensajes.persistencia
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public class EmfSingleton {
private static EmfSingleton ourInstance =
new EmfSingleton();
static private final String PERSISTENCE_UNIT_NAME = "mensajes-mysql"; (1)
private EntityManagerFactory emf = null;
public static EmfSingleton getInstance() {
return ourInstance;
}
private EmfSingleton() {
}
public EntityManagerFactory getEmf() {
if (this.emf == null)
this.emf = Persistence
.createEntityManagerFactory(PERSISTENCE_UNIT_NAME); (2)
return this.emf;
}
}| 1 | Constante con el nombre de la unidad de persistencia |
| 2 | Creación de la factoría. Sólo se hace una vez, la primera vez que se llama al método. |
Una vez definido el singleton anterior podemos acceder a la factoría con el siguiente código:
EntityManagerFactory emf = EmfSingleton.getInstance().getEmf()Obtención de los entityManager
Los entityManager se obtienen a partir del entityManagerFactory mediante el método createEntityManager():
EntityManager em = emf.createEntityManager();Lo normal es que no necesitemos trabajar con la factoría de y que llamemos directamente al objeto que nos devuelve el singleton:
EntityManager em = EmfSingleton.getInstance().getEmf().createEntityManager();Esta llamada no es nada costosa, ya que las implementaciones de JPA (como Hibernate) implementan pools de entity managers. El método createEntityManager no realiza ninguna reserva de memoria ni de otros recursos sino que simplemente devuelve alguno de los entity managers disponibles.
Repetimos a continuación un ejemplo típico de uso que ya hemos visto previamente:
public class EjemploUnidadDeTrabajoJPA {
public static void main(String[] args) {
EntityManagerFactory emf =
EmfSingleton.getInstance().getEmf();
EntityManager em = emf.createEntityManager();
// Abrimos una transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// El em realiza operaciones sobre las entidades
// Cerramos la transacción, el em
tx.commit();
em.close();
// Cerramos el emf cuando se termina la aplicación
emf.close();
}
}Es muy importante considerar que los objetos EntityManager no son thread-safe, no pueden ser compartidos por más de un thread. Cuando los utilicemos en servlets, por ejemplo, deberemos crearlos en cada petición HTTP. De esta forma se evita que distintas sesiones accedan al mismo contexto de persistencia.
2.1.4. Transacciones
Cualquier operación que conlleve una creación, modificación o borrado de entidades debe hacerse dentro de una transacción. En JPA las transacciones se gestionan de forma distinta dependiendo de si estamos en un entorno Java SE o en un entorno Java EE. La diferencia fundamental entre ambos casos es que en un entorno Java EE las transacciones se manejan con JTA (Java Transaction API), un API que implementa el two face commit y que permite gestionar operaciones sobre múltiples recursos transaccionales o múltiples operaciones transaccionales sobre el mismo recurso. En el caso de Java SE las transacciones se implementan con el gestor de transacciones propio del recurso local (la base de datos) y se especifican en la interfaz EntityTransaction.
El gestor de transacciones locales se obtiene con la llamada getTransaction() al EntityManager. Una vez obtenido, podemos pedirle cualquiera de los métodos definidos en la interfaz: begin() para comenzar la transacción, commit() para actualizar los cambios en la base de datos (en ese momento JPA vuelca las sentencias SQL en la base de datos) o rollback() para deshacer la transacción actual.
El siguiente listado muestra un ejemplo de uso de una transacción:
em.getTransaction().begin();
createEmpleado("Juan Garcia", 30000);
em.getTransaction().commit();2.2. Operaciones CRUD del entity manager
Vamos a ver con más detalle las operaciones básicas relacionadas con entidades que podemos hacer con un entity manager. Veremos las siguientes:
-
persist()para almacenar una entidad en la base de datos -
find()para buscar entidades por clave primaria -
actualización de entidades con los setters
-
remove()para borrar entidades
2.2.1. Persist para hacer persistente una entidad
El método persist() del EntityManager acepta una nueva instancia de entidad y la convierte en gestionada. Si la entidad que se pasa como parámetro ya está gestionada en el contexto de persistencia, la llamada se ignora. La operación contains() puede usarse para comprobar si una entidad está gestionada.
El hecho de convertir una entidad en gestionada no la hace persistir inmediatamente en la base de datos. La verdadera llamada a SQL para crear los datos relacionales no se generará hasta que el contexto de persistencia se sincronice con la base de datos. Lo más normal es que esto suceda cuando se realiza un commit de la transacción. En el momento en que la entidad se convierte en gestionada, los cambios que se realizan sobre ella afectan al contexto de persistencia. Y en el momento en que la transacción termina, el estado en el que se encuentra la entidad es volcado en la base de datos.
Si se llama a persist() fuera de una transacción la entidad se incluirá en el contexto de persistencia, pero no se realizará ninguna acción hasta que la transacción comience y el contexto de persistencia se sincronice con la base de datos.
La operación persist() se utiliza con entidades nuevas que no existen en la base de datos. Si se le pasa una instancia con un identificador que ya existe en la base de datos el proveedor de persistencia puede detectarlo y lanzar una excepción EntityExistsException. Si no lo hace, entonces se lanzará la excepción cuando se sincronice el conexto de persistencia con la base de datos, al encontrar una clave primaria duplicada.
Un ejemplo completo de utilización de persist(), en el que también se realiza una actualización de una relación a-muchos, es el siguiente:
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
// Añadimos un nuevo empleado al departamento 1
Departamento depto = em.find(Departamento.class, 1L);
Empleado empleado = new Empleado();
empleado.setNombre("Pedro");
empleado.setSueldo(38000.0);
empleado.setDepartamento(depto);
em.persist(empleado);
// Actualizamos la colección en memoria de empleados del departamento
depto.getEmpleados().add(empleado);
em.getTransaction().commit();
em.close();En el ejemplo comenzamos obteniendo una instancia que ya existe en la base de datos de la entidad Departamento. Se crea una nueva instancia de Empleado, proporcionando algún atributo. Después asignamos el empleado al departamento, llamando al método setDepartamento() del empleado y pasándole la instancia de Departamento que habíamos recuperado. Después realizamos la llamada al método persist() que convierte la entidad en gestionada. Cuando el contexto de persistencia se sincroniza con la base de datos, se añade el nuevo empleado en la tabla y se actualiza su id. En la columna departmento_id se guarda la clave ajena al departamento al que está asignado. Hay que hacer notar que sólo se actualiza la tabla de Empleado, que es la propietaria de la relación y la que contiene la clave ajena a Departamento.

