4. Agregaciones y Escalabilidad
4.1. Agregaciones
Para poder agrupar datos y realizar cálculos sobre éstos, MongoDB ofrece diferentes alternativas:
1.- Mediante operaciones Map-reduce con operación mapreduce() (http://docs.mongodb.org/manual/core/map-reduce/)
2.- Mediante operaciones de agrupación sencilla, como pueden ser las operaciones count(), distinct() o group(). Esta última operación permite realizar una serie de cálculos sobre elementos filtrado, de manera similar a Map-reduce, pero más sencillo y limitado, obteniendo un array de elementos agrupados.
La firma completa es group({ key, reduce, initial }) donde sus parámetros definen:
-
key: atributo por el que se van a agrupar los datos -
initial: define un valor base para cada grupo de resultados. Normalmente se inicializa -
reduce: función que agrupa los elementos similar. Recibe dos parámetros, el documento actual (item) sobre el cual se itera, y el objeto contador agregado (prev).
Por ejemplo, si quisieramos saber cuantas personas tienen diferente cantidad de hijos y cuantos hay de cada tipo haríamos:
> db.people.group( {
key: { hijos: true },
reduce: function ( item, prev ) {
prev.total += 1;
},
initial: { total : 0 }
} )Con lo que obtendríamos (dependiendo de los datos) que hay dos personas que tienen 2 hijos, y una persona que no tiene el atributo hijo definido:
[ { "hijos" : 2, "total" : 2 },
{ "hijos" : null, "total" : 1 } ]
Hay que destacar que la función group() no funciona en entornos sharded, donde habría que utilizar la función mapreduce() o el framework de agregación.
|
Podemos ver un ejemplo sencillo en http://docs.mongodb.org/manual/core/single-purpose-aggregation/#group y más información en http://docs.mongodb.org/manual/reference/method/db.collection.group
2.- Mediante el uso del Aggregation Framework, basado en el uso de pipelines, el cual permite realizar diversas operaciones sobre los datos. Este framework forma parte de MongoDB desde la versión 2.2, ofrece más posibilidades que la operación group y además permite su uso con sharding.
Para ello, a partir de una colección, mediante el método aggregate le pasaremos un array con las fases a realizar:
db.productos.aggregate([
{$group:
{_id:"$fabricante", numProductos:{$sum:1}}
},
{$sort: {numProductos:-1}}
])4.2. Pipeline de agregación
Las agregaciones usan un pipeline, conocido como Aggregation Pipeline, de ahí el uso de un array con [ ] donde cada elemento es una fase del pipeline, de modo que la salida de una fase es la entrada de la siguiente:
db.coleccion.aggregate([op1, op2, ... opN])| El resultado del pipeline es un documento y por lo tanto está sujeto a la restricción de BSON, que limita su tamaño a 16MB |
En la siguiente imagen se resumen los pasos de una agrupación donde primero se eligen los elementos que vamos a agrupar mediante $match y posteriormente se agrupan con $group para hacer $sum sobre el total:
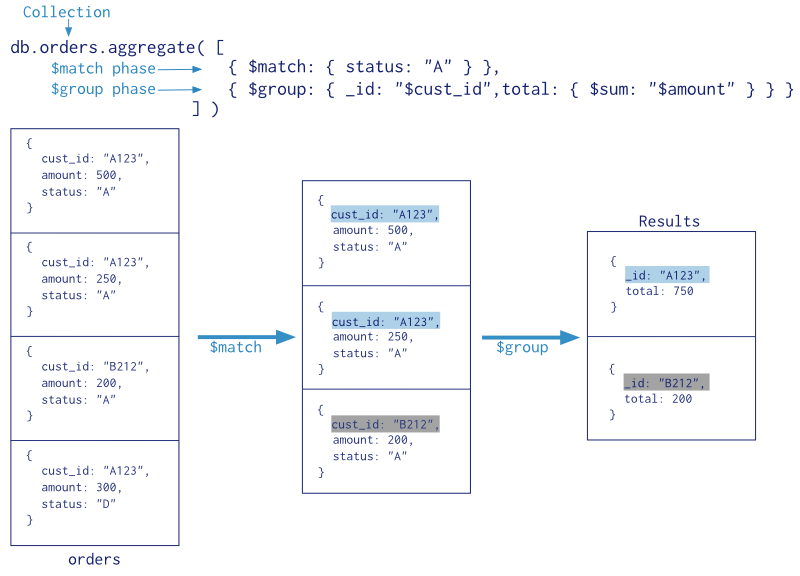
$match y $group4.2.1. Operadores del pipeline
Antes de nada destacar que las fases se pueden repetir, por lo que una consulta puede repetir operadores.
Más información en: http://docs.mongodb.org/manual/reference/operator/aggregation/
A continuación vamos a estudiar todos estos operadores:
| Operador | Descripción | Cardinalidad |
|---|---|---|
$project |
Proyección de campos, es decir, propiedades en las que estamos interesados. También nos permite modificar un documento, o crear un subdocumento (reshape) |
1:1 |
$match |
Filtrado de campos, similar a where |
N:1 |
$group |
Para agrupar los datos, similar a group by |
N:1 |
$sort |
Ordenar |
1:1 |
$skip |
Saltar |
N:1 |
$limit |
Limitar los resultados |
N:1 |
$unwind |
Separa los datos que hay dentro de un array |
1:N |
4.2.2. $group
Agrupa los documentos con el propósito de calcular valores agregrados de una colección de documentos. Por ejemplo, podemos usar $group para calcular la media de páginas visitas de manera diaria.
| La salida de $group esta desordenada |
La salida de $group depende de como se definan los grupos. Se empieza especificando un identificador (por ejemplo, un campo _id) para el grupo que creamos con el pipeline. Para este campo _id, podemos especificar varias expresiones, incluyendo un único campo proveniente de un documento del pipeline, un valor calculado de una fase anterior, un documento con muchos campos y otras expresiones válidas, tales como constantes o campos de subdocumentos. También podemos usar operadores de $project para el campo _id.
Cuando referenciemos al valor de un campo lo haremos poniendo entre comillas un $ delante del nombre del campo. Así pues, para referenciar al fabricante de un producto lo haremos mediante $fabricante.
> db.productos.aggregate([{$group:
{
_id: "$fabricante",
total: { $sum:1 }
}
}])
{ "_id" : "Sony", "total" : 1 }
{ "_id" : "Amazon", "total" : 2 }
{ "_id" : "Google", "total" : 1 }
{ "_id" : "Samsung", "total" : 2 }
{ "_id" : "Apple", "total" : 4 }Si lo que queremos es que el valor del identificador contenga un objeto, lo podemos hacer asociandolo como valor:
> db.productos.aggregate([{$group:
{
_id: { "empresa": "$fabricante" },
total: { $sum:1 }
}
}])
{ "_id" : { "empresa" : "Amazon" }, "total" : 2 }
{ "_id" : { "empresa" : "Sony" }, "total" : 1 }
{ "_id" : { "empresa" : "Samsung" }, "total" : 2 }
{ "_id" : { "empresa" : "Google" }, "total" : 1 }
{ "_id" : { "empresa" : "Apple" }, "total" : 4 }También podemos agrupar más de un atributo, de tal modo que tengamos un _id compuesto. Por ejemplo:
> db.productos.aggregate([{$group:
{
_id: {
"empresa": "$fabricante",
"tipo" : "$categoria" },
total: {$sum:1}
}
}])
{ "_id" : { "empresa" : "Amazon", "tipo" : "Tablets" }, "total" : 2 }
{ "_id" : { "empresa" : "Google", "tipo" : "Tablets" }, "total" : 1 }
{ "_id" : { "empresa" : "Apple", "tipo" : "Portátiles" }, "total" : 1 }
{ "_id" : { "empresa" : "Sony", "tipo" : "Portátiles" }, "total" : 1 }
{ "_id" : { "empresa" : "Samsung", "tipo" : "Tablets" }, "total" : 1 }
{ "_id" : { "empresa" : "Samsung", "tipo" : "Smartphones" }, "total" : 1 }
{ "_id" : { "empresa" : "Apple", "tipo" : "Tablets" }, "total" : 3 }
Cada expresión de $group debe especificar un campo _id.
|
Además del campo _id, la expresión $group puede incluir campos calculados. Estos otros campos deben utilizar uno de los siguientes acumuladores.
| Nombre | Descripción |
|---|---|
$addToSet |
Devuelve un array con todos los valores únicos para los campos seleccionados entre cada documento del grupo (sin repeticiones) |
$first |
Devuelve el primer valor del grupo. Se suele usar después de ordenar. |
$last |
Devuelve el último valor del grupo. Se suele usar después de ordenar. |
$max |
Devuelve el mayor valor de un grupo |
$min |
Devuelve el menor valor de un grupo. |
$avg |
Devuelve el promedio de todos los valores de un grupo |
$push |
Devuelve un array con todos los valores del campo seleccionado entre cada documento del grupo (puede haber repeticiones) |
$sum |
Devuelve la suma de todos los valores del grupo |
A continuación vamos a ver ejemplos de cada uno de estos acumuladores.
$sum
El operador $sum acumula los valores y devuelve la suma.
Por ejemplo, para obtener el montante total de los prodyctos agrupados por fabricante, haríamos:
$sum> db.productos.aggregate([{
$group: {
_id: {
"empresa":"$fabricante"
},
totalPrecio: {$sum:"$precio"}
}
}])
{ "_id" : { "empresa" : "Amazon" }, "totalPrecio" : 328 }
{ "_id" : { "empresa" : "Sony" }, "totalPrecio" : 499 }
{ "_id" : { "empresa" : "Samsung" }, "totalPrecio" : 1014.98 }
{ "_id" : { "empresa" : "Google" }, "totalPrecio" : 199 }
{ "_id" : { "empresa" : "Apple" }, "totalPrecio" : 2296 }$avg
Mediante $avg podemos obtener el promedio de los valores de un campo numérico.
