3. Rendimiento en MongoDB
En esta unidad vamos a estudiar como diseñar el esquema, así como el uso de índices y otras herramientas avanzadas para mejorar el rendimiento.
3.1. Diseñando el esquema
MongoDB es una base de datos documental, no relacional, donde el esquema no se debe basar en el uso de claves ajenas/joins, ya que no existen.
A la hora de diseñar un esquema, si nos encontramos que el esquema esta en 3FN o si cuando hacemos consultas (recordad que no hay joins) estamos teniendo que realizar varias consultas de manera programativa (primero acceder a una tabla, con ese _id ir a otra tabla, etc….) es que no estamos siguiendo el enfoque adecuado.
MongoDB no soporta transacciones, ya que su enfoque distribuido dificultaría y penalizaría el rendimiento. En cambio, sí que asegura que las operaciones sean atómicas. Los posibles enfoques para solucionar la falta de transacciones son:
-
Restructurar el código para que toda la información esté contenida en un único documento.
-
Implementar un sistema de bloqueo por software (semáforo, etc…).
-
Tolerar un grado de inconsistencia en el sistema.
Dependiendo del tipo de relación entre dos documentos, normalizaremos los datos para minimizar la redundancia pero manteniendo en la medida de lo posible que mediante operaciones atómicas se mantenga la integridad de los datos. Para ello, bien crearemos referencias entre dos documentos o embeberemos un documento dentro de otro.
3.1.1. Referencias
Las aplicaciones que emplean MongoDB utilizan dos técnicas para relacionar documentos:
-
Referencias Manuales
-
Uso de DBRef
Referencias manuales
De manera similar a una base de datos relacional, se almacena el campo _id de un documento en otro documento a modo de clave ajena. De este modo, la aplicación realiza una segunda consulta para obtener los datos relaciones. Estas referencias son sencillas y suficientes para la mayoría de casos de uso.
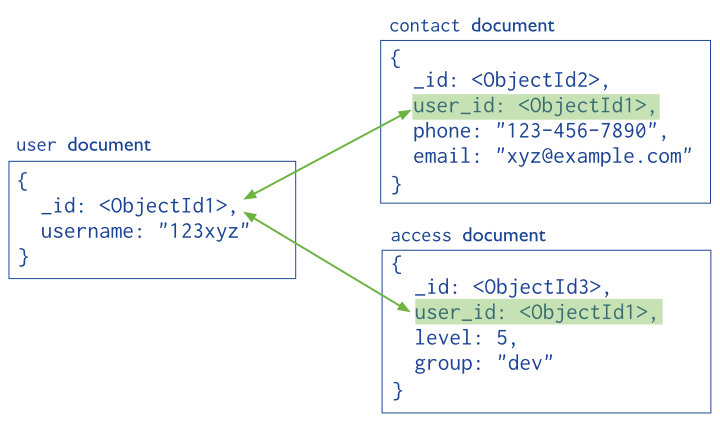
Por ejemplo, si nos basamos en el gráfico anterior, podemos conseguir referenciar estos objetos del siguiente modo:
var idUsuario = ObjectId();
db.usuario.insert({
_id: idUsuario,
nombre: "123xyz"
});
db.contacto.insert({
usuario_id: idUsuario,
telefono: "123 456 7890",
email: "xyz@ejemplo.com"
});DBRef
Son referencias de un documento a otro mediante el valor del campo _id, el nombre de la colección y, opcionalmente, el nombre de la base de datos. Estos objetos siguen una convención para representar un documento mediante la notación { "$ref" : <nombreColeccion>, "$id" : <valorCampo_id>, "$db" : <nombreBaseDatos> }.
Al incluir estos nombres, las DBRef permite referenciar documentos localizados en diferentes colecciones.
Así pues, si reescribimos el código anterior mediante DBRef tendríamos que el contacto queda de la siguiente manera:
db.contacto.insert({
usuario_id: new DBRef("usuario", idUsuario),
telefono: "123-456-7890",
email: "xyz@example.com"
});De manera similar a las referencias manuales, mediante consultas adicionales se obtendrán los documentos referenciados.
Muchos drivers (incluido el de Java, mediante la clase DBRef) contienen métodos auxiliares que realizan las consultas con referencias DBRef automáticamennte.
| Desde la propia documentación de MongoDB, recomiendan el uso de referencias manuales, a no ser de que dispongamos documentos de una colección que referencian a documentos que se encuentran en varias colecciones diferentes. |
3.1.2. Datos embebidos
En cambio, si dentro de un documento almacenamos los datos mediante sub-documentos, ya sea dentro de un atributo o un array, podremos obtener todos los datos mediante un único acceso.

Generalmente, emplearemos datos embebidos cuando tengamos:
-
relaciones "contiene" entre entidades, entre relaciones de documentos "uno a uno" o "uno a pocos".
-
relaciones "uno a muchos" entre entidades. En estas relaciones los documentos hijo (o "muchos") siempre aparecen dentro del contexto del padre o del documento "uno".
Los datos embebidos ofrecen mejor rendimiento al permitir obtener los datos mediante una única operación, así como modificar datos relacionados en una sola operación atómica de escritura.
Un aspecto a tener en cuenta es que un documento BSON puede contener un máximo de 16MB. Si quisiéramos que un atributo contenga más información, tendríamos que utilizar el API de GridFS que veremos más adelante.
3.1.3. Relaciones
Vamos a estudiar en detalle cada uno de los tipos de relaciones, para intentar clarificar cuando es conveniente utilizar referencias o datos embebidos.
1:1
Cuando existe una relación 1:1, como pueda ser entre Persona y Curriculum, o Persona y Direccion hay que embeber un documento dentro del otro, como parte de un atributo.
{
nombre: "Aitor",
edad: 38,
direccion: {
calle: "Mayor",
ciudad: "Elx"
}
}La principal ventaja de este planteamiento es que mediante una única consulta podemos obtener tanto los detalles del usuario como su dirección.
Un par de aspectos que nos pueden llevar a no embeberlos son:
-
la frecuencia de acceso. Si a uno de ellos se accede raramente, puede que convenga tenerlos separados para liberar memoria.
-
el tamaño de los elementos. Si hay uno que es mucho más grande que el otro, o uno lo modificamos muchas más veces que el otro, para que cada vez que hagamos un cambio en un documento no tengamos que modificar el otro será mejor separarlos en documentos separados.