Por último actualizamos en memoria el otro lado de la relación llamando al método add() de la colección. Esto no es necesario para actualizar la base de datos, sólo para actualizar la relación en memoria. Es importante tener siempre presente que JPA no actualiza las colecciones en memoria de las relaciones uno-a-muchos.
Una cuestión muy importante a tener en cuenta es que si el identificador del empleado es una clave primaria generada por la base de datos no estará disponible hasta que el contexto de persistencia realice la ejecución de los comandos SQL. Hay que tener cuidado y no realizar el add en la colección con el identificador a null. Con Hibernate no hay problema, porque realiza la actualización en la base de datos de inmediantamente y tenemos el id actualizado justo después de ejecutar el persist (si el flush() está puesto a AUTO). Pero tenemos que tener cuidado, y comprobar el comportamiento de cada proveedor de persistencia.
Si queremos asegurarnos de que el identificador se carga en la entidad podemos utilizar las siguientes sentencias:
em.persist(empleado);
em.flush(empleado);
em.refresh(empleado);La llamada a flush asegura que se ejecuta el insert en la BD y la llamada a refresh asegura que el identificador se carga en la instancia. Esto es válido para cualquier proveedor de persistencia.
2.2.2. Find para buscar entidades por clave primaria
Una vez que la entidad está en la base de datos, lo siguiente que podemos hacer es recuperarla de nuevo. Para ello basta con escribir una línea de código:
Empeado empleado = em.find(Empleado.class, 4L);Pasamos la clase de la entidad que estamos buscando (en el ejemplo estamos buscando una instancia de la clase Empleado) y el identificador o clave primaria que identifica la entidad. El entity manager buscará esa entidad en la base de datos y devolverá la instancia buscada. La entidad devuelta será una entidad gestionada que existirá en el contexto de persistencia actual asociado al entity manager.
En el caso en que no existiera ninguna entidad con ese identificador, se devolvería simplemente null.
La llamada a find puede devolver dos posibles excepciones de tiempo de ejecución, ambas de la clase PersistenceException: IllegalStateException si el entitiy manager ha sido previamente cerrado o IllegalArgumentException si el primer argumento no contiene una clase entidad o el segundo no es el tipo correcto de la clave primaria de la entidad.
Existe una versión especial de find() que sólo recupera una referencia (técnicamente, un proxy) a la entidad, sin obtener los datos de los campos de la base de datos. Se trata del método getReference(). Es últil cuando se quiere añadir un objeto con una clave primaria conocida a una relación. Ya que únicamente estamos creando una relación, no es necesario cargar todo el objeto de la base de datos. Sólo se necesita su clave primaria. Veamos la nueva versión del ejemplo anterior:
Departamento depto = em.getReference(Departamento.class, 1L);
Empleado empleado = new Empleado();
empleado.setNombre("Pedro");
empleado.setSueldo(38000.0);
empleado.setDepartamento(depto);
em.persist(empleado);Esta versión es más eficiente que la anterior porque no se realiza ningún SELECT en la base de datos para buscar la instancia del Departamento. Cuando se llama a getReference(), el proveedor devolverá un proxy al Departamento sin recuperarlo realmente de la base de datos. En tanto que sólo se acceda a la clave primaria, no se recuperará ningún dato. Y cuando se haga persistente el Empleado, se guardará en la clave ajena correspondiente el valor de la clave primaria del Departamento.
Un posible problema de este método es que, a diferencia de find() no devuelve null si la instancia no existe, ya que realmente no realiza la búsqueda en la base de datos. Únicamente se debe utilizar el método cuando estamos seguros de que la instancia existe en la base de datos. En caso contrario estaremos guardando en la variable dept una referencia (clave primaria) de una entidad que no existe, y cuando se haga persistente el empleado se generará una excepción porque el Empleado estará haciendo referencia a una entidad no existente.
En general, la mayoría de las veces llamaremos al método find() directamente. Las implementaciones de JPA hacen un buen trabajo con las cachés y si ya tenemos la entidad en el contexto de persistencia no se realiza la consulta a la base de datos.
Por ejemplo, el siguiente código sólo generaría un SELECT sobre la base de datos:
Departamento depto1 = em.find(Departamento.class, 1L);
Departamento depto2 = em.find(Departamento.class, 1L);
Departamento depto3 = em.find(Departamento.class, 1L);
Departamento depto4 = em.find(Departamento.class, 1L);La única sentencia SQL generada es:
Hibernate: select departamen0_.id as id1_0_0_, departamen0_.campus as campus2_0_0_,
departamen0_.edificio as edificio3_0_0_, departamen0_.nombre as nombre4_0_0_
from Departamento departamen0_ where departamen0_.id=?2.2.3. Actualización de entidades
Para actualizar una entidad, primero debemos obtenerla para convertirla en gestionada. Después podremos colocar los nuevos valores en sus atributos utilizando los métodos set de la entidad. Por ejemplo, supongamos que queremos subir el sueldo del empleado 146 en 1.000 euros. Tendríamos que hacer lo siguiente:
em.getTransaction().begin();
Empleado empleado = em.find(Empleado.class, 2L);
double sueldo = empleado.getSueldo();
empleado.setSueldo(sueldo + 1000.0);
em.getTransaction().commit();
em.close();Nótese la diferencia con las operaciones anteriores, en las que el EntityManager era el responsable de realizar la operación directamente. Aquí no llamamos al EntityManager sino a la propia entidad. Estamos, por así decirlo, trabajando con una caché de los datos de la base de datos. Posteriormente, cuando se finalice la transacción, el EntityManager hará persistentes los cambios mediante las correspondientes sentencias SQL.
La otra forma de actualizar una entidad es con el método merge() del EntityManager. A este método se le pasa como parámetro una entidad no gestionada. El EntityManager busca la entidad en su contexto de persistencia (utilizando su identificador) y actualiza los valores del contexto de persistencia con los de la entidad no gestionada. En el caso en que la entidad no existiera en el contexto de persistencia, se crea con los valores que lleva la entidad no gestionada.
