4. Mapeo entidad-relación: relaciones
4.1. Conceptos previos
Antes de comenzar a detallar los aspectos del mapeo de las relaciones entre entidades vamos a repasar algunos conceptos básicos y alguna terminología. Es muy importante tener claro estos conceptos antes de intentar entender los entresijos a los que nos vamos a enfrentar más adelante.
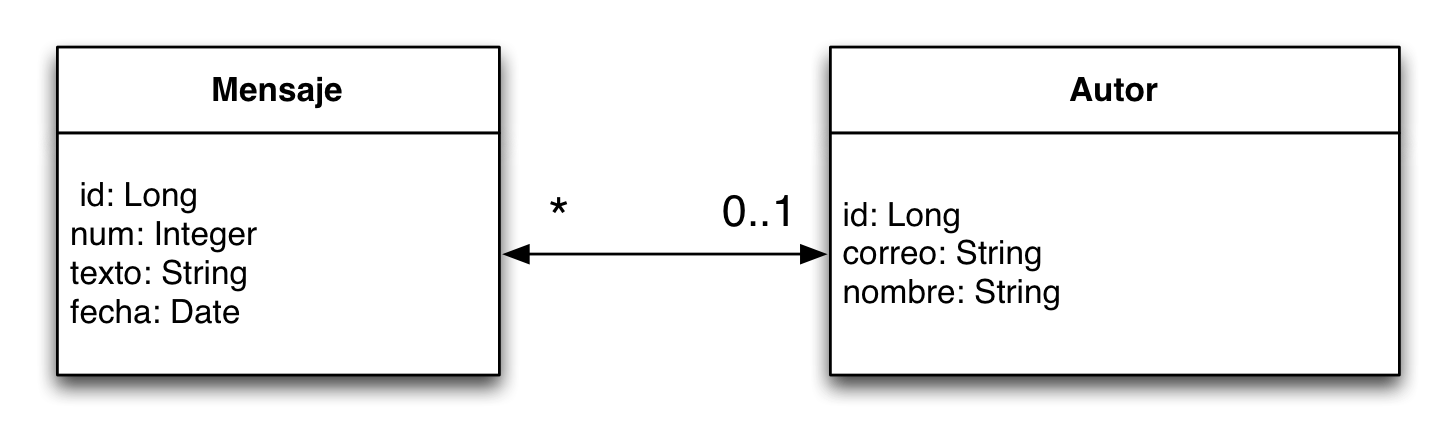
Vamos a ilustrar estos conceptos con la relación que vimos en la sesión 1. Allí definíamos dos entidades, Autor y Mensaje y una relación muchos-a-uno bidireccional de Mensaje a Autor. Un autor puede escribir muchos mensajes.
La relación la representamos con la figura siguiente, en donde se muestran las dos entidades unidas con una flecha con dos puntas que indica que la relación es bidireccional y con la anotación de la cardinalidad de cada entidad bajo la flecha. La flecha presupone un atributo con el mismo nombre y cardinalidad de la entidad a la que se apunta:
-
En la entidad
Mensajeun atributo que define unAutor -
En la entidad
Autorun atributo que define una colección de entidadesMensaje
El modelo físico que se genera con el mapeado es el que se muestra en la siguiente figura. La tabla MENSAJE contiene una clave ajena hacia la tabla AUTOR, en su columna AUTOR. Los valores de esta columna guardan claves primarias de autores. De esta forma relacionamos cada mensaje con el autor que lo ha escrito. Cuando queramos obtener todos los mensajes de un determinado autor se deberá hacer un SELECT en la tabla MENSAJE buscando todas las filas que tengan como clave ajena el autor que buscamos.
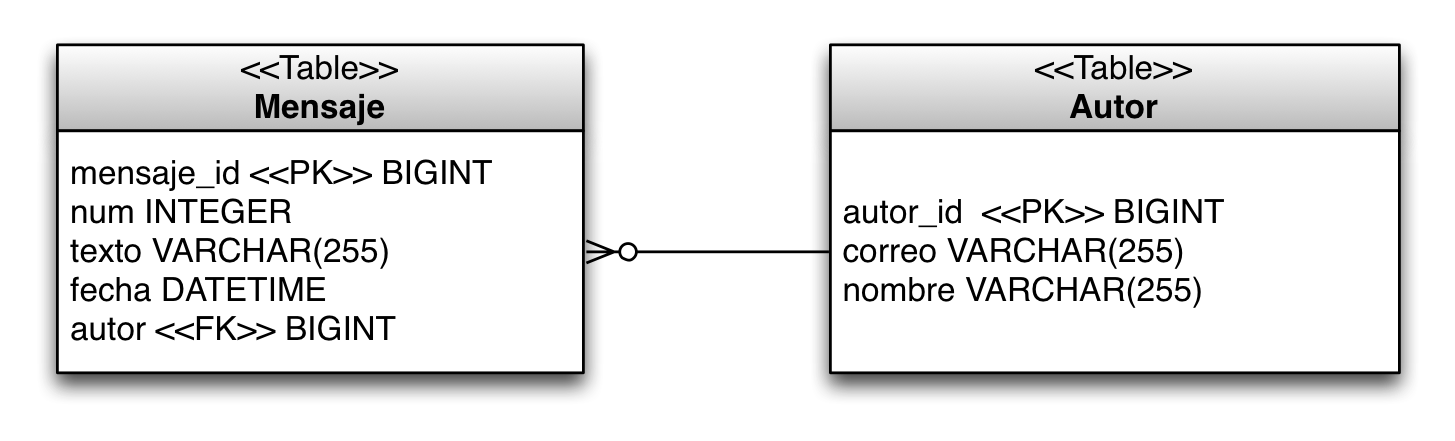
Vamos a ver las distintas características que hay que definir para especificar completamente una relación en el modelo de entidades, utilizando como ejemplo esta relación entre Mensaje y Autor.