Por ejemplo, para obtener el precio medio de los productos agrupados por categoría, haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"categoria":"$categoria"
},
precioMedio: {$avg:"$precio"}
}
}])
{ "_id" : { "categoria" : "Portátiles" }, "precioMedio" : 499 }
{ "_id" : { "categoria" : "Smartphones" }, "precioMedio" : 563.99 }
{ "_id" : { "categoria" : "Tablets" }, "precioMedio" : 396.4271428571428 }$addToSet
Mediante addToSet obtendremos un array con todos los valores únicos para los campos seleccionados entre cada documento del grupo (sin repeticiones).
Por ejemplo, para obtener para cada empresa las categorías en las que tienen productos, haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"fabricante":"$fabricante"
},
categorias: {$addToSet:"$categoria"}
}
}])
{ "_id" : { "fabricante" : "Amazon" }, "categorias" : [ "Tablets" ] }
{ "_id" : { "fabricante" : "Sony" }, "categorias" : [ "Portátiles" ] }
{ "_id" : { "fabricante" : "Samsung" }, "categorias" : [ "Tablets", "Smartphones" ] }
{ "_id" : { "fabricante" : "Google" }, "categorias" : [ "Tablets" ] }
{ "_id" : { "fabricante" : "Apple" }, "categorias" : [ "Portátiles", "Tablets" ] }$push
Mediante $push también obtendremos un array con todos los valores para los campos seleccionados entre cada documento del grupo, pero con repeticiones. Es decir, funciona de manera similar a $addToSet pero permitiendo elementos repetidos.
Por ello, si reescribimos la consulta anterior pero haciendo uso de $push obtendremos categorías repetidas:
> db.productos.aggregate([{
$group: {
_id: {
"empresa":"$fabricante"
},
categorias: {$push:"$categoria"}
}
}])
{ "_id" : {"empresa" : "Amazon"}, "categorias" : ["Tablets", "Tablets"] }
{ "_id" : {"empresa" : "Sony"}, "categorias" : ["Portátiles"] }
{ "_id" : {"empresa" : "Samsung"}, "categorias" : ["Smartphones", "Tablets"] }
{ "_id" : {"empresa" : "Google"}, "categorias" : ["Tablets"] }
{ "_id" : {"empresa" : "Apple"}, "categorias" : ["Tablets", "Tablets", "Tablets", "Portátiles"] }$max y $min
Los operadores $max y $min permiten obtener el mayor y el menor valor, respectivamente, del campo por el que se agrupan los documentos.
Por ejemplo, para obtener el precio del producto más caro que tiene cada empresa haríamos:
> db.productos.aggregate([{
$group: {
_id: {
"empresa":"$fabricante"
},
precioMaximo: {$max:"$precio"},
precioMinimo: {$min:"$precio"},
}
}])
{ "_id" : { "empresa" : "Amazon" }, "precioMaximo" : 199, "precioMinimo" : 129 }
{ "_id" : { "empresa" : "Sony" }, "precioMaximo" : 499, "precioMinimo" : 499 }
{ "_id" : { "empresa" : "Samsung" }, "precioMaximo" : 563.99, "precioMinimo" : 450.99 }
{ "_id" : { "empresa" : "Google" }, "precioMaximo" : 199, "precioMinimo" : 199 }
{ "_id" : { "empresa" : "Apple" }, "precioMaximo" : 699, "precioMinimo" : 499 }Doble $group
Si queremos obtener el resultado de una agrupación podemos aplicar el operador $group sobre otro $group.
Por ejemplo, para obtener el precio medio de los precios medios de los tipos de producto por empresa haríamos:
> db.productos.aggregate([
{$group: {
_id: {
"empresa":"$fabricante",
"categoria":"$categoria"
},
precioMedio: {$avg:"$precio"} (1)
}
},
{$group: {
_id: "$_id.empresa",
precioMedio: {$avg: "$precioMedio"} (2)
}
}
])
{ "_id" : "Samsung", "precioMedio" : 507.49 }
{ "_id" : "Sony", "precioMedio" : 499 }
{ "_id" : "Apple", "precioMedio" : 549 }
{ "_id" : "Google", "precioMedio" : 199 }
{ "_id" : "Amazon", "precioMedio" : 164 }| 1 | Precio medio por empresa y categoría |
| 2 | Precio medio por empresa en base al precio medio anterior |
$first y $last
Estos operadores devuelven el valor resultante de aplicar la expresión al primer/último elemento de un grupo de elementos que comparten el mismo grupo por clave.
Por ejemplo, para obtener para cada empresa, cual es el tipo de producto que más tiene y la cantidad de dicho tipo haríamos:
> db.productos.aggregate([
{$group: { (1)
_id: {
"empresa": "$fabricante",
"tipo" : "$categoria" },
total: {$sum:1}
}
},
{$sort: {"total":-1}},
{$group: {
_id:"$_id.empresa",
producto: {$first: "$_id.tipo" (2)
},
cantidad: {$first:"$total"}
}
}
])
{ "_id" : "Samsung", "producto" : "Tablets", "cantidad" : 1 }
{ "_id" : "Sony", "producto" : "Portátiles", "cantidad" : 1 }
{ "_id" : "Amazon", "producto" : "Tablets", "cantidad" : 2 }
{ "_id" : "Google", "producto" : "Tablets", "cantidad" : 1 }
{ "_id" : "Apple", "producto" : "Tablets", "cantidad" : 3 }| 1 | Agrupamos por empresa y categoría de producto |
| 2 | Al agrupar por empresa, elegimos la categoría producto que tiene más unidades |
4.2.3. $project
Si queremos realizar una proyección sobre el conjunto de resultados y quedarnos con un subconjunto de los campos usaremos el operador $project. Como resultado obtendremos el mismo número de documentos, y en el orden indicado en la proyección.
La proyección dentro del framework de agregación es mucho más potente que dentro de las consultas normales. Se emplea para:
-
renombrar campos.
-
introducir campos calculados en el documento resultante, mediante
$add,$substract,$multiply,$divideo$mod -
transformar campos a mayúsculas
$toUppero minúsculas$toLower, concatenar campos mediante$concatu obtener subcadenas con$substr. -
transformar campos en base a valores obtenidos a partir de una condición mediante expresiones lógicas con los operadores de comparación vistos en las consultas.
> db.productos.aggregate([
{$project:
{
_id:0,
'empresa': {$toUpper:"$fabricante"}, (1)
'detalles': { (2)
'categoria': "$categoria",
'precio': {"$multiply": ["$precio", 1.1]} (3)
},
'elemento':'$nombre' (4)
}
}
])
{ "empresa" : "APPLE", "detalles" : { "categoria" : "Tablets", "precio" : 548.9000000000001 }, "elemento" : "iPad 16GB Wifi" }
{ "empresa" : "APPLE", "detalles" : { "categoria" : "Tablets", "precio" : 658.9000000000001 }, "elemento" : "iPad 32GB Wifi" }| 1 | Transforma un campo y lo pasa a mayúsculas |
| 2 | Crea un documento anidado |
| 3 | Incrementa el precio el 10% |
| 4 | Renombra el campo |
Más información en http://docs.mongodb.org/manual/reference/operator/aggregation/project/
4.2.4. $match
Se utiliza principalmente para filtrar los documentos que pasarán a la siguiente etapa del pipeline o a la salida final.
Por ejemplo, para seleccionar sólo las tabletas haríamos:
> db.productos.aggregate([{$match:{categoria:"Tablets"}}])Aparte de igualar un valor a un campo, podemos emplear los operadores usuales de consulta, como $gt, $lt, $in, etc…
Se recomienda poner el operador match al principio del pipeline para limitar los documentos a procesar en siguientess fases. Si usamos este operador como primera fase podremos hacer uso de los indices de la colección de una manera eficiente.
Así pues, para obtener la cantidad de Tablets de menos de 500 euros haríamos:
> db.productos.aggregate([
{$match:
{categoria:"Tablets",
precio: {$lt: 500}}},
{$group:
{_id: {"empresa":"$fabricante"},
cantidad: {$sum:1}}
}]
)
{ "_id" : { "empresa" : "Amazon" }, "cantidad" : 2 }
{ "_id" : { "empresa" : "Samsung" }, "cantidad" : 1 }
{ "_id" : { "empresa" : "Google" }, "cantidad" : 1 }
{ "_id" : { "empresa" : "Apple" }, "cantidad" : 1 }Más información en http://docs.mongodb.org/manual/reference/operator/aggregation/match/
4.2.5. $sort
El operador $sort ordena los documentos recibidos por el campo y el orden indicado por la expresión indicada al pipeline.
Por ejemplo, para ordenar los productos por precio descendentemente haríamos:
> db.productos.aggregate({$sort:{precio:-1}})
El operador $sort ordena los datos en memoria, por lo que hay que tener cuidado con el tamaño de los datos. Por ello, se emplea en las últimas fases del pipeline, cuando el conjunto de resultados es el menor posible.
|
Si retomamos el ejemplo anterior, y ordenamos los datos por el precio total tenemos:
> db.productos.aggregate([
{$match:{categoria:"Tablets"}},
{$group:
{_id: {"empresa":"$fabricante"},
totalPrecio: {$sum:"$precio"}}
},
{$sort:{totalPrecio:-1}} (1)
])
{ "_id" : { "empresa" : "Apple" }, "totalPrecio" : 1797 }
{ "_id" : { "empresa" : "Samsung" }, "totalPrecio" : 450.99 }
{ "_id" : { "empresa" : "Amazon" }, "totalPrecio" : 328 }
{ "_id" : { "empresa" : "Google" }, "totalPrecio" : 199 }| 1 | Al ordenar los datos, referenciamos al campo que hemos creado en la fase de $group |
Más información en http://docs.mongodb.org/manual/reference/operator/aggregation/sort/
4.2.6. $skip y $limit
El operador $limit únicamente limita el número de documentos que pasan a través del pipeline.