EntityManager em = emf.createEntityManager();
Empleado empleado = em.find(Empleado.class, 2L);
em.close();
empleado.setNombre("Pepito Pérez");
em = emf.createEntityManager();
em.getTransaction().begin();
empleado = em.merge(empleado);
empleado.setSueldo(20000.0);
em.getTransaction().commit();
em.close();Es muy importante notar que no está permitido modificar la clave primaria de una entidad gestionada. Si intentamos hacerlo, en el momento de hacer un commit la transacción lanzará una excepción RollbackException. Para reforzar esta idea, es conveniente definir las entidades sin un método set de la clave primaria. En el caso de aquellas entidades con una generación automática de la clave primaria, ésta se generará en tiempo de creación de la entidad. Y en el caso en que la aplicación tenga que proporcionar la clave primaria, lo puede hacer en el constructor.
2.2.4. Remove para borrar entidades
Un borrado de una entidad realiza una sentencia DELETE en la base de datos. Esta acción no es demasiado frecuente, ya que las aplicaciones de gestión normalmente conservan todos los datos obtenidos y marcan como no activos aquellos que quieren dejar fuera de vista de los casos de uso. Se suele utilizar para eliminar datos que se han introducido por error en la base de datos o para trasladar de una tabla a otra los datos (se borra el dato de una y se inserta en la otra). En el caso de entidades esto último sería equivalente a un cambio de tipo de una entidad.
Para eliminar una entidad, la entidad debe estar gestionada, esto es, debe existir en el contexto de persistencia. Esto significa que la aplicación debe obtener la entidad antes de eliminarla. Un ejemplo sencillo es:
Empleado empleado = em.find(Empleado.class, 1L);
em.remove(emp);La llamada a remove asume que el empleado existe. En el caso de no existir se lanzaría una excepción.
Borrar una entidad no es una tarea compleja, pero puede requerir algunos pasos, dependiendo del número de relaciones en la entidad que vamos a borrar. En su forma más simple, el borrado de una entidad se realiza pasando la entidad como parámetro del método remove() del entity manager que la gestiona. En el momento en que el contexto de persistencia se sincroniza con una transacción y se realiza un commit, la entidad se borra. Hay que tener cuidado, sin embargo, con las relaciones en las que participa la entidad para no comprometer la integridad de la base de datos.
Veamos un sencillo ejemplo. Consideremos las entidades Empleado y Despacho y supongamos una relación unidireccional uno-a-uno entre Empleado y Despacho que se mapea utilizando una clave ajena en la tabla EMPLEADO hacia la tabla DESPACHO (lo veremos en la sesión siguiente). Supongamos el siguiente código dentro de una transacción en el que borramos el despacho de un empleado:
Empleado emp = em.find(Empleado.class, 1L);
Despacho desp = emp.getDespacho();
em.remove(desp);Cuando se realice un commit de la transacción veremos una sentencia DELETE en la tabla DESPACHO, pero en ese momento obtendremos una excepción con un error de la base de datos referido a que hemos violado una restricción de la clave ajena. Esto se debe a que existe una restricción de integridad referencial entre la tabla EMPLEADO y la tabla DESPACHO. Se ha borrado una fila de la tabla DESPACHO pero la clave ajena correspondiente en la tabla EMPLEADO no se ha puesto a NULL. Para corregir el problema, debemos poner explícitamente a null el atributo despacho de la entidad Empleado antes de que la transacción finalice:
Empleado empleado = em.find(Empleado.class, 3L);
Despacho desp = empleado.getDespacho();
empleado.setDespacho(null); (1)
em.remove(desp);| 1 | Eliminamos la clave ajena hacia el despacho poniendo un null en el atributo. |
El mantenimiento de las relaciones es una responsabilidad de la aplicación. Casi todos los problemas que suceden en los borrados de entidades tienen relación con este aspecto. Si la entidad que se va a borrar es el objetivo de una clave ajena en otras tablas, entonces debemos limpiar esas claves ajenas antes de borrar la entidad.
2.3. Operaciones en cascada
Por defecto, las operaciones del entity manager se aplican únicamente a las entidades proporcionadas como argumento. La operación no se propagará a otras entidades que tienen relación con la entidad que se está modificando. Lo hemos visto antes con la llamada a remove(). Pero no sucede lo mismo con operaciones como persist(). Es bastante probable que si tenemos una entidad nueva y tiene una relación con otra entidad, las dos deben persistir juntas.
Consideremos la secuencia de operaciones del siguiente códgo que muestran cómo se crea un nuevo Empleado con una entidad Direccion asociada y cómo se hacen los dos persistentes. La segunda llamada a persist() sobre la Direccion es algo redundante. Una entidad Direccion se acopla a la entidad Empleado que la almacena y tiene sentido que siempre que se cree un nuevo Empleado, se propague en cascada la llamada a persist() para la Direccion.
Empleado emp = new Empleado(12, "Rob");
Direccion dir = new Direccion("Alicante");
emp.setDireccion(dir);
em.persist(emp);
em.persist(dir);El API JPA proporciona un mecanismo para definir cuándo operaciones como persist() deben propagarse en cascada. Para ello se define el elemento cascade en todas las anotaciones de relaciones (@OneToOne, @OneToMany, @ManyToOne y @ManyToMany).
Las operaciones a las que hay que aplicar la propagación se identifican utilizando el tipo enumerado CasacadeType, que puede tener como valor PERSIST, REFRESH, REMOVE, MERGE y ALL.
2.3.1. Persist en cascada
Para activar la propagación de la persistencia en cascada debemos añadir el elemento cascade=CascadeType.PERSIST en la declaración de la relación. Por ejemplo, en el caso anterior, si hemos definido una relación muchos-a-uno entre Empleado y Direccion, podemos escribir el siguiente código:
@Entity
public class Empleado {
...
@ManyToOne(cascadeCascdeType.PERSIST)
Direccion direccion;
...