4.1.1. Direccionalidad
En primer lugar debemos considerar la direccionalidad de la relación. Nos indica si desde una entidad podemos obtener la otra. Una relación puede ser unidireccional cuando desde la entidad origen se puede obtener la entidad destino o bidireccional, como es el caso del ejemplo, cuando desde ambas partes de la relación se puede obtener la otra parte.
En un diagrama UML, la direccionalidad viene indicada por la dirección de la flecha. En el caso del ejemplo anterior tenemos una relación bidireccional. Podemos pedirle a una instancia de Mensaje que nos diga con que Autor está relacionado. En la entidad de Mensaje habrá un método que devuelve el autor. Y al ser la relación bidireccional podemos hacer lo mismo al revés, podemos pedirle a un Autor que nos diga con qué Mensajes está relacionado. En la entidad Autor hay un método que devuelve una colección de mensajes. Por tanto, los métodos definidos por la relación son:
-
En la entidad
Mensaje:public Autor getAutor() -
En la entidad
Autor:public Set<Mensaje> getMensajes()
4.1.2. Cardinalidad
La cardinalidad de una relación define el número de instancias de una entidad que pueden estar relacionada con otras. Atendiendo a la cardinalidad, una relación puede ser uno-a-uno, uno-a-muchos, muchos-a-uno o muchos-a-muchos.
En el caso del ejemplo tenemos una relación muchos-a-uno entre Mensaje y Autor. Al ser una relación bidireccional, también podríamos considerar esta relación como una relación uno-a-muchos entre Autor y Mensaje.
4.1.3. Entidad propietaria de la relación
¿Cómo se realiza el mapeo de una relación? La forma más habitual es definir una columna adicional en la tabla asociada a una de las entidades con la clave primaria de la otra tabla con la que está relacionada. Esta columna hace de clave ajena hacia la otra tabla. Decimos que esta entidad cuya tabla contiene la clave ajena hacia la otra es la propietaria de la relación.
En el ejemplo visto, la relación se mapea haciendo que la tabla MENSAJE contenga una clave ajena hacia la tabla AUTOR, como hemos visto en la figura. Decimos entonces que la entidad Mensaje es la propietaria de la relación.
Para especificar las columnas que son claves ajenas en una relación se utilizan las anotaciones @JoinColumn y mappedBy. La primera identifica la entidad propietaria de la relación y permite definir el nombre de la columna que define la clave ajena (equivalente a la anotación @Column en otros atributos). Su uso es opcional, aunque es recomendable, ya que hace el mapeo más fácil de enteder. La segunda anotación es obligatoria se usa en el atributo de la entidad no propietaria que no se mapea en ninguna columna de la tabla. Como veremos más adelante, este elemento debe indicar el nombre del atributo que representa la clave ajena en la otra entidad.
También es posible mapear una relación utilizando una tabla join, una tabla auxiliar con dos claves ajenas hacia las tablas de la relación. No nos da tiempo en este tema de explicar cómo hacerlo. Si estás interesado puedes consultar en la especificación de JPA.
4.1.4. Actualización de la relación
Ya hemos comentado previamente que una de las características fundamentales del funcionamiento de JPA es que las instancias de las entidades viven en el contexto de persistencia asociado al entity manager hasta que se realiza una operación de flush sobre la base de datos. Normalmente esto sucede cuando se cierra la transacción. En ese momento es cuando el proveedor de persistencia consulta las instancias del contexto y genera las sentencias SQL que actualizan la base de datos. Es interesante tener activo el debug de Hibernate que muestra las sentencias generadas para comprobar en qué momento se realizan y cuáles son.
En el caso de las relaciones, la especificación de JPA avisa literalmente de lo siguiente (el énfasis es del documento original):
Es particularmente importante asegurarse de que los cambios en el lado inverso de una relación se actualizan de forma apropiada en el lado propietario, para asegurarse de que los cambios no se pierden cuando se sincronizan en la base de datos.