Pero siempre teniendo en cuenta la atomicidad de los datos, ya que si necesitamos modificar los dos documentos al mismo tiempo, tendremos que embeber uno dentro del otro.
1:N
Vamos a distinguir dos tipos:
-
1 a muchos, como puede ser entre
EditorialyLibro. Para este tipo de relación es mejor usar referencias entre los documentos:
{
_id: 1,
nombre: "O'Reilly",
pais: "EE.UU."
}{
_id: 1234,
titulo: "MongoDB: The Definitive Guide",
autor: [ "Kristina Chodorow", "Mike Dirolf" ],
numPaginas: 216,
editorial_id: 1,
}
{
_id: 1235,
titulo: "50 Tips and Tricks for MongoDB Developer",
autor: "Kristina Chodorow",
numPaginas: 68,
editorial_id: 1,
}-
1 a pocos, como por ejemplo, dentro de un blog, la relación entre
MensajeyComentario. En este caso, la mejor solución es crear un array dentro de la entidad 1 ( en nuestro caso,Mensaje). De este modo, elMensajecontiene un array deComentario:
{
titulo: "La broma asesina",
url: "http://es.wikipedia.org/wiki/Batman:_The_Killing_Joke",
texto: "La dualidad de Batman y Joker",
comentarios: [
{
autor: "Bruce Wayne",
fecha: ISODate("2015-04-01T09:31:32Z"),
comentario: "A mi me encantó"
},
{
autor: "Bruno Díaz",
fecha: ISODate("2015-04-03T10:07:28Z"),
comentario: "El mejor"
}
]
}| Hay que tener siempre en mente la restricción de los 16 MB de BSON. Si vamos a embeber muchos documentos y estos son grandes, hay que vigilar no llegar a dicho tamaño. |
En ocasiones las relaciones 1 a muchos se traducen en documentos embebidos cuando la información que nos interesa es la que contiene en un momento determinado. Por ejemplo, dentro de Pedido, el precio de los productos debe embeberse, ya que si en un futuro se modifica el precio de un producto determinado debido a una oferta, el pedido realizado no debe modificar su precio total.
Del mismo modo, al almacenar la dirección de una persona, también es conveniente embeberla. No queremos que la dirección de envío de un pedido se modique si un usuario modifica sus datos personales.
N:M
Más que relaciones muchos a muchos, suelen ser relaciones pocos a pocos, como por ejemplo, Libro y Autor, o Profesor y Estudiante.
Supongamos que tenemos libros de la siguiente manera y autores con la siguiente estructura:
{
_id: 1,
titulo: "La historia interminable",
anyo: 1979
}{
_id: 1,
nombre: "Michael Ende",
pais: "Alemania"
}Podemos resolver estas relaciones de tres maneras:
-
Siguiendo un enfoque relacional, empleando un documento como la entidad que agrupa con referencias manuales a los dos documentos.
Ejemplo relación N:M - Autor/Libro{ autor_id: 1, libro_id: 1 }Este enfoque se desaconseja porque necesita tres consultas para obtener toda la información.
-
Mediante 2 documentos, cada uno con un array que contenga los ids del otro documento (2 Way Embedding). Hay que tener cuidado porque podemos tener problemas de inconsistencia de datos si no actualizamos correctamente.
Ejemplo relación N:N - Libro referencia a Autor{ _id: 1, titulo: "La historia interminable", anyo: 1979, autores: [1] },{ _id: 2, titulo: "Momo", anyo: 1973, autores: [1] }Ejemplo relación N:M - Autor referencia a Libro{ _id: 1, nombre: "Michael Ende", pais: "Alemania", libros: [1,2] } -
Embeber un documento dentro de otro (One Way Embedding). Por ejemplo:
Ejemplo relación N:M - Autor embebido en Libro{ _id: 1, titulo: "La historia interminable", anyo: 1979, autores: [{nombre:"Michael Ende", pais:"Alemania"}] },{ _id: 2, titulo: "Momo", anyo: 1973, autores: [{nombre:"Michael Ende", pais:"Alemania"}] }En principio este enfoque no se recomienda porque el documento puede crecer mucho y provocar anomalías de modificaciones donde la información no es consistente. Si se opta por esta solución, hay que tener en cuenta que si un documento depende de otro para su creación (por ejemplo, si metemos los profesores dentro de los estudiantes, no vamos a poder dar de alta a profesores sin haber dado de alta previamente a un alumno).
A modo de resumen, en las relaciones N:M, hay que establecer el tamaño de N y M. Si N como máximo vale 3 y M 500000, entonces deberíamos seguir un enfoque de embeber la N dentro de la M (One Way Embedding).
En cambio, si N vale 3 y M vale 5, entonces podemos hacer que ambos embeban al otro documento (Two Way Embedding).
| Más información en http://docs.mongodb.org/manual/applications/data-models-relationships/ |
Jerárquicas
Si tenemos que modelar alguna entidad que tenga hijos y nos importa las relaciones padre-hijos (categoría-subcategoría), podemos tanto embeber un array con los hijos de un documento (children), como embeber un array con los padres de un documento (ancestors)
| Más información en http://docs.mongodb.org/manual/applications/data-models-tree-structures/ |
3.1.4. Rendimiento
De modo general, si vamos a realizar más lecturas que escrituras, es más conveniente denormalizar los datos para usar datos embebidos y así con sólo una lectura obtengamos más información. En cambio, si realizamos muchas inserciones y sobretodo actualizaciones, será conveniente usar referencias con dos documentos.
El mayor beneficio de embeber documentos es el rendimiento, sobretodo el de lectura. El acceso a disco es la parte más lenta, pero una vez la aguja se ha colocado en el sector adecuado, la información se obtiene muy rápidamente (alto ancho de banda). El hecho de que toda la información a recuperar esté almacenada de manera secuencial, mediante documentos embebidos, favorece que el rendimiento de lectura sea muy alto, ya que sólo se hace un acceso a la BBDD. Por lo tanto, si la consistencia es secundaria, duplicar los datos (pero de manera limitada) no es una mala idea, ya que el espacio en disco es más barato que el tiempo de computación.
Es por ello, que un planteamiento inicial a la hora de modelar los datos es basarse en unidades de aplicación, entendiendo como unidad una petición al backend, ya sea el click de un botón o la carga de los datos para un gráfico. Así pues, cada unidad de aplicación se debería poder conseguir con una única consulta, y por tanto, en gran medida los datos estarán embebidos.