El operador recibe un número como parámetro:
> db.productos.aggregate([{$limit:3}])Este operador no modifica los documentos, sólo restringe quien pasa a la siguiente fase.
De manera similar, con el operador $skip, saltamos un número determinado de documentos:
> db.productos.aggregate([{$skip:3}])El orden en el que empleemos estos operadores importa, y mucho, ya que no es lo mismo saltar y luego limitar, donde la cantidad de elementos la fija $limit:
> db.productos.aggregate([{$skip:2},{$limit:4}])
{ "_id" : ObjectId("54ffff889836d613eee9a6e7"), "nombre" : "iPad 64GB Wifi", "categoria" : "Tablets", "fabricante" : "Apple", "precio" : 699 }
{ "_id" : ObjectId("54ffff889836d613eee9a6e8"), "nombre" : "Galaxy S3", "categoria" : "Smartphones", "fabricante" : "Samsung", "precio" : 563.99 }
{ "_id" : ObjectId("54ffff889836d613eee9a6e9"), "nombre" : "Galaxy Tab 10", "categoria" : "Tablets", "fabricante" : "Samsung", "precio" : 450.99 }
{ "_id" : ObjectId("54ffff889836d613eee9a6ea"), "nombre" : "Vaio", "categoria" : "Portátiles", "fabricante" : "Sony", "precio" : 499 }En cambio, si primero limitamos y luego saltamos, la cantidad de elementos se obtiene de la diferencia entre el límite y el salto:
> db.productos.aggregate([{$limit:4},{$skip:2}])
{ "_id" : ObjectId("54ffff889836d613eee9a6e7"), "nombre" : "iPad 64GB Wifi", "categoria" : "Tablets", "fabricante" : "Apple", "precio" : 699 }
{ "_id" : ObjectId("54ffff889836d613eee9a6e8"), "nombre" : "Galaxy S3", "categoria" : "Smartphones", "fabricante" : "Samsung", "precio" : 563.99 }4.2.7. $unwind
Este operador es muy interesante y se utiliza solo con operadores array. Al usarlo con un campo array de tamaño N en un documento, lo transforma en N documentos con el campo tomando el valor individual de cada uno de los elementos del array.
Si retomamos el ejemplo de la segunda sesión donde actualizabamos una colección de enlaces, teníamos un enlace con la siguiente información:
> db.enlaces.findOne()
{
"_id" : ObjectId("54f9769212b1897ae84190cf"),
"titulo" : "www.google.es",
"tags" : [
"mapas",
"videos",
"blog",
"calendario",
"email",
"mapas"
]
}Podemos observar como el campo tags contiene 6 valores dentro del array (con un valor repetido). A continuación vamos a desenrollar el array:
> db.enlaces.aggregate(
{$match:{titulo:"www.google.es"}},
{$unwind:"$tags"})
{ "_id" : ObjectId("54f9769212b1897ae84190cf"), "titulo" : "www.google.es", "tags" : "mapas" }
{ "_id" : ObjectId("54f9769212b1897ae84190cf"), "titulo" : "www.google.es", "tags" : "videos" }
{ "_id" : ObjectId("54f9769212b1897ae84190cf"), "titulo" : "www.google.es", "tags" : "blog" }
{ "_id" : ObjectId("54f9769212b1897ae84190cf"), "titulo" : "www.google.es", "tags" : "calendario" }
{ "_id" : ObjectId("54f9769212b1897ae84190cf"), "titulo" : "www.google.es", "tags" : "email" }
{ "_id" : ObjectId("54f9769212b1897ae84190cf"), "titulo" : "www.google.es", "tags" : "mapas" }Así pues hemos obtenido 6 documentos con el mismo _id y titulo, es decir, un documento por elemento del array.
De este modo, podemos realizar consultas que sumen/cuenten los elementos del array. Por ejemplo, si queremos obtener las 3 etiquetas que más aparecen en todos los enlaces haríamos:
> db.enlaces.aggregate([
{"$unwind":"$tags"},
{"$group":
{"_id":"$tags",
"total":{$sum:1}
}
},
{"$sort":{"total":-1}},
{"$limit": 3}
])
{ "_id" : "mapas", "total" : 3 }
{ "_id" : "email", "total" : 2 }
{ "_id" : "calendario", "total" : 1 }Doble $unwind
Si trabajamos con documentos que tienen varios arrays, podemos necesitar desenrollar los dos array. Al hacer un doble unwind se crea un producto cartesiano entre los elementos de los 2 arrays.
Supongamos que tenemos los datos del siguiente inventario de ropa:
> db.inventario.drop();
> db.inventario.insert({'nombre':"Camiseta", 'tallas':["S", "M", "L"], 'colores':['azul', 'blanco', 'naranja', 'rojo']})
> db.inventario.insert({'nombre':"Jersey", 'tallas':["S", "M", "L", "XL"], 'colores':['azul', 'negro', 'naranja', 'rojo']})
> db.inventario.insert({'nombre':"Pantalones", 'tallas':["32x32", "32x30", "36x32"], 'colores':['azul', 'blanco', 'naranja', 'negro']})Para obtener un listado de cantidad de pares talla/color haríamos:
> db.inventario.aggregate([
{$unwind: "$tallas"},
{$unwind: "$colores"},
{$group:
{ '_id': {'talla': '$tallas', 'color': '$colores'},
'total' : {'$sum': 1}
}
}
])
{ "_id" : { "talla" : "XL", "color" : "rojo" }, "total" : 1 }
{ "_id" : { "talla" : "XL", "color" : "negro" }, "total" : 1 }
{ "_id" : { "talla" : "L", "color" : "negro" }, "total" : 1 }
{ "_id" : { "talla" : "M", "color" : "negro" }, "total" : 1 }
...4.2.8. De SQL al Pipeline de agregaciones
Ya hemos visto que el pipeline ofrece operadores para realizar la misma funcionalidad de agrupación que ofrece SQL.
Si relacionamos los comandos SQL con el pipeline de agregaciones tenemos las siguientes equivalencias:
| SQL | Pipeline de Agregaciones |
|---|---|
WHERE |
|
GROUP BY |
|
HAVING |
|
SELECT |
|
ORDER BY |
|
LIMIT |
|
SUM() |
|
COUNT() |
|
Podemos encontrar ejemplos de consultas SQL transformadas al pipeline en http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
4.2.9. Limitaciones
Hay que tener en cuenta las siguiente limitaciones:
-
En versiones anteriores a la 2.6, el pipeline devolvía en cada fase un objeto BSON, y por tanto, el resultado estaba limitado a 16MB
-
Las fases tienen un límite de 100MB en memoría. Si una fase excede dicho límite, se producirá un error. En este caso, hay que habilitar el uso de disco mediante
allowDiskUseen las opciones de la agregación. Más información en http://docs.mongodb.org/manual/reference/method/db.collection.aggregate
4.3. Agregaciones con Java
Para realizar agregaciones mediante Java emplearemos el método aggregate(List <DBObject>) el cual accepta una lista con el pipeline de la consulta.
Vamos a traducir la siguiente consulta:
> db.productos.aggregate([
{$match:{categoria:"Tablets"}},
{$group:
{_id: {"empresa":"$fabricante"},
totalPrecio: {$sum:"$precio"}}
},
{$sort:{totalPrecio:-1}}
])Así pues, una vez conectados a la base de datos correspondiente y a la colección productos, vamos a crear tres objetos (uno por cada fase), y se los pasaremos como una lista al método aggregate():
DBObject match = new BasicDBObject("$match", new BasicDBObject("categoria", "Tablets"));
DBObject group = new BasicDBObject("$group",
new BasicDBObject("_id", new BasicDBObject("empresa", "$fabricante"))
.append("totalPrecio", new BasicDBObject("$sum", "$precio")));
DBObject sort = new BasicDBObject("$sort", new BasicDBObject("totaPrecio", -1));
AggregationOutput output = coleccion.aggregate(Arrays.asList(match, group, sort)); (1)
Iterable<DBObject> datos = output.results();
for (DBObject doc : datos) { (2)
System.out.println(doc);
}| 1 | Creamos una lista a partir de los DBObject |
| 2 | Recorremos el conjunto de datos |
El resultado es un objeto AggregationOutput, el cual contiene el método results() que nos devuelve un iterador el cual podemos recorrer.
4.4. Replicación
Un aspecto muy importante de MongoDB es que soporta la replicación de los datos de forma nativa mediante el uso de conjuntos de réplicas.
4.4.1. Conjunto de réplicas
En MongoDB se replican los datos mediante un conjunto de réplicas. Un Conjunto de Réplicas (Replica Set) es un grupo de servidores (nodos mongod) donde hay uno que ejerce la función de primario y por tanto recibe las peticiones de los clientes, y el resto de servidores hace de secundarios, manteniendo copias de los datos del primario.
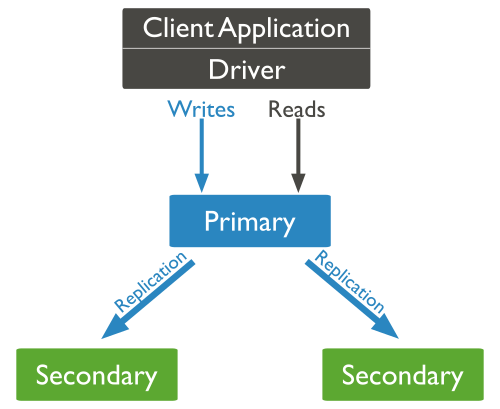
Si el nodo primario se cae, los secundarios eligen un nuevo primario entre ellos mismos, en un proceso que se conoce como votación. La aplicación se conectará al nuevo primario de manera transparente. Cuando el antiguo nodo primario vuelva en sí, será un nuevo nodo secundario.