Esto es, para que una relación se sincronice correctamente en la base de datos, se debe actualizar la instancia a la que se refiere en la parte propietaria de la relación. En el caso del ejemplo, para añadir una relación entre un Mensaje y un Autor, lo imprescindible a efectos de actualización de la base de datos es la sentencia en la que se añade el autor asociado al mensaje (el Mensaje es la clase propietaria de la relación, la que contiene la clave ajena). JPA no actualiza automáticamente la relación en memoria. Si está definida la relación inversa (la colección de mensajes de un autor) tenemos que actualizarla a mano en el programa, añadiendo el mensaje a la colección. Todo esto se hace con dos líneas de código:
// añadimos un mensaje a un autor
// se actualiza el campo autor del mensaje
// imprescindible para actualizar la BD
mensaje.setAutor(autor);
// actualizamos la relación inversa en memoria
autor.getMensajes().add(mensaje);4.2. Definición de relaciones
Detallamos a continuación cómo se especifican las relaciones utilizando anotaciones.
4.2.1. Relación uno-a-uno unidireccional
En una relación uno-a-uno unidireccional entre la entidad A y la entidad B, una instancia de la entidad A referencia una instancia de la entidad B. En la relación A pondremos la anotación @OneToOne en el atributo referente. En la entidad B no hay que añadir ninguna anotación.
Un ejemplo podría ser la relación entre un Empleado y un Despacho (asumiendo que Despacho es una entidad, y no un objeto embebido). El código sería el siguiente:
@Entity
public class Empleado {
// ...
@OneToOne
private despacho Despacho;
// ...
public void setDespacho(Despacho despacho) {
this.despacho = despacho;
}
}
@Entity
public class Despacho {
// ...
@OneToOne(mappedBy = "despacho")
private Empleado empleado;
// ...
}La entidad Empleado es la propietaria de la relación y en su tabla hay una clave ajena (en la columna despacho) que apunta a la otra tabla. Se puede especificar esta clave ajena con la anotación @JoinColumn:
public class Empleado {
// ...
@OneToOne
@JoinColumn(name = "despacho_id", unique = true)
private Despacho despacho;
//...
public Despacho getDespacho() {
return despacho;
}
public void setDespacho(Despacho despacho) {
this.despacho = despacho;
}
}En esta anotación @JoinColumn se especifica el nombre de la columna en la tabla Empleado (despacho), el nombre de la columna con la clave primaria en la tabla a la que se apunta (idDespacho).
En el caso de no utilizar la anotación, JPA realizará el mapeo utilizando como nombre de columna el nombre del atributo que guarda la otra entidad y el nombre de la columna con la clave primaria en la otra entidad, uniéndolas con un subrayado ("_"). En este caso, se llamaría empleado_idDespacho.
Nos aseguramos de que la relación es uno-a-uno, añadiendo una restricción de unique = true que existirá en la columna correspondiente de la base de datos. Esa restricción la mantiene la base de datos.
Para actualizar la relación, basta con llamar al método setDespacho():
em.getTrasaction().begin();
Empleado empleado = em.find(Empleado.class, 1L);
Despacho despacho = em.find(Despacho.class, 3L);
empleado.setDespacho(despacho);
em.getTransaction().commit();4.2.2. Relación uno-a-uno bidireccional
Supongamos que necesitamos modificar la relación anterior para que podamos obtener el empleado a partir de su despacho. Basta con hacer que la relación anterior sea bidireccional. Para ello, debemos añadir el atributo empleado en la entidad Despacho y anotarlo con @OneToOne(mappedBy="despacho"). De esta forma estamos indicando que la entidad Empleado es la propietaria de la relación y que contiene la clave ajena en el atributo despacho.
@Empleado
public class Empleado {
// ...
@OneToOne
@JoinColumn(name = "despacho_id", unique = true)
private despacho Despacho;
// ...
}
@Entity
public class Despacho {
// ...
@OneToOne(mappedBy="despacho")
private empleado Empleado;
// ...
}Hay que destacar la utilización del elemento mappedBy en el atributo despacho. Con ese elemento estamos indicando al proveedor de persistencia cuál es la clave ajena en la entidad Empleado. En la tabla asociada a la entidad despacho no existe ninguna columna que se refiere al empleado, sino que el get se obtiene haciendo una SELECT en la otra tabla (la propietaria de la relación). En el elemento mappedBy en una entidad B hay que especificar el nombre del atributo que en la otra entidad A guarda la referencia a B.
Veamos ahora los métodos de actualización de la entidad Empleado. Definimos un método auxiliar quitaDespacho() en lugar de llamar a setDespacho con null para hacer consistentes estos métodos con los métodos de las relaciones a muchos y para evitar usar null como parámetro en un método en el que se pasa un Despacho.
@Entity
public class Empleado {
....
public Despacho getDespacho() {
return despacho;
}
public void setDespacho(Despacho despacho) {
this.despacho = despacho;
if (despacho.getEmpleado() != this) {
despacho.setEmpleado(this); (1)
}
}
public void quitaDespacho() {
if (this.getDespacho() != null) {
this.getDespacho().quitaEmpleado(); (1)
this.despacho = null;
}
}
...
