7. Características IaaS+ de OpenShift
7.1. Introducción
En la sesión anterior adquirimos los conocimientos básicos para crear aplicaciones y desplegarlas en cloud de forma análoga a otros proveedores de PaaS. En esta sesión continuaremos aprendiendo características de Openshift que necesitaremos conocer si vamos a trabajar en un proyecto real y se acercan a la forma de trabajo de una plataforma IaaS+.
7.2. Configuración avanzada
7.2.1. SSH
OpenShift permite el acceso remoto a nuestros gear mediante una sesión SSH del mismo modo que accederíamos a una máquina física. Una vez estamos conectados a un gear podremos modiicar su configuración, ejecutar comandos de administración o consultar los ficheros de log. Desde la sesión remota tenemos un control razonablemente completo de la parte de máquina que se nos asigna, pero sin embargo no podremos realizar cambios que requieran ser administrador.
Para poder iniciar una sesión remota tenemos dos posibilidades:
-
Utilizar un cliente ssh, al que debemos llamar con una dirección específica que podemos obtener de la propia información de la aplicación, bien desde la consola web, o bien mediante rhc:
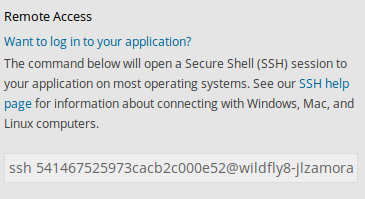
-
Utilizar rhc como intermediario entre el cliente ssh y OpenShift. En este caso basta con ejecutar:
$ rhc ssh <app>|
Conexión SSH desde Windows con Putty
Windows no incorpora ningún cliente de ssh de serie así que hay que recurrir a una aplicación externa. Una de las más extendidas es Putty pero para que emplea una codificación distinta para las claves con lo que es necesario convertir la clave privada generada por openshift, del formato OpenSSH al formato propio de Putty. Esto se puede hacer con la herramienta puttygen que incluye. Una vez convertida, hay que especificar la nueva clave privada en la propiedad Auth de la opción ssh. Más información en: https://developers.openshift.com/en/managing-remote-connection.html
|
Cambios en la configuración de la aplicación.
Una vez iniciemos la sesión en un gear, veremos un mensaje de bienvenida similar a este:
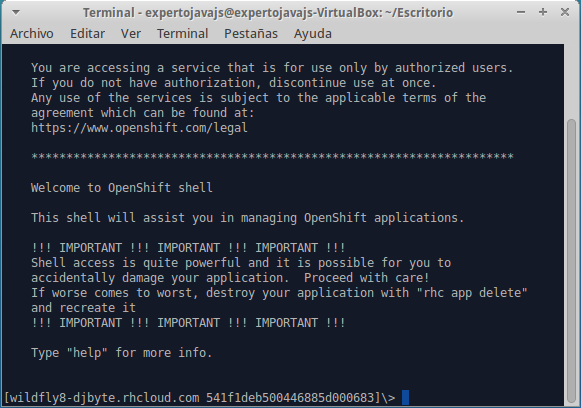
Desde la sesión podemos utilzar los comandos habituales de Unix y navegar por la estructura de directorios, que ya anticipamos en la sesión anterior:

Además de estas carpetas, normalmente nos encontraremos una carpeta adicional por cada cartridge instalado, en la cual encontraremos su configuración. Desde esta sesión podremos modificar ficheros de configuración reiniciar la aplicación, cargar datos en un SGBD, crear scripts o cualquier otra tarea que requiera trabajo "directo" con la máquina. Podemos utilizar la mayoría de los comandos de unix, más una serie de comandos propios de OpenShift:
Comando |
Descripción |
help |
muestra un cuadro resumen con los comandos básicos de OpenShift |
gear |
permite controlar la aplicación (iniciarla, pararla, reiniciarla, etc.) |
tail_all |
similar al tail de Unix pero vuelca todos los logs de los servicios |
quota |
muestra el espacio utilizado y los límites definidos para el gear |
mysql |
lanza el cliente de MySQL si tenemos desplegado el cartridge |
psql |
cliente de PostgreSQL |
mongo |
cliente de MongoDB |
Como norma general, modificaremos los ficheros de configuración directamente sobre el gear para realizar pruebas, para realizar cambios "en caliente" sobre la aplicación o bien cuando no exista reflejo de la configuración de un cartridge dentro del repositorio Git de la aplicación. Los cambios de configuración de servidores de aplicaciones habitualmente se harán a través del repositorio Git, mientras que los cambios de configuración de base de datos se harán directamente sobre el gear, o utilizando el mecanismo de port-forward.