}Para invocar la persistencia en cascada sólo nos tenemos que asegurar de que la nueva entidad Direccion se ha puesto en el atributo direccion del Empleado antes de llamar a persist() con él. La definición de la operación en cascada es unidireccional, y tenemos que tener en cuenta quién es el propietario de la relación y dónde se va a actualizar la misma antes de tomar la decisión de poner el elemento en ambos lados. Por ejemplo, en el caso anterior cuando definamos un nuevo empleado y una nueva dirección pondremos la dirección en el empleado, por lo que el elemento cascade tendremos que definirlo únicamente en la relación anterior.
| Aunque JPA define esta forma de crear y hacer persistentes en cascada las entidades, no es una característica demasiado utilizada. La mayoría de las ocasiones tendremos ya las entidades hechas persistentes por una llamada previa al método persist. |
2.3.2. Borrado en cascada
A primera vista, la utilización de un borrado en cascada puede parecer atractiva. Dependiendo de la cardinalidad de la relación podría eliminar la necesidad de eliminar múltiples instancias de entidad. Sin embargo, aunque es un elemento muy interesante, debe utilizarse con cierto cuidado. Hay sólo dos situaciones en las que un remove() en cascada se puede usar sin problemas: relaciones uno-a-uno y uno-a-muchos en donde hay una clara relación de propiedad y la eliminación de la instancia propietaria debe causar la eliminación de sus instancias dependientes. No puede aplicarse ciegamente a todas las relaciones uno-a-uno o uno-a-muchos porque las entidades dependientes podrían también estar participando en otras relaciones o podrían tener que continuar en la base de datos como entidades aisladas.
Habiendo realizado el aviso, veamos qué sucede cuando se realiza una operación de remove() en cascada. Si una entidad Empleado se elimina, no tiene sentido eliminar el despacho (seguirá existiendo) pero sí sus cuentas de correo (suponiendo que le corresponde más de una). El siguiente código muestra cómo definimos este comportamiento:
@Entity
public class Empleado {
...
@OneToOne(cascade={CascadeType.PERSIST})
Despacho despacho;
@OneToMany(mappedBy="empleado",
cascade={CascadeType.PERSIST, CascadeType.REMOVE})
Collection<CuentaCorreo> cuentasCorreo;
...
}Cuando se llama al método remove() el entity manager navegará por las relaciones entre el empleado y sus cuentas de correo e irá eliminando todas las instancias asociadas al empleado.
Hay que hacer notar que este borrado en cascada afecta sólo a la base de datos y que no tiene ningún efecto en las relaciones en memoria entre las instancias en el contexto de persistencia. Cuando la instancia de Empleado se desconecte de la base de datos, su colección de cuentas de correo contendrá las mismas instancias de CuentaCorreo que tenía antes de llamar a la operación remove(). Incluso la misma instancia de Empleado seguirá existiendo, pero desconectada del contexto de persistencia.
2.4. Queries
Uno de los aspectos fundamentales de JPA es la posibilidad de realizar consultas sobre las entidades, muy similares a las consultas SQL. El lenguaje en el que se realizan las consultas se denomina Java Persistence Query Language (JPQL). Desde la versión 2.0 de JPA es posible también utilizar el API Criteria que permite la detección de errores de sintaxis en la construcción de las consultas. Lo veremos más adelante.
Una consulta se implementa mediante un objeto Query. Los objetos Query se construyen utilizando el EntityManager como una factoría. La interfaz EntityManager proporciona un conjunto de métodos que devuelven un objeto Query nuevo. Veremos algún ejemplo ahora, pero profundizaremos en el tema más adelante.
Una consulta puede ser estática o dinámica. Las consultas estáticas se definen con metadatos en forma de anotaciones o XML, y deben incluir la consulta propiamente dicha y un nombre asignado por el usuario. Este tipo de consulta se denomina una consulta con nombre (named query en inglés). El nombre se utiliza en tiempo de ejecución para recuperar la consulta.
Una consulta dinámica puede lanzarse en tiempo de ejecución y no es necesario darle un nombre, sino especificar únicamente las condiciones. Son un poco más costosas de ejecutar, porque el proveedor de persistencia (el gestor de base de datos) no puede realizar ninguna preparación, pero son muy útiles y versátiles porque pueden construirse en función de la lógica del programa, o incluso de los datos proporcionados por el usuario.
El siguiente código muestra un ejemplo de consulta dinámica:
Query query = em.createQuery("SELECT e FROM Empleado e " +
"WHERE e.sueldo > :sueldo");
query.setParameter("sueldo", 20000);
List emps = query.getResultList();En el ejemplo vemos que, al igual que en JDBC, es posible especificar consultas con parámetros y posteriormente especificar esos parámetros con el método setParameter(). Una vez definida la consulta, el método getResultList() devuelve la lista de entidades que cumplen la condición. Este método devuelve un objeto que implementa la interfaz List, una subinterfaz de Collection que soporta ordenación. Hay que notar que no se devuelve una List<Empleado> ya que no se pasa ninguna clase en la llamada y no es posible parametrizar el tipo devuelto. Sí que podemos hacer un casting en los valores devueltos por los métodos que implementan las búsquedas, como muestra el siguiente código:
public List<Empleado> findEmpleadosSueldo(long sueldo) {
Query query = em.createQuery("SELECT e FROM Empleado e " +
"WHERE e.sueldo > :sueldo");
query.setParameter("sueldo", 20000);
return (List<Empleado>) query.getResultList();
}2.5. Operaciones sobre el contexto de persistencia
Una cuestión muy importante para entender el funcionamiento del entity manager es comprender el funcionamiento de las operaciones que gestionan el contexto de persistencia. Hemos dicho que el contexto de persistencia es la colección de entidades gestionadas por el entity manager, entidades que están conectadas y sincronizadas con la base de datos. Cuando el entity manager cierra una transacción, genera las sentencias SQL necesarias para que el estado de estas entidades se vuelque a la base de datos. Es fundamental entender que el contexto de persistencia hace el papel de caché de las entidades que están en la base de datos. Cuando actualizamos una instancia en el contexto de persistencia estamos actualizando una caché, una copia que sólo se hace persistente en la base de datos cuando el entity manager realiza un flush de las instancias en la base de datos.