}| 1 | Se actualiza relación inversa en memoria. |
Esta vez permitimos actualizar la relación en el otro lado. Al ser el lado no propietario de la relación, debemos llamar a la actualización del otro lado:
@Entity
public class Despacho {
...
public void setEmpleado(Empleado empleado) {
this.empleado = empleado;
empleado.setDespacho(this); (1)
}
public void quitaEmpleado() {
if (this.empleado != null) {
this.empleado.quitaDepartamento(); (1)
}
this.empleado = null;
}
...
}| 1 | Se actualiza la relación inversa en memoria y la base de datos, por ser la clase Empleado la propietaria de la relación. |
Un ejemplo de uso de las funciones anteriores para poner el despacho de un empleado a otro empleado (dejando sin despacho al primero):
// El empleado1 está en el despacho1. Ponemos en el despacho del empleado 1
// al empleado 3 (dejando sin despacho al empleado 1)
em.getTransaction().begin();
Empleado empleado1 = em.find(Empleado.class, 1L);
Despacho despacho1 = empleado1.getDespacho();
Empleado empleado3 = em.find(Empleado.class, 3L);
empleado1.quitaDespacho(); (1)
empleado3.setDespacho(despacho1); (2)
em.getTransaction().commit();| 1 | Al poner primero a null el despacho del empleado1 nos aseguramos de que no haya un error de integridad en la base de datos que sucedería si se cambiara primero el despacho del empleado3, antes de cambiar el despacho del empleado1. El valor de la columna departamento_id no sería único. |
| 2 | El nuevo despacho del empleado3 es el despacho1 (y también se actualiza automáticamente el otro lado de la relación en memoria: el nuevo empleado del despacho1 es el empleado3). |
4.2.3. Relación uno-a-muchos/muchos-a-uno bidireccional
En una relación uno-a-muchos bidireccional entre la entidad A y la B, una instancia de la entidad A referencia a una colección de instancias de B y una instancia de B referencia a una instancia de A. Por ejemplo la relación entre Departamento (entidad A) y Empleado (entidad B). Un departamento tiene una colección de empleados, y un empleado pertenece a un departamento. La entidad B (en este caso, Empleado) debe ser la propietaria de la relación, y contener una columna con la clave ajena a la entidad A (Departamento).
En la entidad Empleado se define un atributo del tipo de la entidad Departamento, con la anotación @ManyToOne. En la entidad Departamento se define un atributo del tipo Set<Empleado> con la anotación @OneToMany(mappedBy="departamento") que indica el nombre de la clave ajena.
El ejemplo que presentamos al comienzo del capítulo es de este tipo. Otro ejemplo podría ser el de la relación entre un departamento y los empleados. Un Departamento está relacionado con muchos Empleado`s. Y un `Empleado pertenece a un único Departamento. De esta forma el Empleado hace el papel de propietario de la relación y es quien llevará la clave ajena hacia Departamento. Lo vemos en el siguiente código:
@Entity
public class Empleado {
...
@ManyToOne
@JoinColumn(name="departamento_id")
private departamento Departamento;
...
}
@Entity
public class Departamento {
...
@OneToMany(mappedBy="departamento")
private Set<Empleado> empleados = new HashSet();
...
}En la declaración se podría eliminar la anotación @JoinColumn y el nombre de la columna con la clave ajena se obtendría de la misma forma que hemos visto en la relación uno-a-uno.
Definimos en las entidades los siguientes métodos de actualización de las relaciones. En la clase Empleado:
@Entity
public class Empleado {
...
public Departamento getDepartamento() {
return departamento;
}
public void setDepartamento(Departamento departamento) {
this.departamento = departamento;
departamento.getEmpleados().add(this); (1)
}
public void quitaDepartamento() {
Departamento departamento = this.getDepartamento();
this.departamento = null;
departamento.getEmpleados().remove(this); (1)
}
...
}| 1 | Se actualiza la relación en memoria. |
Como también hemos dicho anteriormente, la relación se actualiza insertando el nuevo Departamento en la instancia Empleado (la propietaria de la relación) con el método setDepartamento(), de esta forma nos aseguraremos que la relación se guarda en la base de datos. Sin embargo, también es importante actualizar la colección en el otro lado de la relación. La llamada a getEmpleados() es sobreescrita por JPA y es implementada por una consulta a la base de datos, pero si queremos utilizar inmediatamente la colección de empleados, debemos actualizar su contenido en memoria.
En la clase Departamento podemos definir también métodos auxiliares que llamen a los anteriores. Haremos esto sólo si es desde el punto de vista de la lógica de negocio.