| Recordad que si hacemos cambios directamente en el gear y posteriormente modificamos la configuración desde el repositorio Git, perderemos los cambios realizados. |
7.2.2. Variables de entorno
OpenShift permite configurar gears con los elementos que consideremos necesarios para ejecutar nuestra aplicación. Si utilizamos una base de datos, deberemos acceder a ella a través de un puerto determinado y con unas credenciales autogeneradas. Lo mismo ocurre con un servidor de aplicaciones o cualquier otro cartridge que hayamos instalado. Sería complicado tener que gestionar manualmente toda esta información de configuración desde la aplicación, configuración que probablemente cambie si desplegamos la aplicación en un gear distinto, o tras un mantenimiento realizado por Red Hat.
En OpenShift se propone como solución desacoplar esta configuración de las aplicaciones mediante variables de entorno. Si desde una sesión ssh, ejecutamos el comando env podremos ver la lista de variables de entorno predefinidas.
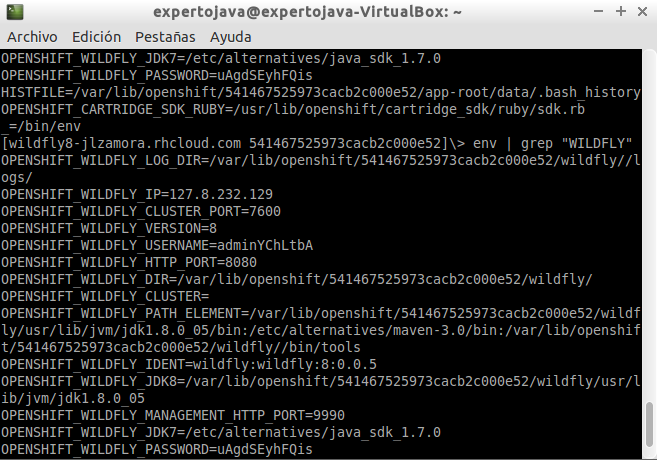
Variable Name |
Example |
Purpose |
OPENSHIFT_APP_DNS |
appname-namespace.rhcloud.com |
The fully-qualified domain name for your application |
OPENSHIFT_APP_NAME |
appname |
Your application’s name |
OPENSHIFT_APP_UUID |
0123456789abcdef0 123456789abcdef |
The UUID your application runs as (32 hex characters) |
OPENSHIFT__IP |
127.0.250.1 |
The IP address your application will listen on |
OPENSHIFT__PORT |
8080 |
The port your application will receive requests from |
OPENSHIFT_DATA_DIR |
$OPENSHIFT_HOMEDIR/app-root/data/ |
A persistent directory for your data |
OPENSHIFT__LOG_DIR |
$OPENSHIFT_HOMEDIR//logs/ |
Where your cartridge-specific logs are stored. |
OPENSHIFT__DB_LOG_DIR |
$OPENSHIFT_HOMEDIR//log/ |
Where your database-specific logs are stored. |
OPENSHIFT_REPO_DIR |
$OPENSHIFT_HOMEDIR/app-root/runtime/repo/ |
Repository containing the currently deployed version (of the application) |
OPENSHIFT_TMP_DIR |
/tmp/ |
A temporary directory you can use. Even though the path is just /tmp, the magic of SELinux protects your data from other users |
Adicionalmente cada catridge que instalemos informa un conjunto de variables distinto por lo que es importante consultar la documentación de cada uno de estos componentes para saber como utilizarlos desde las aplicaciones.
Crear/modificar variables
El conjunto de variables de entorno predefinidas puede ser ampliado con las variables que consideremos necesario. Para gestionar las variables de entorno tenemos un comando específico rhc env:
$ rhc env set VARIABLE1=valor1 ... VARIABLEN=valorn -a <app> // Establecer variables de entorno
$ rhc env list -a <app> // muestra todas las variables de entorno definidas por el usuario
$ rhc env unset VARIABLE1=valor1 ... VARIABLEN=valorn -a <app> // Eliminar variables de usuario
$ rhc env show VARIABLE1... VARIABLEN -a <app> // Mostrar el valor de las variables especificadas.| La mayoría de las variables predefinidas están protegidas para preservar la integridad del gear, por tanto si intentamos modificarlas con este comando se nos mostrará un mensaje de error. |
7.2.3. Uso de Markers
En la primera sesión de WildFly hablamos de unos ficheros llamados markers que se utilizaban para controlar el despliegue manual de las aplicaciones. El contenido de estos ficheros no es lo importante, si no su nombre y su ubicación. En Openshift se utiliza el mismo concepto para cambiar aspectos de la configuración.