Simplificando bastante, el entity manager realiza el siguiente proceso para todas las entidades:
-
Si la aplicación solicita una entidad (mediante un
find, o accediendo a un atributo de otra entidad en una relación), se comprueba si ya se encuentra en el contexto de persistencia. Si es así, se devuelve su referencia. Si no se ha recuperado previamente, se obtiene la instancia de la entidad de la base de datos. -
La aplicación utiliza las entidades del contexto de persistencia, accediendo a sus atributos y (posiblemente) modificándolos. Todas las modificaciones se realizan en la memoria, en el contexto de persistencia.
-
En un momento dado (cuando termina la transacción, se ejecuta una query o se hace una llamada al método
flush) el entity manager comprueba qué entidades han sido modificadas y vuelca los cambios a la base de datos.
Es muy importante darse cuenta de la diferencia entre el contexto de persistencia y la base de datos propiamente dicha. La sincronización no se realiza hasta que el entity manager vuelca los cambios a la base de datos. La aplicación debe ser consciente de esto y utilizar razonablemente los contextos de persistencia.
Vamos a ver con algún detalle las operaciones del entity manager relacionadas con el contexto de persistencia:
-
flush()sincroniza el contexto de persistencia con la base de datos -
detach()desconecta una entidad del contexto de persistencia -
merge()mezcla una entidad desconectada en el contexto de persistencia actual -
refresh()refresca el estado de una entidad con los valores de la base de datos, sobreescribiendo sus cambios en memoria -
clear()yclose()vacían el contexto de persistencia y lo desconectan de la base de datos
2.5.1. Sincronización con la base de datos con flush
Cada vez que el proveedor de persistencia genera sentencias SQL y las escribe en la base de datos a través de una conexión JDBC, decimos que se ha volcado (flush) el contexto de persistencia. Todos los cambios pendientes que requieren que se ejecute una sentencia SQL en la transacción se escriben en la base de datos cuando ésta realiza un commit. Esto significa que cualquier operación SQL que tenga lugar después de haberse realizado el volcado ya incorporará estos cambios. Esto es particularmente importante para consultas SQL que se ejecutan en una transacción que también está realizando cambios en los datos de la entidad.
¿Qué sucede exactamente cuando se realiza un volcado del contexto de persistencia? Un volcado consiste básicamente en tres componentes: entidades nuevas que necesitan hacerse persistentes, entidades modificadas que necesitan ser actualizadas y entidades borradas que deben ser eliminadas de la base de datos. Toda esta información es gestionada por el contexto de persistencia.
Cuando ocurre un volcado, el entity manager itera primero sobre las entidades gestionadas y busca nuevas entidades que se han añadido a las relaciones y que tienen activada la opción de persistencia en cascada. Esto es equivalente lógicamente a invocar a persist() con cada una de las entidades gestionadas antes de que se realice el volcado. El entity manager también comprueba la integridad de todas las relaciones. Si una entidad apunta a otra que no está gestionada o que ha sido eliminada, entonces se puede lanzar una excepción.
Si en el proceso de volcado alguno de los objetos a los que apunta la instancia que estamos haciendo persistente no está gestionado, no tiene el atributo de persistencia en cascada y no está incluido en una relación uno-a-uno o muchos-a-uno entonces se lanzará una excepción IllegalStateException.
2.5.2. Desconexión de entidades
Como resultado de una consulta o de una relación, obtendremos una colección de entidades que deberemos tratar, pasar a otras capas de la aplicación y, en una aplicación web, mostrar en una página JSP o JSF. En este apartado vamos a ver cómo trabajar con las entidades obtenidas y vamos a reflexionar sobre su desconexión del contexto de persistencia.
Una entidad desconectada (detached entity en inglés) es una entidad que ya no está asociada a un contexto de persistencia. En algún momento estuvo gestionada, pero el contexto de persistencia puede haber terminado, o la entidad puede haberse transformado de forma que ha perdido su asociación con el contexto de persistencia que la gestionaba. Cualquier cambio que se realice en el estado de la entidad no se hará persistente en la base de datos, pero todo el estado que estaba en la entidad antes de desconectarse sigue estando ahí para ser usado por la aplicación.
Hay dos formas de ver la desconexión de entidades. Por una parte, es una herramienta poderosa que puede utilizarse por las aplicaciones para trabajar con aplicaciones remotas o para soportar el acceso a los datos de la entidad mucho después de que la transacción ha concluido. Además, son objetos que pueden hacer el papel de DTOs (Data Transfer Objets) y ser devueltos por la capa de lógica de negocio y utilizados por la capa de presentación. La otra posible interpretación es que puede ser una fuente de problemas frustrantes cuando las entidades contienen una gran cantidad de atributos que se cargan de forma perezosa y los clientes que usan estas entidades desconectadas necesitan acceder a esta información.
Existen muchas condiciones en las que una entidad se convierte en desconectada. Cada una de las situaciones siguientes generarán entidades desconectadas:
-
Cuando el contexto de persistencia se cierra con una llamada a
close()del entity manager -
Cuando se llama al método
clear()del entity manager -
Cuando se produce un rollback de la transacción
-
Cuando una entidad se serializa
Todos los casos se refieren a contextos de persistencias gestionados por la aplicación (Java SE y aplicaciones web sin contenedor de EJB).
Recuperación LAZY y EAGER de las entidades relacionadas
Una característica que hace muy cómoda la programación con JPA es la recuperación de todo el grafo de relaciones asociado a una entidad. Cuando el entity manager trae a memoria entidades (como resultado de una consulta o de una llamada a find) también trae todas aquellas entidades relacionadas. De esta forma podemos acceder a las entidades relacionadas a través de llamadas a los getters. Sin embargo, no todas las entidades relacionadas se traen realmente a memoria. En muchos casos, por motivos de eficiencia, lo que JPA guarda en el getter no es la propia entidad sino un proxy que generará una consulta a la base de datos cuando se acceda a él. Es lo que se denomina carga perezosa (lazy loading).
Podemos definir el tipo de carga que queremos marcando las relaciones con los atributos EAGER o LAZY. Por defecto las relaciones a-uno son de tipo eager y las a-muchos de tipo lazy.