@Entity
public class Departamento {
...
public Set<Empleado> getEmpleados() {
return empleados;
}
public void añadeEmpleado(Empleado empleado) {
this.getEmpleados().add(empleado);
empleado.setDepartamento(this); (1)
}
public void quitaEmpleado(Empleado empleado) {
this.getEmpleados().remove(empleado);
empleado.quitaDepartamento(); (1)
}
...
}| 1 | Se actualiza la relación inversa y la base de datos. |
Veamos varios ejemplos de uso de estas relaciones.
Actualización del departamento de un empleado, usuando los métodos quitaDepartamento() y setDepartamento():
// El empleado1 pertenece al departamento1. Lo cambiamos al departamento2.
Departamento depto1 = em.find(Departamento.class, 1L);
Departamento depto2 = em.find(Departamento.class, 2L);
Empleado empleado1 = em.find(Empleado.class, 1L);
empleado1.quitaDepartamento();
empleado1.setDepartamento(depto2);También podríamos hacer la misma actualización usando los métodos de la entidad Departamento:
// El empleado1 pertenece al departamento1. Lo cambiamos al departamento2.
Departamento depto1 = em.find(Departamento.class, 1L);
Departamento depto2 = em.find(Departamento.class, 2L);
Empleado empleado1 = em.find(Empleado.class, 1L);
depto1.quitaEmpleado(empleado1);
depto2.añadeEmpleado(empleado1);4.2.4. Relación muchos-a-uno unidireccional
En una relación muchos-a-uno unidireccional entre las entidades A y B, una instancia de A está relacionada con una instancia de B (que puede ser la misma para distintas instancias de A), pero la relación inversa que devolvería una colección de B a partir de A no está definida. Por ejemplo, sería el tipo de relación entre Empleado (A) y Categoria (B), en el caso en que no quisiéramos obtener los empleados de una determinada categoría, sino sólo saber de qué categoría es un empleado. Para definir la relación hay que definir en la entidad propietaria Empleado (A) un atributo que define la clave ajena hacia la entidad Categoría (B). Al ser una relación unidireccional no obtendremos desde la entidad B su entidad relacionada A, no definiendo ningún atributo adicional:
@Empleado
public class Empleado {
...
@ManyToOne
@JoinColumn(name="categoria_id")
private categoria Categoria;
...
}
@Entity
public class Categoria {
// ...
}4.2.5. Relación muchos-a-muchos bidireccional
En una relación muchos-a-muchos bidireccional entre la entidad A y la entidad B, una instancia de A está relacionada con una o muchas instancias de B (que pueden ser las mismas para distintas instancias de A). Por ejemplo, un Empleado (A) puede participar en más de un Proyecto (B). Dado un empleado se puede obtener la lista de proyectos en los que participa y dado un proyecto podemos obtener la lista de empleados asignados a él.
Se implementa con las siguientes anotaciones:
@Entity
public class Empleado {
@Id
@GeneratedValue
private Long id;
String nombre;
@ManyToMany
private Set<Projecto> proyectos = new HashSet();
...
public Set<Proyecto> getProyectos() {
return this.proyectos;
}
...
}
@Entity
public class Proyecto {
@Id
@GeneratedValue
private Long id;
String codigo;
@ManyToMany(mappedBy="proyectos");
private Set<Empleado> empleados = new HashSet();
...
public Set<Empleado> getEmpleados() {
return empleados;
}
...
}La anotación mappedBy apunta a la entidad propietaria de la relación. En este caso es la entidad Empleado.
La relación se mapea, a diferencia de los casos anteriores, utilizando una tabla join que construye JPA automáticamente utilizando los nombres de las dos entidades. Es una tabla con dos columnas que contienen claves ajenas a las tablas de las entidades. La primera columna apunta a la tabla propietaria de la relación y la segunda a la otra tabla. La siguiente imagen representa el mapeo de la relación anterior.
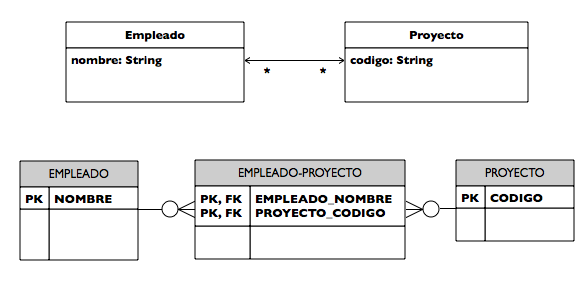
En el caso de ya existir la tabla join, o de necesitar un nombre específico para sus elementos, podríamos utilizar la anotación @JoinTable de la siguiente forma:
@Entity
public class Empleado {
...
@ManyToMany
@JoinTable(
name = "EMPLEADO_PROYECTO",
joinColumns = {@JoinColumn(name = "EMPLEADO_NOMBRE")},
inverseJoinColumns = {@JoinColumn(name = "PROYECTO_CODIGO")}
)
private Set<Projecto> proyectos = new HashSet<Projecto>();
...