El procedimiento habitual para crear estos marcadores es crearlos dentro del repositorio Git, y subirlos al servidor mediante push. La ubicación de estos ficheros dentro del repositorio es ./openshift/markers.
Hot Deploy
Por defecto, tras realizar un push de cambios al repositorio, se reinicia automáticamente el servidor de aplicaciones. Si queremos redesplegar sin reiniciar el servidor, o bien utilizamos un lenguaje interpretado, podemos desactivar el reinicio automático añadiendo el marcador hot_deploy:
$ touch .openshift/markers/hot_deploy
$ git add .openshift/markers/hot_deploy
$ git commit -m "Changing application to hot deploy"
$ git push originCuando hagamos el push del repositorio, se aplicará el cambio en la configuración del servidor.
Otros markers de interés
disable_auto_scaling |
Desactiva la creación/destrucción de gears en función de la carga de trabajo |
force_clean_build |
Fuerza a eliminar todos los artefactos previamente construidos |
skip_maven_build |
Desactiva la compilación Maven al hacer un push al repositorio |
enable_jpda |
Activa la depuración remota del servidor de aplicaciones |
java7 |
Fuerza a utilizar el JRE de Java 7 (por defecto Java 6) |
java8 |
Fuerza a utilizar el JRE de Java 8 (por defecto Java 6) |
7.2.4. Action Hook Scripts
Los catridge de Openshift standalone, implementan un ciclo de vida con las fases más importantes entre la compilación de la aplicación y su despliegue, de forma similar a herramientas como Maven. Al igual que maven, también se admite la ejecución de acciones definidas por el desarrollador al pasar por estas fases.
Para saber exactamente que fases están definidas es necesario consultar la documentación el cartridge concreto sin embargo son habituales las siguientes fases:
-
Build action hooks: pre_build, build, deploy, post_deploy.
-
Control action hooks: pre_start, post_start, pre_stop, post_stop, pre_reload, post_reload, pre_restart, post_restart, pre_tidy, post_tidy.
Los scripts de control, admiten especificar un cartridge concreto dentro del gear, por si, por ejemplo, queremos realizar acciones específicas en el arranque/parada de una base de datos.
pre_start_{cartridge}Para codificar acciones asociadas a fases debemos crear un script dentro del repositorio git, en la carpeta .openshift/action_hooks. El script debe tener exactamente el mismo nombre de la fase y puede estar escrito en cualquier lenguaje de script que admita Openshift (shellscript, Python, PHP, Ruby…), no estando limitado a los cartrige concretos que hayamos instalado en el gear. Para que se pueda ejecutar el script es necesario darle permisos de ejecución.
Como ejemplo, para descargar un fichero tras compilar la aplicación:
-
Creamos el script .openshift/action_hooks/build
#!/bin/bash curl -o $OPENSHIFT_DATA_DIR/cartel.png http://web.ua.es/es/expertojava/imagenes/cartel300.png -
Subimos el script al repositorio
$ git add .openshift
$ git commit -m "Adding a build hook"
$ git pushTras hacer el push, la aplicación se reiniciará y ejecutará la descarga del fichero tras completar la compilación.
| Cuando hacemos push a un repositorio, se muestra por la salida estándar tanto la subida de código como el posterior reinicio del servidor y despliegue de la aplicación. En definitiva todo el ciclo de construcción se muestra a través del comando git. Los scripts de compilación o control forman parte de este ciclo y salvo que redirijamos su salida a fichero, también aparecerá su salida estándar. |
| Si trabajamos en Windows, los permisos de ejecución no se trasladan al repositorio remoto al hacer push. Para corregir este problema habría que ejecutar el comando git update-index --chmod= +x .openshift/action_hooks/* y luego hacer de nuevo push. |
7.2.5. Transferencia de ficheros
scp
Si desplegamos una aplicación por primera vez, podemos encontrarnos con la necesidad de cargar datos iniciales en la BD o simplemente crear el modelo de datos mediante un script. En el caso de que nuestra aplicación no sea escalable, esto es sencillo con lo que conocemos: Podemos subir el script al repositorio Git, y desde una sesión SSH ejecutarlo localmente. Otra opción sería utilizar el mecanismo de port-forwarding y lanzar el script desde la máquina de desarrollo.