Si lo que necesitamos es consistencia de datos, entonces hay que normalizar y usar referencias. Esto conllevará que al modificar un documento, al estar normalizado los datos serán consistentes, aunque necesitemos dos o más lecturas para obtener la información deseada.
Hay que tener en cuenta que no debemos hacer joins en las lecturas. En todo caso, si tenemos redundancia, las realizaremos en las escrituras.
| Estos y más consejos en 6 Rules of Thumb for MongoDB Schema Design: http://blog.mongodb.org/post/87200945828/6-rules-of-thumb-for-mongodb-schema-design-part-1 |
3.2. Transacciones y concurrencia
Ya hemos visto que MongoDB no soporta el concepto de transacción. Mientras que en un SGDB relacional podemos agrupar varias operaciones en una transacción para obtener atomicidad y rollback, en MongoDB solo podemos utilizar las diferentes operaciones de modificación que trabajan con la estructura interna de un documento. Así pues, la manera de resolver que no haya soporte para transacciones es incrementar la complejidad de un documento para que contenga varios documentos anidados.
En el caso de necesitar las transacciones de manera explícita, tal como una aplicación bancaria, no hay nada mejor que una base de datos relacional. Dependiendo del escenario, se pueden combinar ambos enfoques (relacional y MongoDB), mediante una infraestructura más compleja, tanto de desarrollar como de mantener. Estas soluciones híbridas se están haciendo más comunes, y dan pie al concepto de persistencia políglota.
Respecto a la concurrencia, en los SGBD relacionales, la gestión que se realiza de la ejecución concurrente de una unidad de trabajo se implementa mediante bloqueos o control de multiversiones para aislar cada unidad de trabajo. En cambio, MongoDB emplea bloqueos de lectura/escritura que permiten acceso concurrente para las lecturas de un recurso (ya sea una base de datos o una colección), pero sólo da acceso exclusivo para cada operación de escritura.
De una manera más detallada, MongoDB gestiona los bloqueos de lectura y escritura del siguiente modo:
-
Puede haber un número ilimitado de lecturas simultáneas a un base de datos.
-
En un momento dado, sólo puede haber un escritor en cualquier colección en cualquier base de datos.
-
Una vez recibida una petición de escritura, el escritor bloquea a todos los lectores.
Desde la versión 2.2, se puede restringir el alcance del bloqueo a la base de datos sobre la que se realiza la lectura o la escritura. Desde la versión 3.0, se ha mejorado la gestión de la concurrencia, y sólo se bloquean los documentos implicados en la operación de escritura.
Para almacenar información sobre los bloqueos, MongoDB se basa en el motor de almacenamiento, el cual define como se almancenan los datos en el disco. A día de hoy, MongoDB ofrece dos motores:
-
MMAPv1: Almacenamiento por defecto. Emplea bloqueos a nivel de colección.
-
WiredTiger: Nuevo motor de almacenamiento, que ofrece bloqueo a nivel de documento y permite compresión de los datos. Mediante este motor, múltiples clientes pueden modificar más de un documento de una misma colección al mismo tiempo.
Para indicar el motor de almacenamiento empleado, al arrancar el demonio de MongoDB, mediante el parámetro --storageEngine podemos indicar si queremos mmapv1 o wiredTiger:
wiredTigermongod --storageEngine wiredTiger3.3. GridFS
Tal como comentamos anteriormente, los documentos BSON tienen la restricción de que no pueden ocupar más de 16 MB. Si necesitamos almacenar Blobs, hemos de utilizar GridFS, el cual es una utilidad que divide un Blob en partes para crear una colección y poder almacenar más información.
Así pues, en vez de almacenar un fichero en un único documento, GridFS divide el fichero en partes, o trozos (chunks), y almacena cada uno de estos trozos en un documento separado. Por defecto, GridFS limita el tamaño de cada trozo a 256KB.
Para ello, utiliza dos colecciones para almacenar los archivos:
-
La colección
chunksalmacena los trozos de los ficheros -
Mientra que la colección
filesalmacena los metadatos de los ficheros.
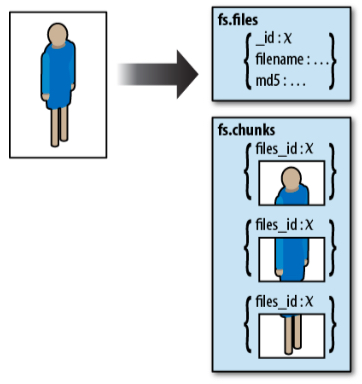
Estas colecciones se crean en el espacio de nombres fs. Este nombre se puede modificar, por ejemplo, si queremos almacenar diferentes tipos de archivos, es decir, por una lado imágenes y por otro vídeos.
Cuando se consulta un almacén GridFS por un fichero, el driver o el cliente unirá los trozos tal como necesite. Se pueden hacer consultas sobre ficheros almacenados con GridFS. También se puede acceder a información de secciones arbitrarias de los ficheros, lo que nos permite saltar a la mitad de un archivo de sonido o video.
3.3.1. mongofiles
Para interactuar con los archivos almacenados desde la consola utilizaremos el comando mongofiles.
Si queremos visualizar todos los ficheros que tenemos en nuestra base de datos usaremos la opción list:
mongofiles$ mongofiles listAl estar vacía la base de datos no se mostrará nada. Aunque en el día a día no utilizaremos mongofiles para interactuar con los archivos, si que es muy útil para explorar y probar los archivos almacenados.
Una vez que creamos un archivo, podemos usar la herramienta para explorar los archivos y trozos creados.