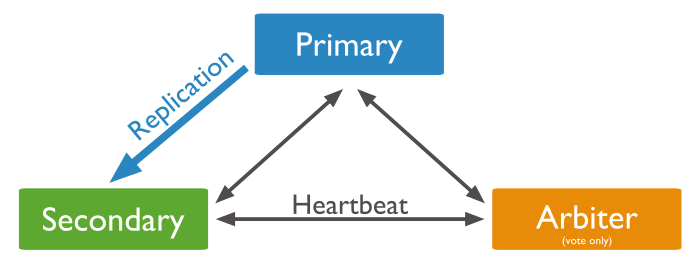
Al usar replicación, si un servidor se cae, siempre vamos a poder obtener los datos a partir de otros servidores del conjunto. Si los datos de un servidor se dañan o son inaccesibles, podemos crear una nueva copia desde uno de los miembros del conjunto.
4.4.2. Elementos de un conjunto de réplicas
Los tipos de nodos que podemos encontrar en un conjunto de réplica son:
-
Regular: Es el tipo de nodo más común.
-
Primario: Acepta todas las operaciones de escritura de los clientes. Cada conjunto de réplicas tendrá sólo un primario, y como sólo un miembro acepta operaciones de escritura, ofrece consitencia estricta para todas las lecturas realizadas desde él.
-
Secundario: Los secundarios replican el oplog primario y aplican las operaciones a sus conjuntos de datos. De este modo, los nodos secundarios son un espejo del primario. Si el primario deja de estar disponible, el conjunto de réplica elegirá a un secundario para que sea el nuevo primario, mediante un proceso de votación.
Por defecto, los clientes realizan las lecturas desde el nodo primario. Sin embargo, los clientes pueden indicar que quieren realizar lecturas desde los nodos secundarios.
Es posible que al realizar lecturas de un nodo secundario la información que se obtenga no refleje el estado del nodo primario.
-
-
Árbitro: se emplea sólo para votar. No contiene copia de los datos y no se puede convertir en primario. Los conjuntos de réplica pueden tener árbitros para añadir votos en las elecciones de un nuevo primario. Siempre tienen un voto, y permiten que los conjuntos de réplica tengan un número impar de nodos, sin la necesidad de tener un miembro que replique los datos. Además, no requieren hardware dedicado.
No ejecutar un árbitro en sistemas que también ejecutan los miembros primarios y secundarios del conjunto de réplicas.
Sólo añadir un árbitro a un conjunto con un número par de miembros.
Si se añade un árbitro a un conjunto con un número impar de miembros, el conjunto puede sufrir un empate.
-
Retrasado (delayed): nodo que se emplea para la recuperación del sistema ante un fallo. Para ello, hay que asignar la propiedad
priority:0. Este nodo nunca será un nodo primario. -
Oculto: empleado para analíticas del sistema.
oplog
Para soportar la replicación, el nodo primario almacena todos los cambios en su oplog.
De manera simplificada, el oplog es un diario de todos los cambios que la instancia principal realiza en las bases de datos con el propósito de replicar dichos cambios en un nodo secundario para asegurar que las dos bases de datos sean idénticas.
El servidor principal mantiene el oplog, y el secundario consulta al principal por nuevas entradas que aplicar a sus propias copias de las bases de datos replicadas.
El oplog crea un timestamp para cada entrada. Esto permite que un secundario controle la cantidad de información que se ha modificado desde una lectura anterior, y qué entradas necesita transferir para ponerse al día. Si paramos un secundario y lo reiniciamos más adelante, utilizará el oplog para obtener todos los cambios que ha perdido mientras estaba offline.
El oplog se almacena en una colección limitada (capped) y ordenada de un tamaño determinado. La opción oplogSize define en MB el tamaño del archivo. Para un sistema de 64 bits con comportamiento de lectura/escritura normales, el oplogSize debería ser de al menos un 5% del espacio de disco disponible. Si el sistema tiene más escrituras que lecturas, puede que necesitemos incrementar este tamaño para asegurar que cualquier nodo secundario pueda estar offline una cantidad de tiempo razonable sin perder información.
| Más información de oplog en http://docs.mongodb.org/manual/core/replica-set-oplog/ |
4.4.3. Creando un conjunto de réplicas
A la hora de lanzar una instancia, podemos indicarle mediante parámetros opcionales la siguiente información:
-
--dbpath: ruta de la base de datos -
--port: puerto de la base de datos -
--replSet: nombre del conjunto de réplicas -
-–fork: indica que se tiene que crear en un hilo -
--logpath: ruta para almacenar los archivos de log.
Normalmente, cada instancia mongod se coloca en un servidor físico y todos en el puerto estándar.
Como ejemplo vamos a crear un conjunto de tres réplicas. Para ello, arrancaremos tres instancias distintas pero que comparten el mismo conjunto de réplicas. Además, en vez de hacerlo en tres máquinas distinas, lo haremos en tres puertos diferentes:
Las carpeta que se crean tienen que tener los mismos permisos que mongod. Si no existiesen, las tenemos que crear previamente.
|
#!/bin/bash
mkdir -p /data/db/rs1 /data/db/rs2 /data/db/rs3 /data/logs
mongod --replSet replicaExperto --logpath /data/logs/rs1.log --dbpath /data/db/rs1 --port 27017 --oplogSize 64 --smallfiles --fork
mongod --replSet replicaExperto --logpath /data/logs/rs2.log --dbpath /data/db/rs2 --port 27018 --oplogSize 64 --smallfiles --fork
mongod --replSet replicaExperto --logpath /data/logs/rs3.log --dbpath /data/db/rs3 --port 27019 --oplogSize 64 --smallfiles --forkY lo lanzamos desde el shell mediante:
bash < creaConjuntoReplicas.shAl lanzar el script, realmente estamos creando las réplicas, por lo que obtendremos que ha creado hijos y que esta a la espera de conexiones:
about to fork child process, waiting until server is ready for connections.
forked process: 1811
child process started successfully, parent exiting
about to fork child process, waiting until server is ready for connections.
forked process: 1814
child process started successfully, parent exiting
about to fork child process, waiting until server is ready for connections.
forked process: 1817
child process started successfully, parent exitingUna vez lanzados las tres réplicas, tenemos que enlazarlas.
Así pues, nos conectaremos al shell de mongo. Puede ser que necesitemos indicar que nos conectamos al puerto adecuado:
mongo --port 27017Para comprobar su estado emplearemos el comando rs.status():
> rs.status()
{
"startupStatus" : 3,
"info" : "run rs.initiate(...) if not yet done for the set",
"ok" : 0,
"errmsg" : "can't get local.system.replset config from self or any seed (EMPTYCONFIG)"
}
Dentro del shell de mongo, los comandos que trabajan con réplicas comienzan por el prefijo rs.. Mediante rs.help() obtendremos la ayuda de los métodos disponibles,
|
A continuación, crearemos un documento con la configuración donde el _id tiene que ser igual al usado al crear la réplica, y el array de members contiene las replicas creadas donde los puertos han de coincidir.
> config = { _id: "replicaExperto", members:[
{ _id : 0, host : "localhost:27017"},
{ _id : 1, host : "localhost:27018"},
{ _id : 2, host : "localhost:27019"}
]};
Si en los miembros ponemos slaveDelay: numSeg podemos retrasar un nodo respecto al resto (también deberemos indicar que priority : 0 para que no sea un nodo principal). Más información en http://docs.mongodb.org/manual/core/replica-set-delayed-member/
|
Tras crear el documento de configuración, podemos iniciar el conjunto mediante:
> rs.initiate(config)
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}Si ahora volvemos a consultar el estado de la réplica tendremos:
replicaExperto:PRIMARY> rs.status()
{
"set" : "replicaExperto",
"date" : ISODate("2016-02-09T17:57:52.273Z"),
"myState" : 1,
"term" : NumberLong(1),
"heartbeatIntervalMillis" : NumberLong(2000),
"members" : [
{
"_id" : 0,
"name" : "localhost:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 89,
"optime" : {
"ts" : Timestamp(1455040665, 2),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2016-02-09T17:57:45Z"),
"infoMessage" : "could not find member to sync from",
"electionTime" : Timestamp(1455040665, 1),
"electionDate" : ISODate("2016-02-09T17:57:45Z"),
"configVersion" : 1,
"self" : true
},
{
"_id" : 1,
"name" : "localhost:27018",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 17,
"optime" : {
"ts" : Timestamp(1455040665, 2),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2016-02-09T17:57:45Z"),
"lastHeartbeat" : ISODate("2016-02-09T17:57:51.287Z"),
"lastHeartbeatRecv" : ISODate("2016-02-09T17:57:47.860Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "localhost:27017",
"configVersion" : 1
},
{
"_id" : 2,
"name" : "localhost:27019",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 17,
"optime" : {
"ts" : Timestamp(1455040665, 2),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2016-02-09T17:57:45Z"),
"lastHeartbeat" : ISODate("2016-02-09T17:57:51.287Z"),
"lastHeartbeatRecv" : ISODate("2016-02-09T17:57:47.869Z"),
"pingMs" : NumberLong(1),
"syncingTo" : "localhost:27017",
"configVersion" : 1
}
],
"ok" : 1
}La próxima vez que lancemos las réplicas ya no deberemos configurarlas. Así pues, el proceso de enlazar e iniciar las réplicas sólo se realiza una vez.
4.4.4. Trabajando con las réplicas
Una vez que hemos visto que las tres réplicas están funcionando, vamos a comprobar como podemos trabajar con ellas.