Es fundamental saber si un atributo se ha traído a memoria o si está cargado de forma perezosa cuando se realiza una desconexión del contexto de persistencia, por ejemplo cuando se cierra el entity manager. Veamos un ejemplo. Supongamos que tenemos la siguiente definición de Empleado:
public class Empleado {
@Id
@GeneratedValue
private Long id;
...
@OneToMany(mappedBy = "empleado", fetch = FetchType.EAGER)
private Set<CuentaCorreo> correos;
...
}Todos los elementos de la relación correos se cargarán en memoria al recupar un empleado, aunque no accedamos a ellos. De esta forma, si el entity manager se cierra, tendremos acceso a la colección:
// Cargamos una entidad y cerramos la conexión
// del entity manager
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
Empleado empleado = em.find(Empleado.class, 1L);
em.getTransaction().commit();
em.close();
// Comprobamos que los correos se han cargado en memoria
// por ser el tipo Eager Fetch
assertTrue(empleado.getCorreos().size()==2);El comportamento del acceso a atributos no cargados cuando la entidad está desconectada no está definido en la especificación. Algunas implemenentaciones pueden intentar resolver la relación, mientras que otros simplemente lanzan una excepción y dejan el atributo sin inicializar. En el caso de Hibernate, se lanza una excepción de tipo org.hibernate.LazyInitializationException. Si la entidad ha sido desconectada debido a una serialización entonces no hay virtualmente ninguna esperanza de resolver la relación. La única forma portable de gestionar estos casos es no utilizando estos atributos.
En el caso en el que las entidades no tengan atributos de carga perezosa, no debe haber demasiados problemas con la desconexión. Todo el estado de la entidad estará todavía disponible para su uso en la entidad.
Si las relaciones a-muchos no tienen un número demasiado elevado de elementos es recomendable definirlas de tipo EAGER.
2.5.3. Merge
El método merge() permite volver a incorporar en el contexto de persistencia del entity manager una entidad que había sido desconectada. Debemos pasar como parámetro la entidad que queremos incluir. Hay que tener cuidado con su utilización, porque el objeto que se pasa como parámetro no pasa a ser gestionado. Hay que usar el objeto que devuelve el método. Un ejemplo:
public void subeSueldo(Empleado emp, long inc)
Empleado empGestionado = em.merge(emp);
empGestionado.setSueldo(empGestionado.getSueldo()+inc);
}Si una entidad con el mismo identificador que emp existe en el contexto de persistencia, se devuelve como resultado y se actualizan sus atributos. Si el objeto que se le pasa a merge() es un objeto nuevo, se comporta igual que persist(), con la única diferencia de que la entidad gestionada es la devuelta como resultado de la llamada.
Clear
En ocasiones puede ser necesario limpiar (clear) contexto de persistencia y vaciar las entidades gestiondas. Esto puede suceder, por ejemplo, en conextos extendidos gestionados por la aplicación que han crecido demasiado. Por ejemplo, consideremos el caso de un entity manager gestionado por la aplicación que lanza una consulta que devuelve varios cientos de instancias entidad. Una vez que ya hemos realizado los cambios a unas cuantas de esas instancias y la transacción se termina, se quedan en memoria cientos de objetos que no tenemos intención de cambiar más. Si no queremos cerrar el contexto de persistencia en ese momento, entonces tendremos que limpiar de alguna forma las instancias gestionadas, o el contexto de persistencia irá creciendo cada vez más.
El método clear() del interfaz EntityManager se utiliza para limpiar el contexto de persistencia. En muchos sentidos su funcionamiento es similar a un rollback de una transacción en memoria. Todas las instancias gestionadas por el contexto e persistencia se desconectan del contexto y quedan con el estado previo a la llamada a clear(). La operación clear() es del tipo todo o nada. No es posible cancelar selectivamente la gestión de una instancia particular cuando el contexto de persistencia está abierto.
2.5.4. Actualización de las colecciones en las relaciones a-muchos
En una relación uno-a-muchos el campo que mantiene la colección es un proxy que nos permite acceder a los elementos propiamente dichos, pero sólo si la entidad está gestionada. Hay que tener cuidado porque si la parte inversa de la relación se actualiza con un nuevo elemento, JPA no tiene forma de saberlo por si solo. La aplicación debe actualizar la colección también.
Veamos un ejemplo. Supongamos que tenemos la relación uno-a-muchos entre AutorEntity y MensajeEntity definida en la sesión anterior, que la entidad MensajeEntity contiene la clave ajena hacia AutorEntity y que la aplicación ejecuta el siguiente código para añadir un mensaje a un autor:
em.getTransaction().begin();
AutorEntity autor = em.find(AutorEntity.class, 1L);
System.out.println(autor.getNombre() + " ha escrito " +
autor.getMensajes().size() + " mensajes");
Mensaje mens = new Mensaje("Nuevo mensaje");
mens.setAutor(autor);
em.persist(mens);
em.getTransaction().commit();
System.out.println(autor.getNombre() + " ha escrito " +
autor.getMensajes().size() + " mensajes");Si comprobamos qué sucede veremos que no aparecerá ningún cambio entre el primer mensaje de la aplicación y el segundo, ambos mostrarán el mismo número de mensajes. ¿Por qué? ¿Es que no se ha actualizado el nuevo mensaje del autor en la base de datos?. Si miramos en la base de datos, comprobamos que la transacción sí que se ha completado correctamente. Sin embargo cuando llamamos al método getMensajes() en la colección resultante no aparece el nuevo mensaje que acabamos de añadir.
Este es un ejemplo del tipo de errores que podemos cometer por trabajar con contextos de persistencia pensando que estamos conectados directamente con la BD. El problema se encuentra en que la primera llamada a getMensajes() (antes de crear el nuevo mensaje) ha generado la consulta a la base de datos y ha cargado el resultado en memoria. Cuando hacemos una segunda llamada, el proveedor detecta que esa información ya la tiene en la caché y no la vuelve a consultar.