Para incluir un archivo, se realiza mediante la opción de put:
Por ejemplo, para añadir el archivo video.mp4 haríamos:
mongofiles$ mongofiles put video.mp4
connected to: 127.0.0.1
added file: { _id: ObjectId('550957b83f627a4bb7f28bc8'), filename: "video.mp4", chunkSize: 261120, uploadDate: new Date(1426675642227), md5: "b7d51c0c83ef61ccf69f223eded44797", length: 39380552 }
done!Podemos observar que tras la inserción, obtenemos un documento que contiente:
-
chunkSize: el tamaño de cada trozo -
length: tamaño del fichero -
uploadDate: fecha de creación del fichero en MongoDB
Si ahora comprobamos los archivos disponibles tendremos:
mongofiles$ mongofiles list
connected to: 127.0.0.1
video.mp4 39380552Estas operaciones de consulta también la podemos realizar directamente realizando una consulta a la colección fs.files mediante el comando db.fs.files.find() desde mongo:
fs.files> db.fs.files.find()
{ "_id" : ObjectId("550957b83f627a4bb7f28bc8"), "filename" : "video.mp4", "chunkSize" : 261120, "uploadDate" : ISODate("2015-03-18T10:47:22.227Z"), "md5" : "b7d51c0c83ef61ccf69f223eded44797", "length" : 39380552 }Si queremos obtener información sobre los trozos de un archivo (chunks), consultaremos la colección fs.chunks añadiendo un filtro para que no nos muestre la información en binario:
fs.chunks> db.fs.chunks.find({}, {"data":0})
{ "_id" : ObjectId("550957b856eb8d804bc96fb8"), "files_id" : ObjectId("550957b83f627a4bb7f28bc8"), "n" : 0 }
{ "_id" : ObjectId("550957b956eb8d804bc96fb9"), "files_id" : ObjectId("550957b83f627a4bb7f28bc8"), "n" : 1 }
...
{ "_id" : ObjectId("550957ba56eb8d804bc9704e"), "files_id" : ObjectId("550957b83f627a4bb7f28bc8"), "n" : 150 }| Toda interacción con GridFS se debe realizar a través de un driver para evitar incongruencias en los datos. |
Otras operaciones que podemos realizar con mongofiles son:
-
search: busca una cadena en el archivo -
delete: elimina un archivo de GridFS -
get: obtiene un archivo
Todas las opciones de mongofiles se pueden consultar en http://docs.mongodb.org/manual/reference/program/mongofiles/
3.3.2. GridFS desde Java
El driver Java de MongoDB ofrece la clase GridFS para interactuar con los archivos. A partir de dicha clase vamos a poder almacenar archivos en MongoDB.
A continuación, se muestra mediante código Java como leer un archivo de vídeo y almacenarlo en la base de datos:
MongoClient cliente = new MongoClient();
DB db = cliente.getDB("expertojava");
FileInputStream inputStream = null;
GridFS videos = new GridFS(db);
try {
inputStream = new FileInputStream("video.mp4"); (1)
} catch (FileNotFoundException e) {
System.out.println("No puedo abrir el fichero");
System.exit(1);
}
GridFSInputFile video = videos.createFile(inputStream, "video.mp4"); (2)
// Creamos algunos metadatos para el vídeo
BasicDBObject meta = new BasicDBObject("descripcion", "Prevención de riesgos laborales");
List<String> tags = new ArrayList<String>();
tags.add("Prevención");
tags.add("Ergonomía");
meta.append("tags", tags);
video.setMetaData(meta); (3)
video.save(); (4)
System.out.println("Object ID: " + video.get("_id"));| 1 | Leemos el archivo desde el sistema de archivos |
| 2 | Creamos un objeto GridFS que referencia al archivo |
| 3 | Le asociamos al archivo metadatos mediante una lista de cadenas |
| 4 | Almacena el archivo en la colección |
Al ejecutar este fragmento de código, la colección fs.files contendrá un documento similar al siguiente donde podemos observar que se ha añadido una propiedad ` metadata`:
{ "_id" : ObjectId("553a78edd4c66e72c890472b"), "chunkSize" : NumberLong(261120), "length" : NumberLong(39380552), "md5" : "b7d51c0c83ef61ccf69f223eded44797", "filename" : "video.mp4", "contentType" : null, "uploadDate" : ISODate("2015-04-24T17:10:05.356Z"), "aliases" : null, "metadata" : { "descripcion" : "Prevención de riesgos laborales", "tags" : [ "Prevención", "Ergonomía" ] } }Si lo que queremos es obtener un archivo que tenemos almacenado en la base de datos para guardarlo en un fichero haríamos:
MongoClient cliente = new MongoClient();
DB db = cliente.getDB("expertojava");
GridFS videos = new GridFS(db);
// Buscamos un fichero
GridFSDBFile gridFile = videos.findOne(new BasicDBObject("filename", "video.mp4")); (1)
FileOutputStream outputStream = new FileOutputStream("video_copia.mp4");
gridFile.writeTo(outputStream); (2)
// Buscamos varios ficheros
List <GridFSDBFile> ficheros = videos.find(new BasicDBObject("descripción", "Prueba")); (3)
for (GridFSDBFile fichero: ficheros) {
System.out.println(fichero.getFilename());
}| 1 | Buscamos en GridFS un archivo por su nombre el cual se almacena en un objeto GridFSDBFile |
| 2 | Escribimos el contenido del gridFile en un nuevo archivo |
| 3 | Al obtener varios elementos, el resultado de la búsqueda se almacena en List<GridFSDBFile> |
3.3.3. Casos de uso
El motivo principal de usar GridFS se debe a superar la restricción de los 16MB de los documentos BSON.
Además, hay casos donde es preferible almacenar los archivos de vídeo y audio en una base de datos en vez de en el sistema de archivos, ya sea para almacenar metadatos de los archivos, acceder a ellos desde aplicaciones ajenos al sistemas de archivos o replicar el contenido para ofrecer una alta disponibilidad.
Otro caso importante es cuando tenemos contenido generado por el usuario como grandes informes o datos estáticos que no suelen cambiar y que cuestan mucho de generar. En vez de generarlos con cada petición, se pueden ejecutar una vez y almacenarlos como un documento. Cuando se detecta un cambio en el contenido estático, se vuelve a generar el informe en la próxima petición de los datos.
Si el sistema de archivos no siempre está disponible, también podemos evaluar GridFS como una alternativa viable. También podemos aprovechar que los fichero se almacenan en trozos y usar estos trozos para almacenar parte del archivo que interesa, como puede ser el contenido MD5 de los datos.
Si nos centramos en sus inconvenientes, tenemos que tener claro que hay pérdida de rendimiento respecto a acceder al sistema de archivos. Por ello, se recomienda crear una prueba de concepto en el sistema a desarrollar antes de implementar la solución.
Hay que tener en cuenta que GridFS almacena los datos en múltiples documentos, con lo que una actualización atómica no es posible. Si tenemos claro que el contenido es inferior a 16 MB, que es el caso de la mayoría de contenido generado por el usuario, podemos dejar de lado GridFS, y usar directamente documentos BSON los cuales aceptan datos binarios.