Para ello, nos conectamos al nodo principal (al ser el puerto predeterminado, podemos omitirlo):
$ mongo --port 27017Al conectarnos al nodo principal, nos aparece como símbolo del shell el nombre del conjunto de la réplica seguido de dos puntos y PRIMARY si nos hemos conectado al nodo principal, o SECONDARY en caso contrario.
replicaExperto:PRIMARY>Para saber si nos hemos conectado al nodo correcto, mediante rs.isMaster() obtendremos el tipo del nodo (propiedad ismaster) e información sobre el resto de nodos:
replicaExperto:PRIMARY> rs.isMaster()
{
"hosts" : [
"localhost:27017",
"localhost:27018",
"localhost:27019"
],
"setName" : "replicaExperto",
"setVersion" : 1,
"ismaster" : true,
"secondary" : false,
"primary" : "localhost:27017",
"me" : "localhost:27017",
"electionId" : ObjectId("56ba28990000000000000001"),
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 1000,
"localTime" : ISODate("2016-02-09T18:00:46.397Z"),
"maxWireVersion" : 4,
"minWireVersion" : 0,
"ok" : 1
}Ahora que sabemos que estamos en el nodo principal, vamos a insertar datos.
Para ello, vamos a insertar 100 documentos:
replicaExperto:PRIMARYfor (i=0; i<1000; i++) {
db.pruebas.insert({num: i})
}Estos 1000 documentos se han insertado en el nodo principal, y se han replicado a los secundarios. Para comprobar la replicación, abrimos un nuevo terminal y nos conectamos a un nodo secundario:
$ mongo --port 27018
replicaExperto:SECONDARY>Si desde el nodo secundario intentamos consultar el total de documentos de la colección obtendremos un error:
replicaExperto:SECONDARY> db.pruebas.count()
count failed: { "ok" : 0, "errmsg" : "not master and slaveOk=false", "code" : 13435 }El error indica que no somos un nodo primario y por lo tanto no podemos leer de él. Para permitir lecturas en los nodos secundarios, mediante rs.slaveOk() le decimos a mongo que sabemos que nos hemos conectado a un secundairo y admitimos la posibilidad de obtener datos obsoletos.
replicaExperto:SECONDARY> rs.slaveOk()
replicaExperto:SECONDARY> db.pruebas.count()
1000Pero que podamos leer no significa que podamos escribir. Si intentamos escribir en un nodo secundario obtendremos un error:
replicaExperto:SECONDARY> db.pruebas.insert({num : 1001})
WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })4.4.5. Tolerancia a fallos
Cuando un nodo primario no se comunica con otros miembros del conjunto durante más de 10 segundos, el conjunto de réplicas intentará, de entre los secundarios, que un miembro se convierta en el nuevo primario.
Para ello se realiza un proceso de votación, de modo que el nodo que obtenga el mayor número de votos se erigirá en primario. Este proceso de votación se realiza bastante rápido (menos de 3 segundos), durante el cual no existe ningún nodo primario y por tanto la réplica no acepta escrituras y todos los miembros se convierten en nodos de sólo-lectura.
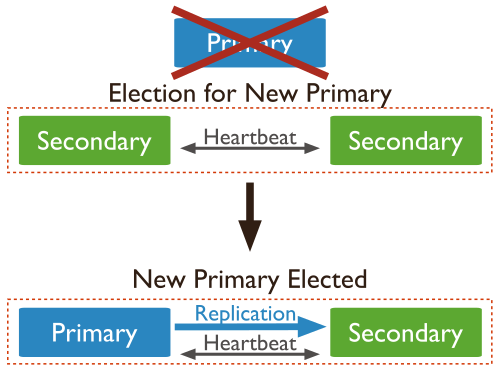
Proceso de votación
Cuando un nodo secundario no puede contactar con su nodo primario, contactará con el resto de miembros y les indicará que quiere ser elegido como primario. Es decir, cada nodo que no encuentre un primario se nominará como posible primario, de modo que un nodo no nomina a otro a ser primario, únicamente vota sobre una nominación ya existente.
Antes de dar su voto, el resto de nodos comprobarán:
-
si ellos tienen conectividad con el primario
-
si el nodo que solicita ser primario tienen una réplica actualizada de los datos. Todas las operaciones replicadas están ordenadas por el timestamp ascendentemente, de modo los candidatos deben tener operaciones posteriores o iguales a cualquier miembro con el que tengan conectividad.
-
si existe algún nodo con una prioridad mayor que debería ser elegido.
Si algún miembro que quiere ser primario recibe una mayoría de "sís" se convertirá en el nuevo primario, siempre y cuando no haya un servidor que vete la votación. Si un miembro la veta es porque conoce alguna razón por la que el nodo que quiere ser primario no debería serlo, es decir, ha conseguido contactar con el antiguo primario.
Una vez un candidato recibe una mayoría de "sís", su estado pasará a ser primario.
Cantidad de elementos
En la votación, se necesita una mayoría de nodos para elegir un primario, ya que una escritura se considera segura cuando ha alcanzado a la mayoría de los nodos. Esta mayoría se define como más de la mitad de todos los nodos del conjunto. Hay que destacar que la mayoría no se basa en los elementos que queden en pie o estén disponibles, sino en el conjunto definido en la configuración del conjunto.
Por lo tanto, es importante configurar el conjunto de una manera que siempre se puede elegir un nodo primario. Por ejemplo, en un conjunto de cinco nodos, si los nodos 1, 2 y 3 están en un centro de datos y los miembros 4 y 5 en otro, debería haber casi siempre una mayoría disponible en el primer centro de datos (es más probable que se pierda la conexión de red entre centros de datos que dentro de ellos).
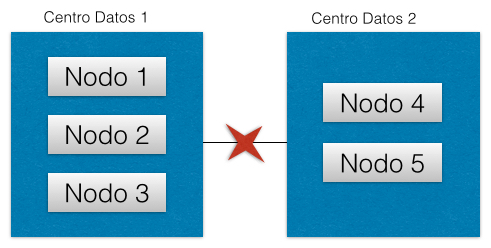
Por lo tanto, una configuración que hay que evitar es aquella compuesta por dos elementos: uno primario y uno secundario. Si uno de los dos miembros deja de estar disponible, el otro miembro no puede verlo. En esta situación, ninguna parte de la partición de red tiene una mayoría, con lo que acabaríamos con dos secundarios.
Por ello, el número mínimo de nodos es 3, para que al realizar una nueva elección se pueda elegir un nuevo nodo.
Comprobando la tolerancia
Para comprobar esto, desde el nodo primario vamos a detenerlo:
replicaExperto:PRIMARY> db.adminCommand({"shutdown" : 1})Otra posibilidad en vez de detenerlo es degradarlo a nodo secundario:
replicaExperto:PRIMARY> rs.stepDown()Si pasamos al antiguo nodo secundario, y le preguntamos si es el principal obtendremos:
replicaExperto:SECONDARY> rs.isMaster()
{
"setName" : "replicaExperto",
"setVersion" : 1,
"ismaster" : false,
"secondary" : true,
"hosts" : [
"localhost:27018",
"localhost:27019",
"localhost:27017"
],
"primary" : "localhost:27019",
"me" : "localhost:27018",
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 1000,
"localTime" : ISODate("2015-03-24T21:55:27.382Z"),
"maxWireVersion" : 2,
"minWireVersion" : 0,
"ok" : 1
}Si nos fijamos en la propiedad primary, veremos que tenemos un nuevo primario.
Configuración recomendada
Se recomiendan dos configuraciones:
-
Mediante una mayoría del conjunto en un centro de datos. Este planteamiento es bueno si tenemos un data center donde queremos que siempre se aloje el nodo primario de la réplica. Siempre que el centro de datos funcione normalmente, habrá un nodo primario. Sin embargo, si el centro primario pierde la conectividad, el centro de datos secundario no podrá elegir un nuevo primario.
-
Mediante el mismo número de servidores en cada centro de datos, más un servidor que rompe la igualdad en una tercera localización. Este diseño es conveniente cuando ambos centros de datos tienen el mismo grado de confiabilidad y robustez.
4.4.6. Recuperación del sistema
Si en un conjunto de réplicas se cae el primario y hay escrituras que se han pasado al oplog de modo que los otros nodos no las han replicado, cuando el nodo primario vuelva en sí como secundario y se sincronice con el primario, se dará cuenta que hay operaciones de escritura pendientes y las pasará a rollback, para que si se desean se apliquen manualmente.
Para evitar este escenario, se necesita emplear consistencia en la escritura, de manera que hasta que la escritura no se haya replicado en la mayoría de los nodos no se considere como una escritura exitosa.
Consistencia en la escritura
Ya hemos visto que tanto las lecturas como las escrituras se realizan de manera predeterminada en el nodo primario.
Las aplicaciones pueden decidir que las escrituras vayan al nodo primario pero las lecturas al secundario. Esto puede provocar que haya lecturas caducas, con datos obsoletos, pero como beneficio podemos escalar el sistema.
La replicación es un proceso asíncrono. En el período de tiempo en el que el sistema de votación sucede, no se completa ninguna escritura.
MongoDB garantiza la consistencia en la escritura, haciendo que sea un sistema consistente. Para ello, ofrece un sistema que garantiza que una escritura ha sido exitosa. Dependiendo del nivel de configuración de la consistencia, las inserciones, modificaciones y borrados pueden tardar más o menos. Si reducimos el nivel de consistencia, el rendimiento será mejor, a costa de poder obtener datos obsoletos u perder datos que no se han terminado de serializar en disco. Con un nivel de consistencia más alto, los clientes esperan tras enviar una operación de escritura a que MongoDB les confirme la operación.
Los valores que podemos configurar se realizan mediante las siguientes opciones:
-
w: indica el número de servidores que se han de replicar para que la inserción devuelva un ACK. -
j: indica si las escrituras se tienen que trasladar a un diario de bitácora (journal) -
wtimeout: indica el límite de tiempo a esperar como máximo, para prevenir que una escritura se bloquee indefinidamente.