La aplicación es la responsable de actualizar las relaciones en memoria. Por eso hay que añadir manualmente el mensaje a la colección. Hay que hacerlo una vez que se ha hecho persistente el mensaje, para que su identicador autogenerado esté actualizado. Lo haríamos añadiendo al código anterior la línea que actualiza la colección:
em.getTransaction().begin();
Autor autor = em.find(Autor.class, 1L);
System.out.println(autor.getNombre() + " ha escrito " +
autor.getMensajes().size() + " mensajes");
Mensaje mens = new Mensaje("Nuevo mensaje");
mens.setAutor(autor);
em.persist(mens);
em.getTransaction().commit();
autor.getMensajes().add(mens); (1)
System.out.println(autor.getNombre() + " ha escrito " +
autor.getMensajes().size() + " mensajes");| 1 | La llamada al método add() de la colección añade un mensaje nuevo a la colección de mensajes del autor existente en el contexto de persistencia. De esta forma estamos reflejando en memoria lo que hemos realizado en la base de datos. |
Otra posible solución (menos recomendable) es obligar al entity manager a que sincronice la entidad y la base de datos. Para ello podemos llamar al método refresh() del entity manager:
em.getTransaction().begin();
// ... añado un mensaje al autor
em.refresh(autor); (1)
em.getTransaction().commit();
System.out.println(autor.getNombre() + " ha escrito " +
autor.getMensajes().size() +
" mensajes");| 1 | La llamada al método refresh obliga a JPA a volver a hacer un SELECT la siguiente vez que se pida la colección autor.getMensajes(). |
Estos ejemplos ponen en evidencia que para trabajar bien con JPA es fundamental entender que el contexto de persistencia es una caché de la base de datos propiamente dicha.
2.6. Implementación de un DAO con JPA
El patrón DAO (Data Access Object) se ha utilizado históricamente para ocultar los detalles de implementación de la capa de persistencia y ofrecer una interfaz más sencilla a otras partes de la aplicación. Esto es necesario cuando se trabaja con un API de persistencia de bajo nivel, como JDBC, en la que las operaciones sobre la base de datos conlleva la utilización de sentencias SQL que queremos aislar de otras capas de la aplicación.
Sin embargo, en desarrollos en los que utilizamos un API de persistencia de mayor nivel como JPA, la utilización de un patrón DAO no es tan necesaria. Muchos argumentan incluso que se trata de un antipatrón, un patrón que conviene evitar. No creemos que sea así, porque un patrón DAO bien diseñado y adaptado a JPA permite eliminar errores derivados de la mala utilización del contexto de persistencia y agrupar en una única clase todas las consultas relacionadas con una misma clase de dominio.
Presentamos a continuación una adaptación del patrón DAO propuesto por Adam Bien, uno de los autores y expertos sobre Java EE más importantes en la actualidad.
Cada clase de entidad definirá una clase DAO en la que se definen los métodos CRUD sobre la entidad (Create, Read, Update y Delete), así como el find que devuelve la entidad a partir de su clave primaria. También definirán las consultas JPQL.
Por ejemplo, el DAO de la clase Autor definiría los siguientes métodos:
-
create (Autor autor): recibe una variableautorno gestionada y devuelve una variable gestionada con la clave primaria actualizada -
update (Autor autor): recibe una variableautorque puede no estar gestionada (pero ya está en la base de datos) y actualiza el valor de la base de datos con los valores de la variable -
delete (Autor autor): borra la entidadautorde la base de datos -
find (Long id): devuelve una entidad gestionada correspondiente a la clave primaria que se pasa como parámetro.
Todos estos métodos se deben implementar a través de un entity manager que habremos creado al comienzo del trabajo con los DAOs y le habremos pasado a los DAO en su creación. O sea que los DAO trabajarán con un entity manager y una transacción abierta, de forma que podremos englobar distintas operaciones de distintos DAOs en una misma transacción y un mismo contexto de persistencia.
La capa responsable de abrir la transacción y el entity manager será la capa que utiliza los DAO, la que implementa la lógica de negocio. Si se intenta llamar a cualquiera de los métodos del DAO sin que se haya abierto una transacción en el entity manager se deberá lanzar una excepción.
Vamos a definir todas las clases DAO en el paquete persistencia y las clases que usan los DAO para implementar la lógica de negocio en el paquete service.
La implementación concreta se especifica a continuación. Agrupamos todas las funciones CRUD comunes a todos los DAO en una clase abstracta genérica, que tiene como parámetro la entidad que va a gestionar y el tipo de su clave primaria de la entidad. En las aplicaciones JPA que utilicen este patrón se definirá una clase DAO específica por cada entidad que definamos.
Clase DAO genérica:
package org.expertojava.jpa.empleados.persistencia;
import javax.persistence.EntityManager;
abstract class Dao<T, K> { (1)
EntityManager em; (2)
public Dao(EntityManager em) { (3)
this.em = em;
}
public EntityManager getEntityManager() {
return this.em;
}
public T create(T t) { (4)
em.persist(t);
em.flush();
em.refresh(t);
return t;
}
public T update(T t) { (5)
return (T) em.merge(t);
}
public void delete(T t) { (6)
t = em.merge(t);
em.remove(t);
}
public abstract T find(K id); (7)
}| 1 | Definición de la clase abstracta genérica. Las clases T y K se corresponden con la clase de la entidad y la clase de la clave primaria. |
| 2 | Variable de instancia con el entity manager en el que vamos a utilizar el DAO |
| 3 | Creación del DAO en el que se le pasa el entity manager en el se van a realizar todas las operaciones |
| 4 | create: se recibe un objeto entidad creado con los datos a hacer persistente y se llama a persist(), flush() y refresh() para hacer persistente la entidad y actualizar su clave primaria. Se devuelve la entidad gestionada. |
| 5 | update: de realiza un merge de la entidad y se devuelve la entidad resultante, ya gestionada |
| 6 | delete: se hace un merge (la entidad que se pasa puede estar desconectada) y se hace un remove |
| 7 | find: se define como un método abstracto que se implementará en los DAOs concretos que extiendan esta clase abstracta genérica. Se define el perfil de la función: se devuelve la entidad con la clave primaria que buscamos o null si no la encuentra. |
Para cada clase entidad definiremos una clase DAO que extiende la clase anterior genérica. En esta clase DAO concreta se implementan también todas las consultas relacionadas con la entidad. Por ejemplo, a continuación vemos el ejemplo concreto de DAO EmpleadoDao:
package org.expertojava.jpa.empleados.persistencia;
import org.expertojava.jpa.empleados.modelo.Empleado;
import org.expertojava.jpa.empleados.modelo.Proyecto;
import javax.persistence.EntityManager;
import javax.persistence.Query;
import java.util.List;
public class EmpleadoDao extends Dao<Empleado, Long> {
String FIND_ALL_EMPLEADOS = "SELECT e FROM Empleado e ";
public EmpleadoDao(EntityManager em) {
super(em);
}
@Override
public Empleado find(Long id) {
EntityManager em = this.getEntityManager();
return em.find(Empleado.class, id);
}
public List<Empleado> listAllEmpleados() {
EntityManager em = this.getEntityManager();
Query query = em.createQuery(FIND_ALL_EMPLEADOS);
return (List<Empleado>) query.getResultList();
}
}Los DAO proporcionan métodos de un grano muy fino, un CRUD básico sobre las entidades de cada clase. Trabajan con entidades gestionadas por un mismo entorno de persistencia y en el código llamador hay que gestionar la transacción y el entity manager.