String recurso = "cartel300.png";
byte[] imagenBytes = leerDatosBinarios(recurso);
DBObject doc = new BasicDBObject("_id", 1);
doc.put("nombreFichero", recurso);
doc.put("tamanyo", imagenBytes.length);
doc.put("datos", imagenBytes);
coleccion.insert(doc);
byte[] leerDatosBinarios(String recurso) throws IOException {
InputStream in = Thread.currentThread().getContextClassLoader().getResourceAsStream(recurso);
if (in != null) {
int available = in.available();
byte[] bytes = new byte[available];
in.read(bytes);
return bytes;
} else {
throw new IllegalArgumentException("Recurso " + recurso + " no encontrado");
}
}3.4. Índices
Los índices son una parte importante de la gestión de bases de datos. Un índice en una base de datos es similar a un índice de un libro; permite saltar directamente a la parte del libro en vez de tener que pasar las páginas buscando el tema o la palabra que nos interesa.
En el caso de MongoDB, un índice es una estructura de datos que almacena información sobre los valor de determinados campos de los documentos de una colección. Esta estructura permite recorrer los datos y ordenarlos de manera muy rápida. Así pues, los índices se utilizan tanto al buscar un documento como al ordenar los datos de una consulta.
Para comprobar el impacto del uso de índices, vamos a empezar con un ejemplo para ver cómo de rápido puede hacerse una consulta que tiene un índice respecto a uno que no lo tiene.
Para analizar el plan de ejecución de una consulta, podemos emplear el método explain() (https://docs.mongodb.org/manual/reference/method/cursor.explain/) sobre un cursor:
> db.students.find({"name" : "Kaila Deibler"}).explain("executionStats")
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "expertojava.students",
"indexFilterSet" : false,
"parsedQuery" : {
"name" : { "$eq" : "Kaila Deibler" }
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"name" : { "$eq" : "Kaila Deibler" }
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 2,
"totalKeysExamined" : 0,
"totalDocsExamined" : 200,
"executionStages" : {
"stage" : "COLLSCAN",
"filter" : {
"name" : { "$eq" : "Kaila Deibler" }
},
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 204,
"advanced" : 2,
"needTime" : 199,
"needYield" : 2,
"saveState" : 2,
"restoreState" : 2,
"isEOF" : 1,
"invalidates" : 0,
"direction" : "forward",
"docsExamined" : 200
}
},
"serverInfo" : {
"host" : "MacBook-Air-de-Aitor.local",
"port" : 27017,
"version" : "3.2.1",
"gitVersion" : "a14d55980c2cdc565d4704a7e3ad37e4e535c1b2"
},
"ok" : 1
}El plan de ejecución devuelve mucha información (https://docs.mongodb.org/manual/reference/explain-results/), pero nos vamos a centrar en unos pocos atributos para analizar el resultado.
A grosso modo, podemos observar como el resultado se divide en dos partes:
-
queryPlanner: muestra información sobre la consulta, indicando el plan ganador enwinningPlan-
winningPlan.stage: muestra información de la acción realizada. Puede tomar los valores:-
COLLSCAN: escaneo completo de una colección -
IXSCAN: escaneo a partir de un índice -
FETCH: al recuperar documentos -
SHARD_MERGE: al fusionar resultados de las particiones
-
-
-
executionStats: muestra estadísticas de ejecución-
executionTimeMillis: tiempo empleado
-
Del resultado obtenido, se puede observar mediante la propiedad queryPlanner.winningPlan.stage que ha utilizado un COLLSCAN, lo que significa que se ha realizado un escaneo completo de toda la colección para encontrar los datos, lo que significa que no se ha usado ningún índice en la consulta. Esta consulta sólo devuelve un par de documentos (executionStats.nReturned) pero ha tenido que escanear los 200 existentes (executionStats.totalDocsExamined).
Cuando vamos a buscar un elemento, es mucho mas rápido hacer un findOne que find, porque mientras find recorre toda la colección, con findOne en cuanto encuentre un documento, el cursor se detendrá.
|
Por defecto, el campo _id esta indexado. Así pues, vamos a buscar el mismo documento de antes, pero ahora mediante el campo indexado:
> db.students.find({_id:30}).explain("executionStats")
{
"queryPlanner" : {
"plannerVersion" : 1,
...
"winningPlan" : {
"stage" : "IDHACK"
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 0,
"totalKeysExamined" : 1,
"totalDocsExamined" : 1,
"executionStages" : {
...
}
},
"serverInfo" : {
...
},
"ok" : 1
}Ahora MongoDB sólo ha escaneado el documento que ha devuelto ( executionStats.totalKeysExamined), y ha utilizado un índice para acceder al campo _id (valor IDHACK en winningPlan.stage). Al haber utilizado un índice, hemos evitado tener que mirar en más documentos. Esta consulta se ha realizado más rápidamente (y a mayor número de documentos más se nota la diferencia). Por supuesto, no siempre vamos a buscar por su _id, así que vamos a ver como crear nuevos índices.
Toda la información sobre el uso de índices con MongoDB se encuentra en http://docs.mongodb.org/manual/core/indexes/
3.4.1. Simples
Para crear un índice hemos de utilizar el método createIndex({atributo:orden})
Si queremos crear un índice sobre la propiedad name en orden ascendente haríamos lo siguiente:
> db.students.createIndex( {name:1} )
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}Si ahora volvemos a ejecutar la consulta por nombre, comprobaremos como ahora ya realiza una búsqueda directa (valor FETCH en winningPlan.stage) y que no ha tenido que recorrer todos los documentos.
> db.students.find({"name" : "Kaila Deibler"}).explain("executionStats")
{
"queryPlanner" : {
"plannerVersion" : 1,
...
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : { "name" : 1 },
"indexName" : "name_1",
"isMultiKey" : false,
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 1,
"direction" : "forward",
"indexBounds" : {
"name" : [
"[\"Kaila Deibler\", \"Kaila Deibler\"]"
]
}
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 2,
"totalKeysExamined" : 2,
"totalDocsExamined" : 2,
"executionStages" : {
...
}
},
"serverInfo" : {
...
},
"ok" : 1
}| Un aspecto a considerar de los índices es que aceleran mucho las búsquedas, pero ralentizan las inserciones/modificaciones y hace que la información ocupe más espacio en disco. Por ello, deberemos considerar añadir índices a las colecciones donde el número de lecturas sea mayor que el de escrituras. Si sucede al revés, el uso de índices puede provocar un deterioro en el rendimiento. |
El orden de los índices (1 para ascendente, -1 para descendente) no importa para un índice sencillo, pero si que tendrá un impacto en los índices compuestos cuando se utilizan para ordenar o con una condición de rango.