Una alternativa es utilizar el comando scp (secure copy)
$ scp <origen> <destino>
$ scp miscript.sql 541f1deb500446885d000683@wildfly8-djbyte.rhcloud.com:~/app-root/dataEste comando permite tanto copiar nuevos ficheros al gear, como descargarnos ficheros a local, variando las rutas de origen y destino. La ruta destino la obtenemos de los datos de conexión ssh que muestra la consola, o que se pueden obtener con el comando rhc app show <app>. A esta dirección se le añaden dos puntos y la ruta destino dentro de la máquina remota.
rsync
Es un comando similar a scp pero que permite la sincronización de ficheros entre origen y destino de forma incremental. Esto puede ser de utilidad para ficheros de log o ficheros de tipo backup, y en general para ficheros que cambien con frecuencia pero siempre de forma incremental.
La sintaxis básica del comando sería:
$ rsync <origen> <destino>
$ rsync -avz -e ssh 542ab14750044656c70000a0@wildfly8-jlzamora.rhcloud.com:~/app-root/data/prueba.png .Este ejemplo descargaría del gear un fichero a la carpeta actual. Los parámetros -avz se corresponden con archive (preservar atributos de ficheros) verbose (mostrar información detallada del proceso de sincronización) y compress (utilizar compresión en la descarga de diferencias).
Si ejecutamos este comando un par de veces y el fichero origen no cambia, veremos como en el segundo caso la información que se transmite se reduce notablemente.
7.2.6. Tareas planificadas (cron)
OpenShift aporta un cartridge específico para la utilidad de linux cron que permite ejecutar tareas planificadas. Para trabajar con tareas planificadas primero debemos añadir este cartridge a la aplicación que deseemos.
$ rhc cartridge add cronLa forma de trabajar con cron es parecida a la que hemos visto para los Action Hook scripts. Dentro del repositorio git , en la carpeta .openshift/cron/ nos encontraremos la siguiente estructura de directorios:
daily
hourly
minutely
monthly
weeklyCada carpeta se corresponde con una periodicidad de ejecución y podremos añadir los jobs (scripts) que consideremos dentro de ella. A diferencia de los hook scripts, estos pueden tener el nombre que queramos pero si se trata de un shell script se debe indicarlo en la primera línea con la cabecera estándar:
#! /bin/bashLos ficheros de los jobs también tendrán que tener el atributo de ejecución para que cron los tenga en cuenta.
Por último, como sólo trabajamos con periodicidades es posible que para algunos casos resulte limitada. Si necesitamos una planificación más exacta podemos añadir código adicional al script que trabaje con la hora del sistema. Por ejemplo, si este script se ubica en la carpeta minutely, únicamente se ejecutará en el minuto 12 de la hora actual:
#!/bin/bash
minute=$(date '+%M')
if [ $minute != 12 ]; then
exit
fi
# rest of the script7.3. Almacenamiento en disco
A efectos del desarrollador, el disco del gear no difiere demasiado de una instalación local de linux en la que usamos un usuario sin permisos de administración. De toda la estructura de directorios únicamente vamos a tener permisos de escritura en dos sitios:
-
La carpeta del gear (OPENSHIFT_HOMEDIR).
-
La carpeta temporal /tmp
La carpeta temporal, a diferencia de una máquina línux física es una carpeta es una carpeta propia de cada usuario, es decir que no hay peligro de que otros usuarios que ejecuten sus aplicaciones en la misma máquina que nosotros, tengan acceso a ficheros generados por nosotros. Esta carpeta sólo se puede utilizar en momento puntuales y sabiendo de que no hay garantías que lo que allí almacenemos se vaya a conservar. De hecho, esta carpeta se inicializa en cada reinicio del gear.
Otra ubicación importante es la carpeta de datos de OpenShift, asociada a la variable de entorno OPENSHIFT_DATA_DIR ($OPENSHIFT_HOMEDIR/app-root/data) donde si podremos guardar nuestros datos o configuración con garantias de perdurabilidad.
La carpeta git es un caso especial, si bien se podría escribir dentro de ella, todo lo que copiemos se perderá en el siguiente push al repositorio que hagamos.
| Una limitación que presenta OpenShift es que el directorio de datos es propio de cada gear y no se comparte entre los distintos gears que pueden estar ejecutando una aplicación escalable. Tampoco existe un mecanismo definido para sincronizar estos directorios de forma automática, por lo que el método recomendado para compartir información entre los gears es almacenarla en base de datos, o bien recurrir a un proveedor externo de almacenamiento, como por ejemplo Amazon S3. |
En función del tipo de gear nos vamos a encontrar con una limitación de espacio de 1Gb de espacio o 6Gb. Básicamente se tiene en cuenta:
-
El directorio /data del gear.