}La anotación joinColumns hace referencia a la columna de la tabla join que contiene el identificador (o identificadores, en el caso de una clave compuesta) a la propia entidad (Empleado en este caso). La anotación inverseJoinColumns identifica la columna que hace referencia a la otra entidad (Proyecto).
En el otro lado de la relación no hace falta declarar la tabla join:
@ManyToMany(mappedBy = "proyectos")
private Set<Empleado> empleados = new HashSet<Proyecto>();A la hora de actualizar la relación es muy importante tener en cuenta qué entidad es la propietaria de la relación, la que se sincronizará con la base de datos. En este caso, en el lado propietario (Empleado) tenemos una colección de proyectos. Para añadir un nuevo empleado a un proyecto debemos obtener la referencia a la colección de proyectos en los que participa el empleado (con el método getProyectos()) y añadir el nuevo proyecto con el método add() de la colección. Por ejemplo, para añadir el empleado 1 al proyecto 2, debemos añadir el proyecto 2 a los proyectos del empleado 1. También hay que actualizar el otro lado de la relación, para mantener correctamente la relación en memoria.
em.getTransaction().begin();
Proyecto proyecto2 = em.find(Proyecto.class, 2L);
Empleado empleado1 = em.find(Empleado.class, 1L);
empleado1.getProyectos().add(proyecto2); (1)
proyecto2.getEmpleados().add(empleado1); (2)
em.getTransaction().commit();| 1 | Se actualiza el lado propietario de la relación para actualizar la relación en la base de datos. |
| 2 | Se actualiza el otro lado de la relación para actualizar la relación en memoria. |
Para borrar un empleado de un proyecto también hay que modificar la relación en el lado de propietario de la relación para actualizar la base de datos, y el otro lado para actualizar la relación en memoria:
Proyecto proyecto2 = em.find(Proyecto.class, 2L);
Empleado empleado3 = em.find(Empleado.class, 3L);
empleado3.getProyectos().remove(proyecto2); (1)
proyecto2.getEmpleados().remove(empleado3); (2)| 1 | Se actualiza el lado propietario de la relación para actualizar la relación en la base de datos |
| 2 | Se actualiza el otro lado de la relación para actualizar la relación en memoria |
Es conveniente definir estas actualizaciones en métodos auxiliares en las entidades. En la clase Empleado (propietaria de la relación):
@Entity
public class Empleado {
...
public Set<Proyecto> getProyectos() {
return proyectos;
}
public void añadeProyecto(Proyecto proyecto) {
this.getProyectos().add(proyecto);
proyecto.getEmpleados().add(this);
}
public void quitaProyecto(Proyecto proyecto) {
this.getProyectos().remove(proyecto);
proyecto.getEmpleados().remove(this);
}
...
}En la clase Proyecto:
@Entity
public class Proyecto {
...
public Set<Empleado> getEmpleados() {
return empleados;
}
public void añadeEmpleado(Empleado empleado) {
empleado.getProyectos().add(this);
this.getEmpleados().add(empleado);
}
public void quitaEmpleado(Empleado empleado) {
empleado.getProyectos().remove(this);
this.getEmpleados().remove(empleado);
}
...
}Un ejemplo de uso de los métodos auxiliares para añadir un empleado a un proyecto
// Empleados proyecto2 = {empleado2, empleado3}
// Proyectos empleado1 = {proyecto1}
// Añadimos el empleado 1 al proyecto 2 usando los métodos auxiliares
Proyecto proyecto2 = em.find(Proyecto.class, 2L);
Empleado empleado1 = em.find(Empleado.class, 1L);
empleado1.añadeProyecto(proyecto2);Y un ejemplo para eliminar un empleado de un proyecto:
Proyecto proyecto2 = em.find(Proyecto.class, 2L);
Empleado empleado3 = em.find(Empleado.class, 3L);
empleado3.quitaProyecto(proyecto2);4.2.6. Relación muchos-a-muchos unidireccional
En una relación muchos-a-muchos unidireccional entre una entidad A y otra entidad B, cada instancia de la entidad A está relacionada con una o muchas instancias de B (que pueden ser las mismas para distintas instancias de A). Al ser una relación unidireccional, dada una instancia de B no nos interesa saber la instancia de A con la que está relacionada.
Por ejemplo, un Empleado tiene una colección de Patentes que ha desarrollado. Distintos empleados pueden participar en la misma patente. Pero no nos interesa guardar la información de qué empleados han desarrollado una patente determinada. La forma de especificarlo es:
@Entity
public class Empleado {
@Id String nombre;
@ManyToMany
private Set<Patentes> patentes = new HashSet();
public Set<Patentes> getPatentes() {
return this.patentes;
}
public void setPatentes(Set<Patentes> patentes) {
this.patentes = patentes;
}
// ...
}
@Entity
public class Patente {
// ...
}En el mapeo de la relación se crea una tabla join llamada EMPLEADO_PATENTE con las dos claves ajenas hacia EMPLEADO y PATENTE.