Por supuesto, podemos crear índices sobre propiedades que forman parte de un array. Así pues, podemos crear un índice sobre el tipo de calificación que tiene un estudiante mediante:
> db.students.createIndex( {scores.type:1} )Pero además también podemos crear un índice sobre todas las calificaciones, lo cual indexa cada elemento del array, con lo que podemos buscar por cualquier objeto del array. Este tipo de índices se conocen como multiclave:
> db.students.createIndex( {scores:1} )Toda la información relativa a los índices creados se almacenan en la colección system.indexes, la cual podremos consultar.
Además, también podemos obtener los índices de una determinada colección mediante el método getIndexes().
Finalmente, para borrar un índice emplearemos el método dropIndex(atributo).
Así pues, tenemos que algunas de las operaciones relacionadas con los índices más importantes son:
> db.system.indexes.find() // muestra los índices existentes
> db.students.getIndexes() // muestra los índices de la colección students
> db.students.dropIndex( {"name":1} ) // borra el índice que existe sobre la propiedad namePropiedades
Al crear un índice podemos pasarle algunas opciones como segundo parámetro, como puede ser:
-
unique:true: Permite crear índices que sólo permiten valores únicos en una propiedad. No puede haber valores repetidos y una vez creado no permitirá insertar valores duplicados.> db.students.createIndex( {students_id:1}, {unique:1} )El índice sobre
_ides único aunque al visualizarlo no nos diga que lo sea, ya que no permite que se inserten dos_idiguales. -
Si queremos añadir un índice sobre una propiedad que no aparece en todos los documentos, necesitamos crear un Sparse Index mediante
sparse:true, el cual se crea para el conjunto de claves que tienen valores.> db.students.createIndex( {size:1}, {sparse:1} )Si hacemos una consulta sobre una propiedad que tiene asociado un Sparse Index, nos van a aparecer menos resultados, ya que sólo mostrará aquellos que tengan valores, y no tendrá en cuenta los documentos que tengan dicho campo sin crear.
|
Autoevaluación
Suponemos que tenemos los siguientes documentos en una colección llamada 'people' con los siguientes documentos: Y hay un índice definido del siguiente modo: Si realizamos la siguiente consulta, ¿Qué documentos aparecerán y por qué? [1]
|
-
Finalmente, desde la versión 3.2, podemos emplear índices parciales, para indexar aquellos documentos que cumplen un criterio específico. Al indexar un subconjunto de los documentos de una colección, estos índices ocupan menos, y reducen el coste de almacenamiento y rendimiento a la hora de crearlo. Para ello, le pasaremos a la propiedad
partialFilterExpressionel criterio que debe cumplir el índice parcial.Por ejemplo, para indexar por tipo de calificación a aquellos estudiantes con una calificación superior a 95 haríamos:
> db.students.createIndex({"scores.type":1}, {partialFilterExpression:{"scores.score":{$gt:95}}} )Para utilizar este índice, la consulta debe realizarse por el campo del mismo, y cumplir con un subconjunto de la expresión de filtrado. Por ejemplo:
> db.students.find({"scores.type":"exam"}) // No emplea el índice, no utiliza el filtro > db.students.find({"scores.type":"exam", "scores.score":{$gt:90}} ) // No emplea el índice, ya que no cumple el filtr > db.students.find({"scores.type":"exam", "scores.score":{$gt:96}} ) // Si emplea el filtro
Más información sobre los índices parciales en https://docs.mongodb.org/manual/core/index-partial/
3.4.2. Compuestos
Si queremos aplicar un índice sobre más de una propiedad, podemos crear índices compuestos, indicando las propiedades separadas por coma:
> db.students.createIndex({"name":1, "scores.type":1})Es importante destacar que el orden de los índices importa, y mucho. Si hacemos una consulta que sólo utilice el atributo scores.type, este índice no se va a utilizar.
| No confundir los índices compuestos con hacer 2 o más índices sobre diferentes propiedades. |
Si creamos un índice sobre los campos (A,B,C), el índice se va a utilizar para las búsquedas sobre A, sobre la dupla (A,B) y sobre el trio (A,B,C). Es decir, los índices se usan con los subconjuntos por la izquierda (prefijos) de los índices compuestos.
Si tenemos varios índices candidatos a la hora de ejecutar, el optimizador de consultas de MongoDB los usará en paralelo y se quedará con el resultado del primero que termine. Más información en http://docs.mongodb.org/manual/core/query-plans/
3.4.3. Multiclave
Cuando se indexa una propiedad que es un array se crea un índice multiclave para todos los valores del array de todos los documentos. El uso de estos índices son lo que hacen que las consultas sobre documentos embebidos funcionen tan rápido.
> db.students.createIndex({"teachers":1})
> db.students.find({"teachers":{"$all":[1,3]}})Se pueden crear índices tanto en propiedades básicas, como en propiedades internas de un array, mediante la notación de .:
> db.students.createIndex({"addresses.phones":1})| Sólo se pueden crear índices compuestos multiclave cuando sólo una de las propiedades del índice compuesto es un array; es decir, no puede haber dos propiedades array en un índice compuesto. Hay que tener cuidado ya que no se va a quejar al crearlo, solo al insertar, porque no va a poder indexar arrays paralelos. |
3.4.4. Rendimiento
Por defecto, los índices se crean en foreground, de modo que al crear un índice se van a bloquear a todos los writers. Si queremos crearlos en background para no penalizar las escrituras (es más lento, de 2 a 5 veces) lo indicaremos con un segundo parámetro:
> db.students.createIndex({"twitter": 1}, {background:true})Más información sobre la creación en background en https://docs.mongodb.org/manual/core/index-creation/
Algunos de los operadores que no utilizan los índices eficientemente son los operadores $where, $nin y $exists. Cuando estos operadores se emplean en una consultar hay que tener en mente un posible cuelo de botella cuando el tamaño de los datos incremente.
Plan de ejecución
Al explicar los índices ya hemos visto que podemos obtener información sobre la operación realizada mediante el método .explain().