-
La carpeta temporal /tmp.
-
El repositorio Git.
-
Los ficheros de log de las aplicaciones y servidores.
-
Los ficheros de datos de las bases de datos.
Si nos quedamos sin espacio en un gear, todos los servicios comenzarán a fallar, así que es importante tener siempre controlado el espacio disponible. Ya sabemos una forma de obtener el espacio utilizado, y es mediante el comando quota desde una sesión SSH. Rhc nos ofrece un comando que nos dará una visión más global, mostrando el espacio utilizado y la quota para cada uno de los gears sobre los que se ejecuta nuestra aplicación:
rhc app show <app> --gears quota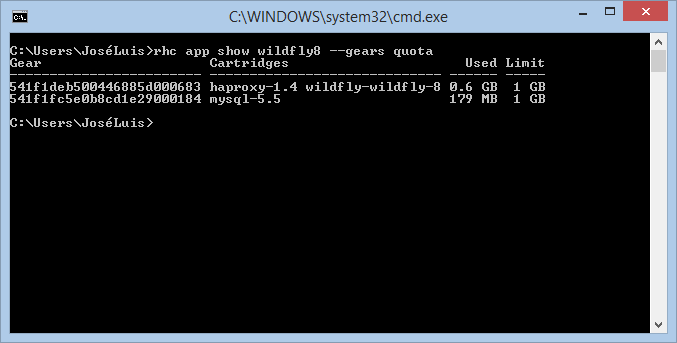
| Cuando se alcance un 90% de ocupación de disco, Openshift comenzará a mostrarnos avisos tanto al iniciar una sesión SSH como al hacer un push al repositorio Git. |
remote: error: unable to create temporary file: Disk quota exceeded7.3.1. Si ya nos hemos quedado sin espacio.
Si hemos alcanzado el límite de espacio en un gear podemos resolver el problema de varias formas:
-
Comando tidy de rhc, que elimina los ficheros de log, borra temporales y reorganiza el repositorio git.
-
Si estamos en un plan de pago podemos ampliar el espacio en disco con el siguiente comando:
$ rhc cartridge storage <cartridge> -a <app> --set capacidad(GB)
$ rhc cartridge storage php-5 -a racer --set 5gb| Todos los gear comienzan con un 1Gb de datos y se pueden ampliar hasta un máximo de 30Gb |
7.4. Copias de seguridad
Con lo aprendido hasta ahora, es perfectamente posible definir un proceso que de forma periódica, realice una copia de seguridad de los datos de nuestra aplicación. Deberíamos crear un job que se ejecute con la periodicidad que creamos conveniente y que ejecute las siguientes tareas:
-
Detener la aplicación
-
Exportar los datos de la BD a fichero.
-
Comprimir y transferir la información de BD a otra ubicación (recomendable por seguridad y porque el espacio en el gear es limitado).
Como ejemplo, se podría subir la información a DropBox o cualquier otro almacenamiento en Cloud. En este enlace se muestra un ejemplo: https://github.com/andreafabrizi/Dropbox-Uploader
-
Comprimir y transferir la información de los log de aplicación.
-
Limpiar manualmente temporales y logs (desde la sesión ssh no está disponible el comando tidy).
-
Ejecutar git gc en la carpeta del repositorio Git .git/<app>/tmp_
-
Eliminar temporales en /tmp, OPENSHIFT_LOG_DIR y OPENSHIFT_TMP_DIR
A continuación veremos las herramientas de backup que ofrece OpenShift.
-
-
Iniciar de nuevo la aplicación.
7.4.1. Deployment History
En ocasiones, al desplegar una nueva versión de nuestra aplicación nos podemos encontrar con que no está funcionando como debería. El estudiar qué ha ocurrido, subir código nuevo al repositorio Git y despliegar puede resultar demasiado lento y mientras tanto la aplicación no está dando servicio o puede estar funcionando de forma incorrecta.