La forma de actualizar la relación es la misma que en la relación bidireccional.
4.2.7. Columnas adicionales en la tabla join
Es bastante usual encontrar columnas adicionales en las tablas join, además de las dos columnas ajenas. Imaginemos, por ejemplo, que necesitamos almacenar alguna información cada vez que añadimos un Proyecto a una Empleado. Por ejemplo, la fecha en la que el empleado entra en el proyecto y el cargo en el mismo. Lo vemos en la siguiente figura.
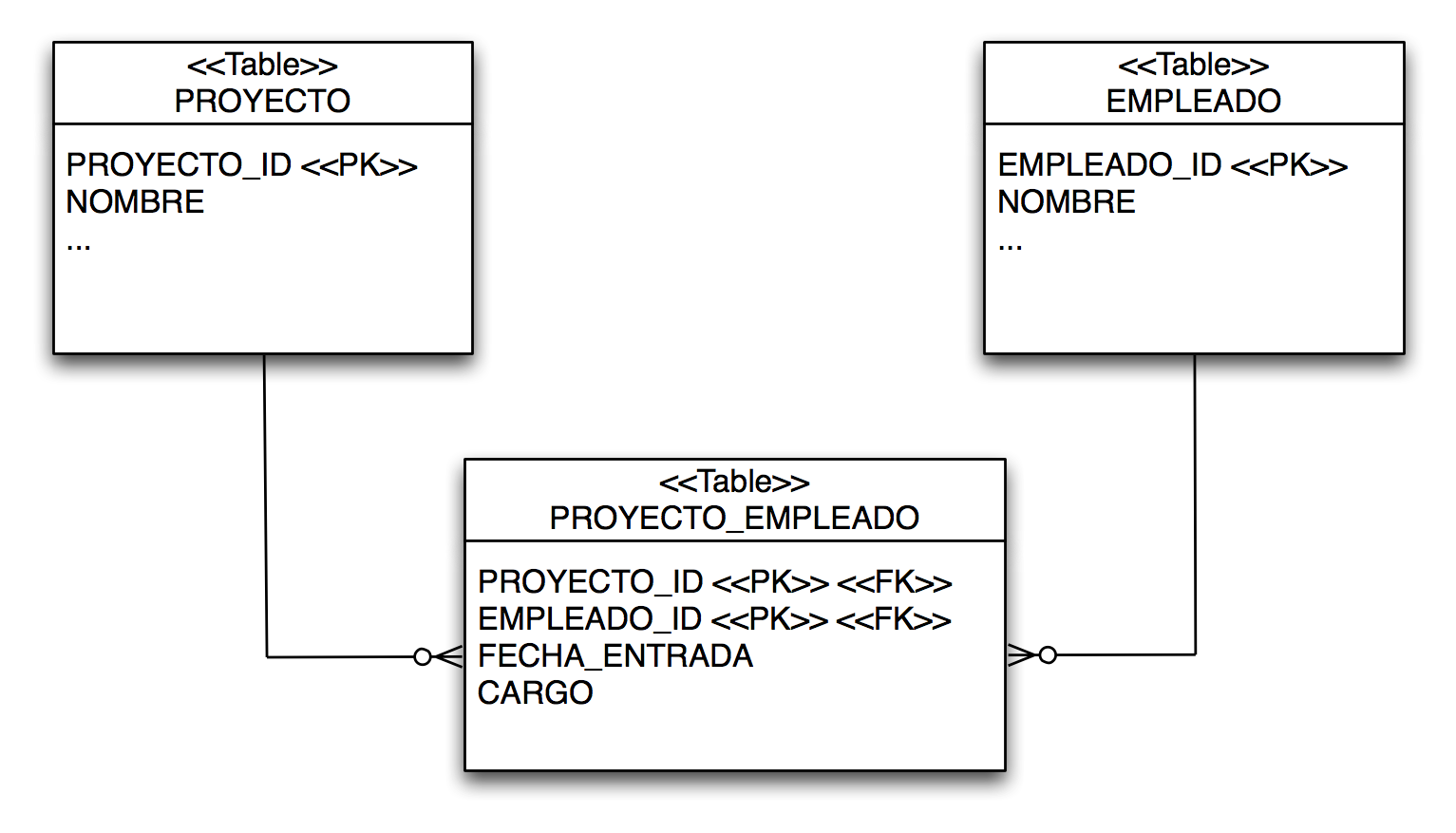
Una forma de mapearlo a JPA es creando una entidad nueva en la que se mapea la tabla. Llamamos a la entidad ProyectoEmpleado. Tiene como clave primaria la pareja de claves ajenas a las tablas de empleados y proyectos:
@Entity
@Table(name = "PROYECTO_EMPLEADO")
public class ProyectoEmpleado {
@Embeddable
public static class Id implements Serializable {
@Column(name = "PROYECTO_ID")
private int proyectoId;
@Column(name = "EMPLEADO_ID")
private int empleadoId;
public Id() {}
public Id(int proyectoId, int empleadoId) {
this.proyectoId = proyectoId;
this.empleadoId = empleadoId;
}
public boolean equals(Object o) {
if (o != null && o instanceof Id) {
Id that = (Id) o;
return this.proyectoId.equals(that.proyectoId) &&
this.empleadoId.equals(that.empleadoId);
} else {
return false;
}
}
public int hashCode() {
return proyectoId.hashCode() + empleadoId.hashCode();
}
}
@EmbeddedId
private Id id = new Id();
@Column(name = "FECHA")
private Date fecha = new Date();
@Column(name = "CARGO")
private String cargo;
@ManyToOne
@JoinColumn(name="PROYECTO_ID",
insertable = false,
updatable = false)
private Proyecto proyecto;
@ManyToOne
@JoinColumn(name="EMPLEADO_ID",
insertable = false,
updatable = false)
private Empleado empleado;
public ProyectoEmpleado() {}
public ProyectoEmpleado(Proyecto proyecto,
Empleado emplado,
String cargo) {
this.proyecto = proyecto;
this.empleado = empleado;
this cargo = cargo;
this.id.proyectoId = proyecto.getId();
this.id.empleadoId = empleado.getId();
// Garantizamos la actualización en memoria
proyecto.getProyectoEmpleados().add(this);
empleado.getProyectoEmpleados().add(this);
}
// Getters y setters
...