El atributo indexOnly me dice si toda la información que quiero recuperar se encuentra en el índice. Este atributo va a depender de los campos que quiera que me devuelva la consulta, si son un subconjunto del índice utilizado.
| Más información en http://docs.mongodb.org/manual/reference/method/cursor.explain/ |
Los índices tienen que caber en memoria. Si están en disco, pese a ser algorítmicamente mejores que no tener, al ser más grandes que la RAM disponible, no se obtienen beneficios por la penalización de la paginación.
Para averiguar el tamaño de los índices (en bytes):
> db.students.stats() // obtiene estadísticas de la colección
> db.students.totalIndexSize() // obtiene el tamaño del índice| Mucho cuidado con los índices multikeys porque crecen mucho y si el documento tiene que moverse en disco, el cambio supone tener que cambiar todos los puntos de índice del array. |
Aunque sea más responsabilidad de un DBA, los desarrolladores debemos saber si el índice va a caber en memoria. Si no van a caber es mejor no usarlos.
Si vemos que no usamos un índice o que su rendimiento es peor, podemos borrarlos con dropIndex.
> db.students.dropIndex('nombreDeíndice')Podemos obtener más información sobre el rendimiento de las consultas mediante su plan de ejecución en https://docs.mongodb.org/manual/tutorial/analyze-query-plan/
|
Autoevaluación
Hemos actualizado un documento con una clave llamada etiquetas que provoca que el documento tenga que moverse a disco. Supongamos que el documento contiene 100 etiquetas en él y que el array de etiquetas está indexada con un índice multiclave. ¿Cuantos puntos de índice tienen que actualizarse en el índice para acodomar el movimiento? [2] |
Hints
Si en algún momento queremos forzar el uso de un determinado índice al realizar una consulta, necesitaremos usar el método .hint({campo:1})
Si queremos que se utilice el índice asociado a la propiedad twitter:
> db.people.find({nombre:"Aitor Medrano",twitter:"aitormedrano"}).hint({twitter:1}})Si por algún motivo no queremos usar índices, le pasaremos el operador $natural al método hint().
> db.people.find({nombre:"Aitor Medrano",twitter:"aitormedrano"}).hint({$natural:1}})Si usamos un hint sobre un índice sparse y no hay documentos a devolver con dicho índice porque todos sus campos son nulos, la consulta no devolverá nada, aunque haya documentos que sin dicho índice si cumplen los criterios.
Hay que destacar que los operadores $gt, $lt, $ne … provocan un uso ineficiente de los índices, ya que la consulta tiene que recorrer toda la colección de índices.
Si hacemos una consulta sobre varios atributos y en uno de ellos usamos $gt, $lt o similar, es mejor hacer un hint sobre el resto de atributos que sí tienen una selección directa.
Por ejemplo, supongamos que en la coleccion de calificaciones quieseramos obtener los exámenes con un calificación comprendida entre 95 y 98.
> db.grades.find({ score:{$gt:95, $lte:98}, type:"exam" })Para esta consulta, suponiendo que tenemos un índice tanto en score como en type, sería conveniente hacer el hint sobre el type
> db.grades.find({ score:{$gt:95, $lte:98}, type:"exam" }).hint('type')|
Otros tipos de índices
|
3.5. Colecciones limitadas
Una colección limitada (capped collection) es una colección de tamaño fijo, donde se garantiza el orden natural de los datos, es decir, el orden en que se insertaron.
Una vez se llena la colección, se eliminan los datos más antiguos, y los datos más nuevos se añaden al final, de manera similar a un buffer circular, asegurando que el orden natural de la colección sigue el orden en el que se insertaron los registros.
Este tipo de colecciones se utilizan para logs y auto-guardado de información, ya que su rendimiento es muy alto para inserciones.
Se crean de manera explícita mediante el método createCollection, pasándole el tamaño en bytes de la colección. Por ejemplo, si queremos cerar una colección para auditar datos de 20 KB haríamos:
> db.createCollection("auditoria", {capped:true, size:20480})| Los documentos que se añaden a una colección limitada se pueden modifican, pero no pueden crecer en tamaño. Si sucede, la modificación fallará. Además, tampoco se pueden eliminar documentos de la colección. Para ello, hay que borrar toda la colección (drop) y volver a crearla. |
También podemos limitar el número de elementos que se pueden añadir a la colección mediante el parámetro max: en la creación de la colección. Sin embargo, hay que asegurarse de disponer de suficiente espacio en la colección para los elementos que queremos añadir. Si la colección se llena antes de que el número de elementos se alcance, se eliminará el elemento más antiguo de la colección.
Si retomamos el ejemplo anterior, pero fijamos su máximo a 100 elementos, crearíamos la colección del siguiente modo:
> db.createCollection("auditoria", {capped:true, size:20480, max:100})El shell de MongoDB ofrece la utilidad validate() para visualizar la cantidad de espacio utilizado por cada colección, ya sea limitada o no. Para comprobar el estado de la colección anterior haríamos:
> db.auditoria.validate()Si queremos consultar los datos de una colección limitada, por su idiosincracia, los resultados aparecerán en el orden de inserción. Si queremos obtenerlos en orden inverso, le tenemos que pasar el operador $natural al método sort():
> db.auditoria.find().sort({ $natural:-1 })Finalmente, si queremos averiguar si una colección es limitada, lo haremos mediante el método isCapped():
> db.auditoria.isCapped()
trueMás información en https://docs.mongodb.org/manual/core/capped-collections/
3.6. Profiling
Si arrancamos el demonio con la opción --rest lanzará un servidor HTTP que escucha peticiones en el puerto 28017. Este servidor captura peticiones REST que permiten realizar consultas sobre la información administrativa de la base de datos.