Por defecto no está activado pero OpenShift pede mantener un histórico de despliegues y darnos el mecanismo para desplegar una versión previa a la problemática. Para activar este mecanismo de histórico de despligues hay que ejecutar el siguiente comando:
rhc app-configure --keep-deployments <num>La información se almacenará en el gear, en la carpeta app-deployments clasificada por timestamp y por "id" de despliegue:
[wildfly8-jlzamora.rhcloud.com app-deployments]\> ls
2014-10-03_11-32-48.438 2014-10-03_11-51-38.310 by-id current
[wildfly8-jlzamora.rhcloud.com app-deployments]\> ls by-id
88410fa9 b901caed
[wildfly8-jlzamora.rhcloud.com app-deployments]\>Desde la máquina de desarrollo podemos listar las versiones almacenadas con el comando deployment list:
# rhc deployment list <app>
$ rhc deployment list wildfly8
5:33 PM, deployment b901caed
5:52 PM, deployment 88410fa9Cuando tengamos claro qué versión de la aplicación queremos desplegar, la seleccionaremos con el comando deployment activate:
# rhc deployment activate <id despliegue> -app <app>
$ rhc deployment activate b901caed -app wildfly8
Activating deployment 'b901caed' on application wildfly8 ...Uno de los pros de esta funcionalidad es que de forma rápida podemos revertir el estado de nuestra aplicación a un punto anterior. La principal limitación es que sólo afecta al código de aplicación y sus dependencias, no incluye la configuración del servidor de aplicaciones, la definición de la base de datos ni su contenido.
7.4.2. Application Snapshots
Las snapshots son copias de seguridad de la aplicación al completo, código, base de datos y cualquier información que en los catridge instalados se haya catalogado como exportable. El resultado es un fichero tar.gz con toda la información, que puede ser utilizado para restaurar la aplicación en otro momento.
Tanto la creación del snapshot como la restauración son procesos que necesariamente requieren parar la aplicación temporalmente por lo que hay que escoger el momento adecuado para este tipo de backup.
El comando para generar un snapshot es el siguiente:
& rhc snapshot-save <app>
Pulling down a snapshot of application 'wildfly8' to wildfly8.tar.gz ... doneLos snapshot se almacenan en la máquina de desarrollo y salvo que especifiquemos otro nombre para el fichero, se sigue la nomenclatura <app>.tar.gz y se sobreescribe en sucesivas ejecuciones.
Si queremos restaurar, el comando a utilizar es snapshot-restore
& rhc snapshot-restore <app>7.5. Procedimientos
7.5.1. Depuración de aplicaciones
En casos excepcionales es posible iniciar un proceso de depuración en remoto de una aplicación desplegada en OpenShift para ello tenemos que realizar los siguientes cambios:
-
Añadir el marker enable_jpda a la aplicación que queremos depurar. Salvo que tengamos habilitado el hot deploy el servidor se reiniciará y arrancará en modo depuración.
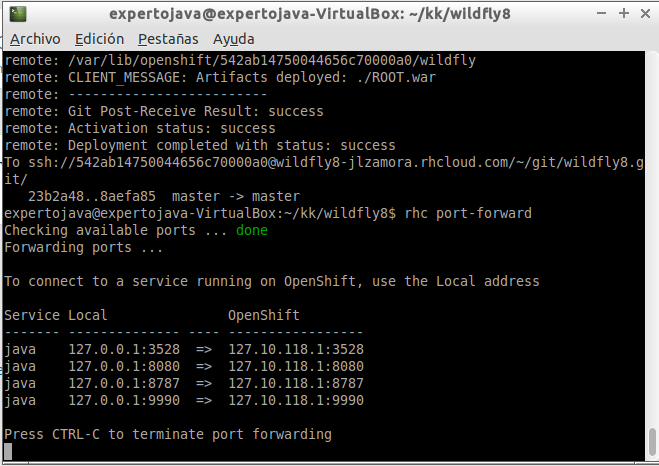
-
Ejecutar el comando port-forward de rhc. Deberá mostrarse una redirección del puerto remoto 8787 a nuestra máquina.
-
Abrir el proyecto maven de la aplicación en IntelliJ.
-
Crear una nueva configuración de depuración en IntelliJ en modo remoto.