Es habitual definir clases de más nivel que contienen las operaciones de negocio en un paquete servicio. Las operaciones de negocio se definen como métodos de estas clases en los que se encapsulan las llamadas a los DAOs y todo el trabajo de las entidades gestionadas. Los métodos reciben identificadores y datos planos y devuelven objetos entidad desconectados de la base de datos
Por ejemplo, podemos definir la clase EmpleadoServicio con los métodos de negocio:
-
findPorId(Long idEmpleado): devuelve un empleadl -
intercambiaDespachos(Long idEmpleado1, Long idEmpleado2): intercambia los despachos de dos empleados
import org.expertojava.jpa.empleados.modelo.Despacho;
import org.expertojava.jpa.empleados.modelo.Empleado;
import org.expertojava.jpa.empleados.persistencia.EmpleadoDao;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
public class EmpleadoServicio {
private EntityManagerFactory emf;
public void setEmf(EntityManagerFactory emf) {
this.emf = emf;
}
public Empleado findPorId(Long idEmpleado) {
EntityManager em = emf.createEntityManager();
Empleado empleado = null;
EmpleadoDao empleadoDao = new EmpleadoDao(em);
try {
em.getTransaction().begin();
empleado = empleadoDao.find(idEmpleado);
em.getTransaction().commit();
} catch (Exception e){
e.printStackTrace();
} finally {
em.close();
}
return empleado;
}
public void intercambiaDespachos(Long idEmpleado1, Long idEmpleado2) {
EntityManager em = emf.createEntityManager();
EmpleadoDao empleadoDao = new EmpleadoDao(em);
try {
em.getTransaction().begin();
Empleado emp1 = empleadoDao.find(idEmpleado1);
Empleado emp2 = empleadoDao.find(idEmpleado2);
Despacho despachoAux = emp1.getDespacho();
emp1.setDespacho(emp2.getDespacho());
emp2.setDespacho(despachoAux);
empleadoDao.update(emp1);
empleadoDao.update(emp2);
em.getTransaction().commit();
} catch (Exception e){
e.printStackTrace();
} finally {
em.close();
}
}
}Todos los métodos de lógica de negocio son utilizados desde otras capas de la aplicación. Por ejemplo, la capa de servicio. A diferencia de los métodos de los DAO, que toman y devuelven entidades gestionadas, los métodos de negocio toman y devuelven objetos planos, desconectados de cualquier transacción o gestor de persistencia. Son métodos atómicos. Cuando terminan podemos estar seguros de que se ha realizado la operación. En el caso en que haya algún problema, la operación no se realizará en absoluto (el estado de los objetos quedará como estaba antes de llamar a la operación) y se lanzará una excepción runtime.
Todos los métodos de negocio tienen la misma estructura:
-
Se obtiene un entity manager y se abre la transacción si se va a hacer algún cambio en las entidades. No es necesario abrir una transacción cuando se va a hacer sólo una consulta.
-
Se obtienen los DAO de las entidades que intervienen en la operación.
-
Se realizan las consultas y modificaciones de las entidades que participan en la operación, actualizando su estado en la base de datos mediante los DAO.
-
Se realiza el commit de la transacción y se cierra el entity manager.
Presentamos a continuación un ejemplo de test en el que se prueba el método de intercambiar los despachos:
@Test
public void testServicioActualizaDespacho() {
EmpleadoServicio empleadoServicio = new EmpleadoServicio();
empleadoServicio.setEmf(emf);
Empleado emp1 = empleadoServicio.findPorId(1L);
Empleado emp2 = empleadoServicio.findPorId(2L);
Despacho desp1 = emp1.getDespacho();
Despacho desp2 = emp2.getDespacho();
empleadoServicio.intercambiaDespachos(1L,2L);
emp1 = empleadoServicio.findPorId(1L);
emp2 = empleadoServicio.findPorId(2L);
assertTrue(emp1.getDespacho().equals(desp2));
assertTrue(emp2.getDespacho().equals(desp1));
}2.7. Ejercicios
2.7.1. (0,5 puntos) Contexto de persistencia
En el módulo mensajes escribe nuevos tests que comprueben errores generados por manejar incorrectamente el contexto de persistencia:
-
Comprobación de que se lanza una excepción al intenta acceder a un atributo lazy después de cerrar el contexto de persistencia
-
Comprobación del error en el manejo de las colecciones en las relaciones a muchos (apartado 2.5.4)
Explica los errores en comentarios en los propios tests.
2.7.2. (0,5 puntos) Clases DAO del módulo filmoteca
En el módulo filmoteca crea en el paquete org.expertojava.jpa.filmoteca.persistencia las clases DAO correspondiente a las entidades Pelicula y Critica siguiendo el patrón visto en la sesión de teoría.
2.7.3. (0,5 puntos) Clase PeliculaServicio
Crea en el paquete org.expertojava.jpa.filmoteca.servicio la clase PeliculaServicio con los siguientes métodos de negocio:
-
Long creaPelicula(String titulo, Date fechaEstreno, String pais, Double presupuesto): crea una película y devuelve su identificador. -
void actualizaRecaudacionPelicula(Long idPelicula, Double recaudacion): actualiza la recaudación de una película.