Niveles de consistencia
Con estas opciones, podemos configurar diferentes niveles de consistencia son:
-
Sin confirmación:
w:0 -
Con confirmación:
w:1 -
Con diario:
w:1, j:true. Cada inserción primero se escribe en el diario y posteriormente en el directorio de datos. -
Con confirmación de la mayoría:
w:"majority"
Estas opciones se indican como parámetro final en las operaciones de insercion y modificación de datos. Por ejemplo:
db.pruebas.insert(
{num : 1002},
{writeConcern: {w:"majority", wtimeout: 5000}}
)4.5. Replicación en Java
Para conectar a una réplica desde Java, en el constructor del MongoClient le pasaremos como parámetro una lista con los elementos del conjunto:
MongoClient cliente = new MongoClient(Arrays.asList( (1)
new ServerAddress("localhost", 27017),
new ServerAddress("localhost", 27018),
new ServerAddress("localhost", 27019)));
// Resto de código similar a si nos conectamos a un sólo servidor
DBCollection coleccion = cliente.getDB("expertojava").getCollection("pruebas");
coleccion.drop();
for (int i = 0; i < 1000; i++) {
coleccion.insert(new BasicDBObject("_id", i));
System.out.println("Insertado documento: " + i);
}| 1 | Creamos la lista con ayuda de Arrays.asList() |
|
Autoevaluación
Si dejamos un nodo fuera de la réplica dentro de la lista de conexión del driver ¿Qué pasará? [1]
|
Cuando nos conectamos a una réplica, en el cliente le pasamos una lista de nodos (ServerAdress) a conectarnos. Aunque podemos no indicar todos los nodos del conjunto, es conveniente ponerlos.
A partir de la lista de servidores, conocida como lista de semillas (seed list), la clase MongoClient averigua los detalles del servidor a partir de los metadatos de la réplica, obtiendo todos los nodos que forman la réplica, así como quien es el primario en dicho momento. Es decir, si nos dejamos algún nodo fuera, el driver descubrirá la configuración del resto de nodos del conjunto y realizará las operaciones sobre los nodos a los no que no nos hemos conectado de manera explicita.
Además, MongoClient mantendrá en todo momento un hilo en background con la réplica para estar informado de cualquier cambio que suceda en el estado de la misma.
4.5.1. Reintento de Operaciones
En el caso de operaciones que insertan o modifican los datos, puede que sea conveniente realizar varios intentos con las operaciones para dar tiempo a que el conjunto de réplicas se recupere:
MongoClient client = new MongoClient(Arrays.asList(
new ServerAddress("localhost", 27017),
new ServerAddress("localhost", 27018),
new ServerAddress("localhost", 27019)));
DBCollection coleccion = client.getDB("expertojava").getCollection("pruebas");
coleccion.drop();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
for (int intentos = 0; intentos <= 2; intentos++) {
try {
coleccion.insert(new BasicDBObject("_id", i));
System.out.println("Documento insertado: " + i);
break;
} catch (DuplicateKeyException e) {
System.out.println("Documento ya insertado: " + i);
} catch (MongoException e) { (1)
System.out.println(e.getMessage());
System.out.println("Reintentando");
Thread.sleep(5000); (2)
}
}
Thread.sleep(500);
}| 1 | Si mientras estamos escribiendo sobre la réplica, el nodo primario se cae, el driver lanzará una MongoException. Por ello, es conveniente capturar la excepción, y si la operación que estamos realizando es una inserción, reintentarla. |
| 2 | Esperamos 5 segundos a que la réplica se recupere y un secundario se convierta en primario |
Para poder probar este ejemplo, tras lanzar la clase Java, comenzará a insertar documentos sin parar. En un terminal nos conectamos al nodo primario y lo degradamos mediante rs.stepDown() para que se produzca una votación y se elija un nuevo primario:
replicaExperto:PRIMARY> rs.stepDown()
2015-05-03T09:41:52.619+0200 DBClientCursor::init call() failed
2015-05-03T09:41:52.621+0200 Error: error doing query: failed at src/mongo/shell/query.js:81
2015-05-03T09:41:52.623+0200 trying reconnect to 127.0.0.1:27018 (127.0.0.1) failed
2015-05-03T09:41:52.626+0200 reconnect 127.0.0.1:27018 (127.0.0.1) ok
replicaExperto:SECONDARY>Si comprobamos la salida del sistema, veremos como el sistema se recupera de una caída del sistema y reintenta la inserción:
...
Documento insertado: 39855
Operation on server localhost:27018 failed
Reintentando
Documento insertado: 39856
...4.5.2. Consistencia de Escritura
En Java, para indicar el nivel de consistencia, se realiza mediante el método setWriteConcern(nivel), siendo nivel uno de los valores de la enumeración WriteConcern, la cual puede tomar diferentes valores, siendo los más importantes:
-
WriteConcern.UNACKNOWLEDGED -
WriteConcern.ACKNOWLEDGED -
WriteConcern.JOURNALED -
WriteConcern.MAJORITY
Este nivel se puede indicar a nivel de:
-
cliente:
cliente.setWriteConcern(nivel) -
de base de datos: :
db.setWriteConcern(nivel) -
de colección:
coleccion.setWriteConcern(nivel) -
o con cada inserción :
cliente.insert(doc, nivel)
WriteConcernMongoClient cliente = new MongoClient(Arrays.asList(
new ServerAddress("localhost", 27017),
new ServerAddress("localhost", 27018),
new ServerAddress("localhost", 27019)));
cliente.setWriteConcern(WriteConcern.JOURNALED);
DB db = cliente.getDB("expertojava");
db.setWriteConcern(WriteConcern.ACKNOWLEDGED);
DBCollection coleccion = db.getCollection("pruebas");
coleccion.setWriteConcern(WriteConcern.MAJORITY);
coleccion.drop();
DBObject doc = new BasicDBObject("_id", 1);
coleccion.insert(doc);
try {
coleccion.insert(doc, WriteConcern.UNACKNOWLEDGED);
} catch (MongoException e) {
System.out.println(e.getMessage());
}4.5.3. Preferencia de Lectura
La preferencia de lectura permite indicar al driver a qué servidores podemos enviar consultas.
| Como regla general, enviar peticiones de lectura a nodos secundarios es una mala decisión. |
Los posibles preferencias de lectura llevan asociadas situaciones en las que tiene sentido realizar la lectura desde un nodo secundario. Así pues, las preferencias se dividen en:
-
primary: valor por defecto. Todas las lecturas se realizan en el nodo primario. Si se cae este nodo, el sistema no acepta lecturas. Es el único modo que garantiza los datos más recientes, ya que todas las escrituras pasan por él. -
primaryPreferred: realiza la lectura de nodos secundarios cuando el primario ha caído. Si el nodo primario está en pie siempre se realizará la lecturas sobre él. -
nearest: en ocasiones los nodos secundarios están más cercanos al cliente. En este caso, podemos acceder a los datos con la menor latencia posible, sin tener en cuenta si accedemos a un primario o a un secundario. -
secondary: envía las lecturas a nodos secundarios. Si no hubiese ningún nodo secundario disponible, la lectura fallará. Se emplea en aplicaciones que sólo quieren utilizar el nodo primario para escrituras, o bien en aplicaciones que quieres sacar estadísticas de los datos y no quieren cargar el nodo principal. -
secondaryPreferred: envía las lecturas a nodos secundarios, pero si no hubiese ninguno, la enviaría al primario.
Las lecturas de los nodos secundarios toman sentido cuando tenemos datos en los que la cantidad de operaciones de lectura son completamente predominantes sobre las escrituras.
ReadPreference
Para configurar estos posibilidades mediante Java emplearemos la clase ReadPreference, la cual ofrece métodos para configurar los valores vistos.
Se puede configura con granularidad de:
-
cliente:
client.setReadPreference() -
base de datos:
db.setReadPreference() -
colección:
col.setReadPreference() -
operación:
cursor.setReadPreference()
ReadPreferenceMongoClient cliente = new MongoClient(Arrays.asList(
new ServerAddress("localhost", 27017),
new ServerAddress("localhost", 27018),
new ServerAddress("localhost", 27019)));
cliente.setReadPreference(ReadPreference.primary());
DB db = cliente.getDB("expertojava");
db.setReadPreference(ReadPreference.primary());
DBCollection coleccion = db.getCollection("pruebas");
coleccion.setReadPreference(ReadPreference.primaryPreferred());
DBCursor cursor = coleccion.find().setReadPreference(ReadPreference.nearest()); (1)
try {
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
} finally {
cursor.close();
}| 1 | El driver elige el servidor al que enviar la consulta mediante un ping a la máquina para averiguar el tiempo empleado (ms). |
4.6. Particionado (Sharding)
Ya vimos en la primera sesión que dentro del entorno de las bases de datos, particionar consiste en dividir los datos entre múltiples máquinas. Al poner un subconjunto de los datos en cada máquina, vamos a poder almacenar más información y soportar más carga sin necesidad de máquinas más potentes, sino una mayor cantidad de máquinas más modestas (y mucho más baratas).
El Sharding es una técnica que fragmenta los datos de la base de datos horizontalmente agrupándolos de algún modo que tenga sentido y que permita un direccionamiento más rápido.
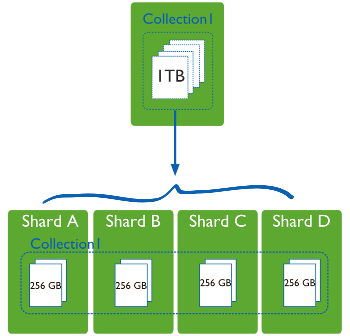
Por lo tanto, estos shards (fragmentos) pueden estar localizados en diferentes bases de datos y localizaciones físicas.
El Sharding no tiene por qué estar basado únicamente en una colección y un campo, puede ser a nivel de todas las colecciones. Por ejemplo podríamos decir "todos los datos de usuarios cuyo perfil está en los Estados Unidos los redirigimos a la base de datos del servidor en Estados Unidos, y todos los de Asia van a la base de datos de Asia".
4.6.1. Particionando con MongoDB
MongoDB implementa el sharding de forma nativa y automática (de ahí el término de auto-sharding), siguiendo un enfoque basado en rangos.
Para ello, divide una colección entre diferentes servidores, utilizando mongos como router de las peticiones entre los sharded clusters.