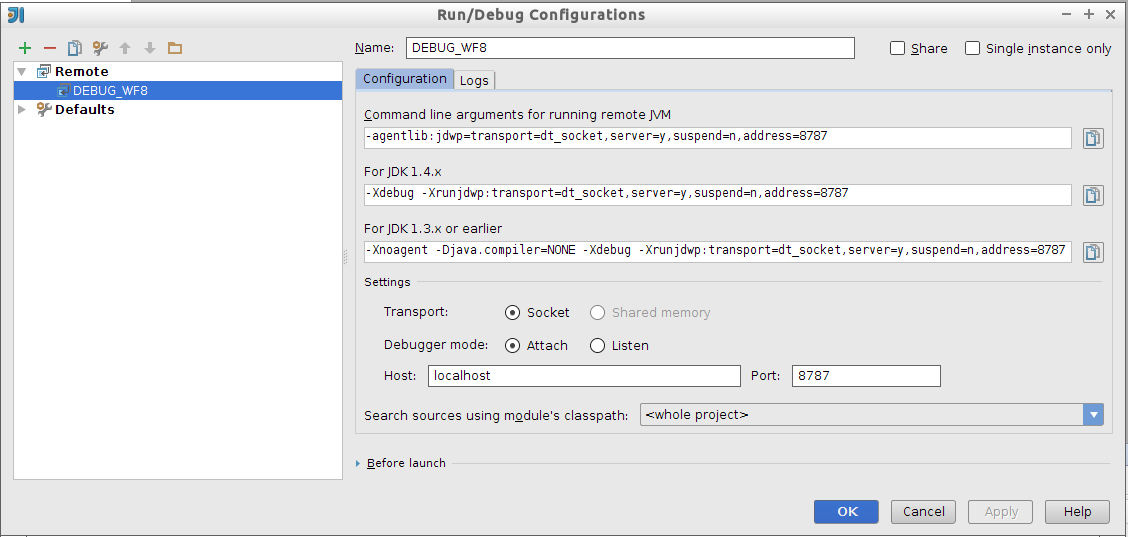
Es importante seleccionar como sistema de transporte el tipo Socket y el puerto local al que se redirige el puerto remoto de depuración. También se indica en el último desplegable dónde localizar el código fuente del proyecto que se va a depurar.
Si ejecutamos la configuración de depuración, nos conectaremos directamente al proceso remoto en modo debug, y podremos depurar la aplicación como si se ejecutase localmente, aunque el precio a pagar es que la depuración se ejecutará con mucha mayor lentitud.
7.5.2. Generar un threaddump
Un threaddump o volcado de hilos es un procedimiento que permite recoger en un fichero, el estado de todos los hilos en ejecución de una aplicación, y si están en ejecución, el código que se está ejecutando. Obtener varios threaddump en un intervalo de tiempo puede darnos información útil para identificar problemas de bloqueos o lentitud de procesamiento.
La forma de obtener este volcado es mediante un comando de rhc:
$ rhc threaddump -a <app>| El catridge de Wildfly a fecha de estos apuntes no está redirigiendo correctamente la salida del threaddump al fichero temporal que espera el comando threaddump. En su lugar, hay que consultar el server.log directamente, o mediante el comando tail de rhc. |
7.5.3. Despliegue manual de las aplicaciones
Aunque bien podría haberse implementado como markers, hay parte de la configuración de una aplicación que se resuelve mediante el comando rhc app-configure. Si lo ejecutamos sin parámetros nos mostrará la configuración actual de la aplicación:
wildfly8 @ http://wildfly8-jlzamora.rhcloud.com/ (uuid: 542ab14750044656c70000a0)
---------------------------------------------------------------------------------
Deployment: auto (on git push)
Keep Deployments: 1
Deployment Type: git
Deployment Branch: masterPero también admite los siguientes parámetros:
$ rhc app-configure <app> [parámetros...]- --[no-]auto-deploy
-
Activar/desactivar la compilación y despliegue automático ante un push al respositorio. Por defecto TRUE
- --keep-deployments INTEGER
-
Controla la profundidad del histórico de despliegues de una aplicación. Por defecto 1.
- --deployment-branch BRANCH
-
Permite especificar la rama del repositorio git desde el cual queremos compilar y desplegar la aplicación. Por defecto master.
- --deployment-type git|binary
-
Permite especificar si queremos desplegar un binario o una aplicación compilada a partir del repositorio Git. Por defecto git.
Si desactivamamos la función de auto-deploy podemos desacoplar la subida de cambios al repositorio del despliegue y gestionar los despliegues de forma manual, mediante el comando app-deploy
[source,console] ---- $ rhc app-deploy <ref> --app <app> ----
Donde ref es una etiqueta, rama o commit específico del repositorio Git (por defecto utilizad master)
Admite los siguientes parámetros que se *superponen* a la configuración especificada vía markers:
- --[no-]hot-deploy
-
Desplegar (o no ) sin reiniciar el servidor.
- --[no-]force-clean-build
-
Recompila todo sl proyecto (o no) antes de desplegar, eliminando cualquier artefacto temporal previamente generado.