Así pues, si abrimos el navegador y accedemos a http://localhost:28017 obtendremos algo similar a esto:
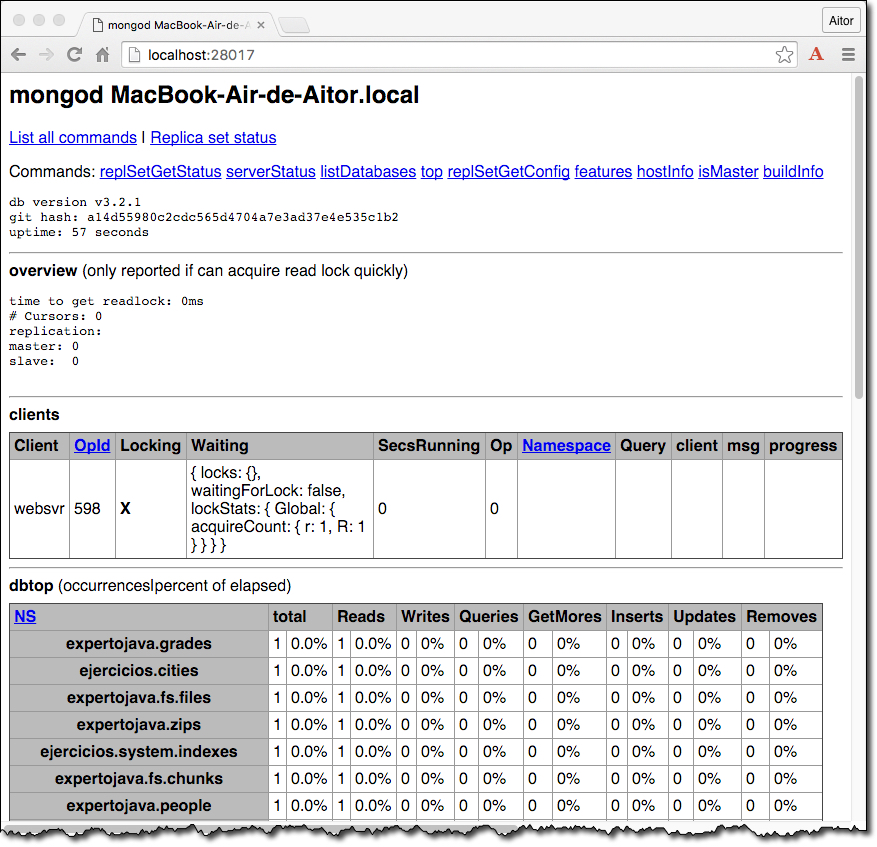
Más información en http://docs.mongodb.org/ecosystem/tools/http-interfaces
Además, MongoDB trae integradas varias herramientas para el control del rendimiento.
Por ejemplo, la colección db.system.profile auditará las consultas ejecutadas. Podemos indicar el nivel de las consultas a auditar mediante tres niveles: 0 (ninguna), 1 (consultas lentas), 2 (todas las consultas)
Si queremos que se auditen todas las consultas, lo indicaremos del siguiente modo:
> db.setProfilingLevel(2)El método setProfilingLevel() también admite un segundo parámetro para indicar el numero mínimo de milisegundos de las consultas para ser auditadas.
| Por defecto, MongoDB automáticamente escribe en el log las consultas que tardan más de 100ms. |
Si queremos indicar estas propiedades al arrancar el demonio, le pasaremos los parámetros --profile y/o --slowms:
mongod --profile=1 --slowms=15Si en algún momento queremos consultar tanto el nivel como el estado del profiling, podemos utilizar los métodos db.getProfilingLevel() y db.getProfilingStatus().
Sobre los datos auditados, podemos hacer find sobre db.system.profile y filtrar por los campos mostrados:
> db.system.profile.find({ millis : { $gt : 1000 } }).sort({ts : -1})
> db.system.profile.find().limit(10).sort( { ts : -1 } ).pretty()Dentro de estas consultas algunos campos significativos son:
-
op: tipo de operación, ya seacommand,query,insert, … -
millis: tiempo empleado en la operación -
ts: timestamp de la operación
Podéis consultar todos los campos disponibles en http://docs.mongodb.org/manual/reference/database-profiler/
Otras herramientas para controlar el rendimiento que se ejecutan en un terminal, son:
-
mongotop → similar a la herramienta
topde UNIX, muestra el tiempo empleado por MongoDB en las diferentes colecciones, indicando tanto el tiempo empleado en lectura como en escrituras. Para ello, si queremos se ejecute cada tres segundos, en un terminal:
mongotop 3
mongotopMás información en : http://docs.mongodb.org/manual/reference/program/mongotop/
-
mongostat → muestra el número de operaciones por cada tipo que se realizan por segundo a nivel de servidor, lo que nos da una instantánea de los que está haciendo el servidor.
mongostatUna buena columna a vigilar es idx miss %, la cual muestra los índices perdidos, es decir, aquellas consultas que han causado paginación y en vez de obtener los datos de memoria han tenido que acceder a disco.
Más información en : http://docs.mongodb.org/manual/reference/program/mongostat/
3.7. Ejercicios
3.7.1. (1.5 puntos) Ejercicio 31. Diseñando el esquema
Vamos a realizar el modelo de datos documental de una tienda online que comercializa productos de bricolaje. Para ello, nos interesa almacenar datos de estos productos (nombre, descripción, medidas, peso, pvp, …), y de los pedidos que realizan los clientes. Una vez formalizado un pedido, se le enviará vía mensajería urgente el pedido al domicilio del cliente.
De los clientes nos interesa almacenar sus datos personales, datos de contacto (tanto emails como teléfonos), así como las diferentes direcciones que pueda tener asociadas.
Del pedido, además de la fecha de realización y de los productos que incluye, el precio total así como la dirección de envío.
Para ello, en una base de datos denominada bricomongo, se deben incluir las colecciones necesarias. Cada una de las colecciones debe contener tres o más documentos.
Una vez diseñada, creada y tras insertar los datos, se han de exportar las diferentes colecciones mediante mongoexport en archivos denominados ej31-nombreColeccion.json, sustituyendo nombreColeccion por el nombre de las diferentes colecciones que hayas diseñado. Finalmente, se debe exportar toda la base de datos mediante mongodump en un archivo denominado ej31-dump
3.7.2. (0.75 puntos) Ejercicio 32. Índices
En este ejercicio vamos optimizar la base de datos de ejercicios importada en la primera sesión.
Las consultas que más se realizan sobre la colección cities son:
-
Recuperar una ciudad por su nombre
-
Recuperar las 5 ciudades más pobladas de un determinado país
-
Recuperar las 3 ciudades menos pobladas de una zona horaria.
Se pide crear los índices adecuados para que estas consultas se ejecuten de manera óptima.
Por lo tanto, el archivo ej32.txt debe contener:
-
los comandos empleados para comprobar los planes de ejecución antes y después de crear los índices necesarios
-
comandos necesarios para crear los índices elegidos
-
una explicación de la elección del tipo de índice elegido en cada caso.
-
resultado de obtener todos los índices de la colección
citiesuna vez creados todos los índices elegidos -
tamaño de los índices y requisitos de hardware del servidor necesarios para dar soporte a estos índices