Esto favorece que el desarrollador ignore que la aplicación no se comunica con un único servidor, balanceando de manera automática los datos y permitiendo incrementar o reducir la capacidad del sistema a conveniencia.
| Antes de plantearse hacer auto-sharding sobre nuestros datos, es conveniente dominar cómo se trabaja con MongoDB y el uso de conjuntos de réplica. |
Sharded Cluster
El particionado de MongoDB permite crear un cluster de muchas máquinas, dividiendo a nivel de colección y poniendo un subconjunto de los datos de la colección en cada uno de los fragmentos.
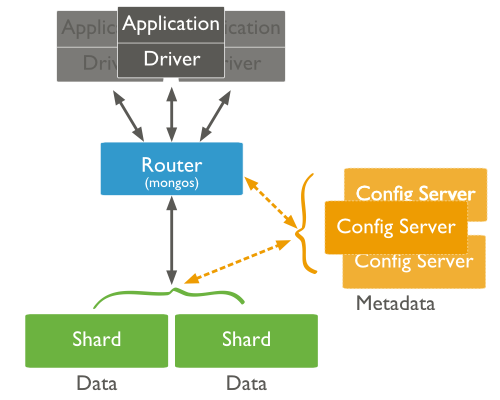
Los componentes de un sharded clusters son:
- Shards (Fragmentos)
-
Cada una de las máquinas del cluster, que almacena un subconjunto de los datos de la colección. Cada shard es una instancia de
mongodo un conjunto de réplicas. En un entorno de producción, todos los shards son conjuntos de réplica. - Servidores de Configuracion
-
Cada servidor de configuración es una instancia de
mongodque almacena metadatos sobre el cluster. Los metadatos mapean los trozos con los shards, definiendo qué rangos de datos definen un trozo (chunk) de la colección, y qué trozos se encuentran en un determinado shard.En entornos de producción se aconseja tener 3 servidores de configuración ya que si sólo tuviésemos uno, al producirse una caída el cluster quedaría inaccesible.
- Enrutadores
-
Cada router es una instancia
mongosque enruta las lecturas y escrituras de las aplicaciones a los shards. Las aplicaciones no acceden directamente a los shards, sino al router. Estos enrutadores funcionan de manera similar a una tabla de contenidos, que nos indica donde se encuentran los datos. Una vez recopilados los datos de los diferentes shards, se fusionan y se encarga de devolverlos a la aplicación.En entornos de producción es común tener varios routers para balancear la carga de los clientes.
|
Autoevaluación
Supongamos que queremos ejecutar múltiples routers
|
Shard key
Para que MongoDB sepa cómo dividir una colección en trozos, hay que elegir una shard key, normalmente el identificador del documento, por ejemplo, student_id. Este identificador es la clave del chunk (por lo hace la misma función que una clave primaria).
Para las búsquedas, borrados y actualizaciones, al emplear la shard key, mongos sabe a que shard enviar la petición. En cambio, si la operación no la indica, se hará un broadcast a todas los shards para averiguar donde se encuentra.
Por eso, toda inserción debe incluir la shard key. En el caso de tratarse de una clave compuesta, la inserción debe contener la clave completa.
Entre los aspectos a tener en cuenta a la hora de elegir una shard key cabe destacar que debe:
-
Tener una alta cardinalidad, para asegurar que los documentos puedan dividirse en los distintos fragmentos. Por ejemplo, si elegimos un shard key que solo tiene 3 valores posibles y tenemos 5 fragmentos, no podríamos separar los documentos en los 5 fragmentos al solo tener 3 valores posibles para separar. Cuantos más valores posibles pueda tener la clave de fragmentación, más eficiente será la división de los trozos entre los fragmentos disponibles.
-
Tener un alto nivel de aleatoriedad. Si utilizamos una clave que siga un patrón incremental como una fecha o un ID, conllevará que al insertar documentos, el mismo fragmento estará siendo utilizando constantemente durante el rango de valores definido para él. Esto provoca que los datos estén separados de una manera óptima, pero pondrá siempre bajo estrés a un fragmento en períodos de tiempo mientras que los otros posiblemente queden con muy poca actividad (comportamiento conocido como hotspotting).
Una solución a las claves que siguen patrones incrementales es aplicar una funcion hash y crear una clave hasheada que si tiene un alto nivel de aleatoriedad.
| Más consejos sobre como elegir la shard key en http://techinsides.blogspot.com.es/2013/09/keynote-concerns-how-to-choose-mongodb.html |
Finalmente, destacar que toda shard key debe tener un índice asociado.
4.6.2. Preparando el Sharding con MongoDB
Para comenzar, vamos a crear un particionado en dos instancias en las carpetas /data/s1/db y /data/s2/db. Los logs los colocaremos en /data/logs y crearemos un servidor para la configuración de los metadatos del shard en /data/con1/db:
mkdir -p /data/s1/db /data/s2/db /data/logs /data/conf1/db
chown `id -u` /data/s1/db /data/s2/db /data/logs /data/conf1/dbA continuación, arrancaremos un proceso mongod por cada uno de los shards (con la opción --shardsvr) y un tercero para la base de datos de configuración (con la opción --configsvr). Finalmente, también lanzaremos un proceso mongos:
mongod --shardsvr --dbpath /data/s1/db --port 27000 --logpath /data/logs/sh1.log --smallfiles --oplogSize 128 --fork
mongod --shardsvr --dbpath /data/s2/db --port 27001 --logpath /data/logs/sh2.log --smallfiles --oplogSize 128 --fork
mongod --configsvr --dbpath /data/conf1/db --port 25000 --logpath /data/logs/config.log --fork
mongos --configdb localhost:25000 --logpath /data/logs/mongos.log --forkEl cual lanzaremos mediante
bash < creaShard.shUna vez creado, arrancaremos un shell del mongo, y observaremos como se lanza mongos:
$ mongo
MongoDB shell version: 3.2.1
connecting to: test
mongos>Finalmente, configuraremos el shard mediante el método sh.addShard(URI), obteniendo confirmación tras cada cada uno:
mongos> sh.addShard("localhost:27000")
{ "shardAdded" : "shard0000", "ok" : 1 } (1)
mongos> sh.addShard("localhost:27001")
{ "shardAdded" : "shard0001", "ok" : 1 }| 1 | El valor de la propiedad shardAdded nos devuelve el identificado unívoco de cada shard. |
De manera similar que con el conjunto de réplicas se emplean el prefijo rs, para interactuar con los componentes implicados en el sharding se emplea sh. Por ejemplo, mediante sh.help() obtendremos la ayuda de los métodos disponibles.
|
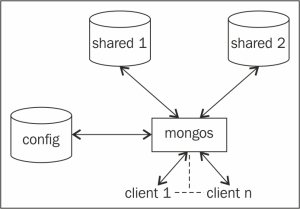
Así pues, en este momento tenemos montada un shard con:
-
dos instancias de
mongodpara almacenar datos en los puertos 27000 y 27001 (shards) -
una instancia
monogden el puerto 25000 (servidor de configuración) encargada de almacenar los metadatos del shard, a la cual sólo se deberían conectar el procesomongoso los drivers para obtener información sobre el shard y la shard key -
y un proceso
mongos(enrutador), encargado de aceptar las peticiones de los clientes y enrutar las peticiones al shard adecuado.
Si comprobamos el estado del shard podremos comprobar como tenemos dos shards, con sus identificadores y URIs:
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("56bc7054ba6728d2673a1755")
}
shards:
{ "_id" : "shard0000", "host" : "localhost:27000" }
{ "_id" : "shard0001", "host" : "localhost:27001" }
active mongoses:
"3.2.1" : 1
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:En un entorno de producción, en vez de tener dos shards, habrá un conjunto de réplicas para asegurar la alta disponibilidad. Además, tendremos tres servidores de configuración para asegurar la disponibilidad de éstos. Del mismo modo, habrá tantos procesos mongos creados para un shard como conexiones de clientes.
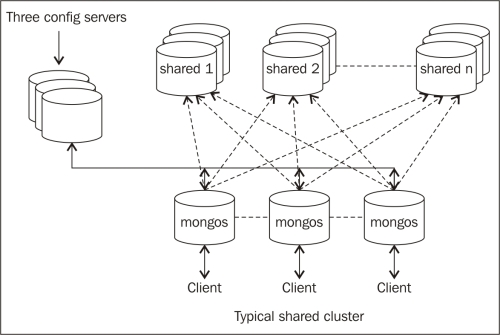
| En init_sharded_replica.sh podéis comprobar como crear sharding sobre un conjunto de réplicas. |
4.6.3. Habilitando el Sharding
Una vez hemos creado la estructura necesaria para soportar el sharding vamos a insertar un conjunto de datos para posteriormente particionarlos.
Para ello, vamos a insertar cien mil usuarios en una colección:
mongos> use expertojava
switched to db expertojava
mongos> for (var i=0; i<100000; i++) {
db.usuarios.insert({"login":"usu" + i,"nombre":"nom" + i*2, "fcreacion": new Date()});
}
mongos> db.usuarios.count()
100000Como podemos observar, interactuar con mongos es igual a hacerlo con mongo.
Ahora mismo no sabemos en qué cual de los dos shards se han almacenado los datos. Además, estos datos no están particionados, es decir residen en sólo uno de los shards.
Para habilitar el sharding a nivel de base de datos y que los datos se repartan entre los fragmentos disponibles, ejecutaremos el comando sh.enableSharding(nombreDB) :
mongos> sh.enableSharding("expertojava")Si volvemos a comprobar el estado del shard, tenemos que se ha creado la nueva base de datos que contiene la propiedad "partitioned" : true, la cual nos informa que esta fragmentada.