}Este es un buen ejemplo para terminar el apartado, porque se utilizan en él múltiples elementos que hemos ido viendo en las dos últimas sesiones. Se utiliza como clave primaria de la nueva entidad una clave compuesta con las columnas PROYECTO_ID y EMPLEADO_ID. Hemos utilizado la estrategia de clase estática anidada para definirla. En el constructor se actualizan los valores de la clave primaria con las claves primarias del proyecto y el empleado. También se actualizan las propiedades que definen la relación a-muchos (proyecto y empleado) y se actualizan las relaciones inversas para asegurar la integridad referencial en memoria.
4.3. Carga perezosa
Hemos comentado que una de las características de JPA es la carga perezosa (lazy fetching en inglés). Este concepto es de especial importancia cuando estamos trabajando con relaciones.
Supongamos los ejemplos anteriores, con la relación uno-a-muchos entre Departamento y Empleado y la relación muchos-a-muchos entre Empleado y Proyecto. Cuando recuperamos un departamento de la base ese departamento está relacionado con un conjunto de empleados, que a su vez están relacionados cada uno de ellos con un conjunto de proyectos. La carga perezosa consiste en que no se cargan todos los objetos en el contexto de persistencia, sino sólo la referencia al departamento que se ha recuperado. Es cuando se realiza una llamada al método getEmpleados() cuando se recuperan de la base de datos todas las instancias de Empleado con las que ese departamento está relacionado. Pero sólo los empleados. Los proyectos de cada empleado no se cargan hasta que no se llama al método getProyectos() del empleado que nos interese.
Esta funcionalidad hace que la carga de instancias sea muy eficiente, pero hay que saber utilizarla correctamente. Un posible problema puede surgir cuando la instancia original (el Departamento) queda desconectada (detached) del EntityManager (lo veremos en el tema siguiente). Entonces ya no podremos acceder a ningún atributo que no se haya cargado.
Es posible que quereamos desactivar la propiedad por defecto de la carga perezosa. Para ello debemos definir la opción fetch=FetchType.EAGER en la anotación que define el tipo de relación:
@Entity
public class Empleado {
@Id String nombre;
@ManyToMany(fetch=FetchType.EAGER)
private Set<Patentes> patentes = new HashSet();
// ...
}4.4. Referencias e información adicional
Puedes encontrar más información sobre las relaciones entre entidades JPA en la documentación de Hibernate que incluye muchos ejemplos de distintos tipos de mapeado, incluyendo características no estándar en JPA.
4.5. Ejercicios
Continuamos con el proyecto filmoteca.
4.5.1. (0,75 punto) Relación muchos-a-muchos entre Pelicula y Actor
Crea la clase Actor con los siguientes campos:
-
Identificador autogenerado como clave primaria (
Long) -
nombre(String) -
fechaNacimiento(Date) -
Sexo(Enumerado:hombreomujer) -
Biografia(String) -
relación muchos-a-muchos con
Pelicula
4.5.2. (0,75 puntos) DAOs ActorDao y CriticaDao
Crea los DAO ActorDao y CriticaDao. Crea la clase ActorServicio con los métodos:
-
Long nuevoActor(String nombre, Date fechaNacimiento, Sexo sexo, String biografia): añade un actor -
void añadePeliculaActor(Long idActor, Long idPelicula): añade un actor a una película ya existente -
List<Actor> buscaActorNombre(String nombre): devuelve una lista de actores que tienen el nombre que le pasamos como parámetro -
List<Pelicula> peliculasActor(Long idActor): devuelve la lista completa de películas en las que ha participado un actor