Antes de habilitar el sharding para una determinada colección, tenemos que crear un índice sobre la shard key:
mongos> db.usuarios.createIndex({"login": 1})
{
"raw" : {
"localhost:27000" : {
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
},
"ok" : 1
}Una vez habilitado el shard ya podemos fragmentar la colección:
mongos> sh.shardCollection("expertojava.usuarios", {"login": 1}, false)El método shardCollection particiona una colección a partir de una shard key. Para ello, recibe tres parámetros:
-
nombre de la colección, con nomenclatura de
nombreBD.nombreColección -
nombre del campo para fragmentar la colección, es decir, el shard key. Uno de los requisitos es que esta clave tengo una alta cardinalidad. Si tenemos una propiedad con una cardinalidad baja, podemos hacer un hash de la propiedad mediante
{"login": "hashed"}. Como en nuestro caso hemos utilizado un campo con valores únicos hemos puesto{"login": 1}. -
booleano que indica si el valor utilizado como shard key es único. Para ello, el índice que se crea sobre el campo debe ser del tipo
unique.
Este comando divide la colección en chunks, la cual es la unidad que utiliza MongoDB para mover los datos. Una vez que se ha ejecutado, MongoDB comenzará a balancear la colección entre los shards del cluster. Este proceso no es instantáneo. Si la colección contiene un gran conjunto de datos puede llevar horas completar el balanceo.
Si ahora volvemos a comprobar el estado del shard obtendremos:
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("56bc7054ba6728d2673a1755")
}
shards:
{ "_id" : "shard0000", "host" : "localhost:27000" }
{ "_id" : "shard0001", "host" : "localhost:27001" }
active mongoses:
"3.2.1" : 1
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "expertojava", "primary" : "shard0000", "partitioned" : true }
expertojava.usuarios
shard key: { "login" : 1 }
unique: false
balancing: true
chunks: (1)
shard0000 1
{ "login" : { "$minKey" : 1 } } -->> { "login" : { "$maxKey" : 1 } } on : shard0000 Timestamp(1, 0) (2)| 1 | la propiedad chunks muestra la cantidad de trozos que alberga cada partición. Así, pues en este momento tenemos 1 chunk |
| 2 | Para cada uno de los fragmentos se muestra el rango de valores que alberga cada chunk, así como en que shard se ubica. |
Las claves $minKey y $maxKey son similares a menos infinito y más infinito, es decir, no hay ningún valor por debajo ni por encima de ellos. Es decir, indican los topes de la colección.
4.6.4. Trabajando con el Sharding
En este momento, el shard esta creado pero todos los nodos residen en un único fragmento dentro de un partición. Vamos a volver a insertar 100.000 usuarios más a ver que sucede.
mongos> for (var i=100000; i<200000; i++) {
db.usuarios.insert({"login":"usu" + i,"nombre":"nom" + i*2, "fcreacion": new Date()});
}
mongos> db.usuarios.count()
200000Si ahora comprobamos el estado del shard, los datos se deberían haber repartido entre los shards disponibles:
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("56bc7054ba6728d2673a1755")
}
shards:
{ "_id" : "shard0000", "host" : "localhost:27000" }
{ "_id" : "shard0001", "host" : "localhost:27001" }
active mongoses:
"3.2.1" : 1
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
31 : Success
databases:
{ "_id" : "expertojava", "primary" : "shard0000", "partitioned" : true }
expertojava.usuarios
shard key: { "login" : 1 }
unique: false
balancing: true
chunks: (1)
shard0000 32
shard0001 31
too many chunks to print, use verbose if you want to force print| 1 | Con estos datos se ha forzado a balancear los mismos entre los dos fragmentos, habiendo en cada uno de ellos 32 y 31 trozos respectivamente |
Si ahora realizamos una consulta y obtenemos su plan de ejecución veremos como se trata de una consulta que se ejecuta en paralelo:
mongos> db.usuarios.find({"login":"usu12345"}).explain()
{
"queryPlanner" : {
"mongosPlannerVersion" : 1,
"winningPlan" : {
"stage" : "SINGLE_SHARD",
"shards" : [
{
"shardName" : "shard0001",
"connectionString" : "localhost:27001",
"serverInfo" : {
"host" : "MacBook-Air-de-Aitor.local",
"port" : 27001,
"version" : "3.2.1",
"gitVersion" : "a14d55980c2cdc565d4704a7e3ad37e4e535c1b2"
},
"plannerVersion" : 1,
"namespace" : "expertojava.usuarios",
"indexFilterSet" : false,
"parsedQuery" : {
"login" : {
"$eq" : "usu12345"
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "SHARDING_FILTER",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"login" : 1
},
"indexName" : "login_1",
"isMultiKey" : false,
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 1,
"direction" : "forward",
"indexBounds" : {
"login" : [
"[\"usu12345\", \"usu12345\"]"
]
}
}
}
},
"rejectedPlans" : [ ]
}
]
}
},
"ok" : 1
}Podemos observar como se ha realizado una fase SINGLE_SHARD de manera que ha accedido únicamente al shard0001, y posteriormente una fase de SHARDING_FILTER en la cual ha empleado un índice para el escaneo (IXSCAN).
Si en vez de obtener un documento concreto, obtenemos el plan de ejecución de obtener todos los documentos tendremos:
mongos> db.usuarios.find().explain()
{
"queryPlanner" : {
"mongosPlannerVersion" : 1,
"winningPlan" : {
"stage" : "SHARD_MERGE",
"shards" : [
{
"shardName" : "shard0000",
"connectionString" : "localhost:27000",
"serverInfo" : {
"host" : "MacBook-Air-de-Aitor.local",
"port" : 27000,
"version" : "3.2.1",
"gitVersion" : "a14d55980c2cdc565d4704a7e3ad37e4e535c1b2"
},
"plannerVersion" : 1,
"namespace" : "expertojava.usuarios",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : [ ]
},
"winningPlan" : {
"stage" : "SHARDING_FILTER",
"inputStage" : {
"stage" : "COLLSCAN",
"filter" : {
"$and" : [ ]
},
"direction" : "forward"
}
},
"rejectedPlans" : [ ]
},
{
"shardName" : "shard0001",
"connectionString" : "localhost:27001",
"serverInfo" : {
"host" : "MacBook-Air-de-Aitor.local",
"port" : 27001,
"version" : "3.2.1",
"gitVersion" : "a14d55980c2cdc565d4704a7e3ad37e4e535c1b2"
},
"plannerVersion" : 1,
"namespace" : "expertojava.usuarios",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : [ ]
},
"winningPlan" : {
"stage" : "SHARDING_FILTER",
"inputStage" : {
"stage" : "COLLSCAN",
"filter" : {
"$and" : [ ]
},
"direction" : "forward"
}
},
"rejectedPlans" : [ ]
}
]
}
},
"ok" : 1
}Así pues, si en una consulta no le enviamos la shard key como criterio, mongos enviará la consulta a cada shard y realizará un SHARD_MERGE con la información devuelta de cada shard. Si la consulta contiene la shard key, la consulta se enruta directamente al shard apropiado.
4.7. Ejercicios
4.7.1. (1.25 puntos) Ejercicio 41. Agregaciones
A partir de la colección cities de la base de datos ejercicios, escribe los comandos necesarios y el resultado en ej41.txt para obtener la información de las siguientes consultas mediante el pipeline de agregación:
-
Nombreypoblaciónde las tres ciudades españolas con más habitantes. Resultado:{ "nombre" : "Madrid", "poblacion" : 3255944 } { "nombre" : "Barcelona", "poblacion" : 1621537 } { "nombre" : "Valencia", "poblacion" : 814208 } -
País,poblacióny cantidad deciudadesde dicho país, ordenados de mayor a menor población. Resultado:{ "poblacion" : 282839031, "ciudades" : 5568, "pais" : "CN" } { "poblacion" : 272149640, "ciudades" : 3350, "pais" : "IN" } { "poblacion" : 223341111, "ciudades" : 14566, "pais" : "US" } ... -
País,población,ratioentendido como el resultado de dividir la población del país entre el número de ciudades,ciudadMasPobladaen mayúsculas ypobCiudadMasPoblada(población de la ciudad más poblada) ordenados por el ratio de población/ciudades:{ "ciudadMasPoblada" : "Singapore", "pobCiudadMasPoblada" : 3547809, "pais" : "SG", "ratio" : 3547809 } { "ciudadMasPoblada" : "Hong Kong", "pobCiudadMasPoblada" : 7012738, "pais" : "HK", "ratio" : 2260092.75 } { "ciudadMasPoblada" : "Macau", "pobCiudadMasPoblada" : 520400, "pais" : "MO", "ratio" : 520400 } ...
4.7.2. (1 punto) Ejercicio 42 / 43. Replicación - Sharding
A continuación, se exponen dos ejercicios, de los cuales el alumno debe de elegir uno de los dos.
Replicación
Se pide crear una conjunto de 4 réplicas de nombre ej42 en la cual insertaremos los datos de las ciudades de la primera sesión.
El script de creación del conjunto de réplicas se almacenará en ej42creacion.sh, y los comandos para inicializar el conjunto en ej42init.js.
Una vez cargado los datos, obtener el estado del conjunto y guardar el comando y el resultado en ej42estado.txt.
Tras ello se pide almacenar en ej42operaciones.txt los comandos y resultados obtenidos para:
-
Consultar una ciudad en un nodo secundario.
-
Habilitar las lecturas en los nodos secundarios.
-
Volver a consultar la ciudad en el nodo secundario.
-
Insertar una ciudad en el nodo secundario.
-
Detener el nodo primario.
-
Averiguar cual es el nuevo nodo primario.
Sharding
Se pide crear un shard con tres servidores e importar las ciudades en el shard.
Para ello, particionar los datos por el nombre de la ciudad.
El script de creación de las fragmentos se almacenará en ej42creacion.sh, y los comandos para inicializar el sharding en ej42init.js.
Una vez cargado los datos, obtener el estado del sharding y almacenar el comando y el resultado en ej42estado1.txt.
Tras ello, vacíar la colección y volver a importar los datos. Una vez importados, obtener el estado del sharding y almacenar el comando y el resultado en ej42estado2.txt