7.5.4. Compilación de proyectos con dependencias propias
En algunos proyectos es necesario referenciar a módulos precompilados de los cuales no tenemos el código fuente o no queremos incluirlo en el repositorio de nuestra aplicación. Estos módulos tampoco están disponibles en ningún repositorio público y si disponemos de un repositorio privado, es muy probable que no lo tengamos configurado para ser accesible desde internet. La solución a este problema pasaría por incorporar el artefacto al repositorio maven local mediante una acción personalizada previa a la compilación. Los pasos a realizar serían los siguientes:
-
Añadir el jar/war a la raíz del repositorio git.
-
Crear un script asociado a la fase prebuild que ejecute un "maven install":
#Ejemplo para ficheros jar mvn install:install-file -Dfile=$OPENSHIFT_REPO_DIR/fichero.jar -DgroupId=<grupo>-DartifactId=<artefacto> -Dversion=<versión> -Dpackaging=jar -
Referenciar la dependencia en el pom de la aplicación como una dependencia normal, el scope debe ser compile para que se incluya en el empaquetado finall de la aplicación.
7.5.5. Despliegue de aplicaciones compiladas previamente.
Como ya sabemos, la forma normal de desplegar aplicaciones en OpenShift pasa por subir código fuente a un repositorio Git interno a OpenShift, pero también se da soporte al despliegue de aplicaciones previamente compiladas aunque para ello hay que realizar una serie de cambios en el repositorio. Los pasos son los siguientes:
-
Crear una nueva aplicación y clonar su repositorio en nuestra máquina.
-
Dentro del repositorio, eliminar el código fuente completamente, con el comando:
& git rm -r src/ pom.xml -
Copiar el war/ear a la carpeta deployments y hacer commit y push.
-
Limpiar el repositorio git y logs con el comando rhc app tidy
Tal y como comentamos en la sesión anterior si el war tiene como nombre ROOT, la URL de acceso será la URL indicada para nuestra aplicación. Si por el contrario tiene otro nombre, la aplicación se encontrará en la URL inicial más el nombre de la aplicación como contexto raiz.
7.6. Referencias
-
WildFly Cartridge https://developers.openshift.com/en/wildfly-overview.html
-
Variables de entorno https://developers.openshift.com/en/managing-environment-variables.html
-
Depuración en remoto http://planet.jboss.org/post/debugging_and_browsing_openshift_applications_in_eclipse
-
Action hooks http://openshift.github.io/documentation/oo_user_guide.html#action-hooks
-
Openshift v3 https://www.openshift.com/blogs/openshift-v3-platform-combines-docker-kubernetes-atomic-and-more
7.7. Ejercicios de Características IaaS+ de OpenShift
Vamos a realizar una serie de ejercicios en torno a un aplicación que podrían acercarnos a una situación real en la que se desarrolla y despliega una aplicación en una plataforma cloud. En primer lugar vamos a crear la aplicación desde cero apoyándonos en una herramienta de generación de código, de nombre JBoss Forge.
Forge funciona como un shell con comandos especializados en la generación de código según las funcionalidades que nuestra aplicación va a necesitar. Por ejemplo, si vamos a trabajar con acceso a base de datos JPA sólo tenemos que declararlo y definir posteriormente nuestras entidades.
7.7.1. Instalación de Forge
Para instalar la última versión basta con ejecutar el siguiente comando:
curl http://forge.jboss.org/sh | sh| Con este procedimiento se descarga siempre la última versión disponible, que a la fecha de redacción de estos apuntes es la 3.0 Alpha. En la carpeta de ejercicios de la sesión07 tenéis un script alternativo forge.sh que descarga la última versión estable, y es la que se debe utilizar. |
Una vez instalado, basta con ejecutar forge para iniciar la herramienta:
De forma similar a la herramienta CLI de WildFly, podemos movernos por la estructura del proyecto mediante el comando cd y podemos visualizar ficheros o ejecutar acciones sobre ellos.
Dado que acabamos de instalar la aplicación, añadiremos un par de plugins mediante los comandos:
addon-install-from-git --url https://github.com/forge/addon-arquillian.git --coordinate org.arquillian.forge:arquillian-addon
addon-install-from-git --url https://github.com/forge/angularjs-addon.git --coordinate org.jboss.forge.addon:angularjs7.7.2. Autoescuela
Utilizando Forge, vamos a crear una aplicación sencilla de para la gestión de las clases práctricas de una autoescuela (muy simplificada). Definiremos tres entidades distintas:
-
Alumno
-
Profesor. Un profesor puede dar clase a varios alumnos, mientras que un alumno únicamente recibe clase de un profesor.
-
Vehículo. En este caso un profesor puede utilizar varios vehículos y un vehículo puede ser utilizado por varios profesores, en distintas clases de prácticas.
Mediante Forge vamos a crear nuestra aplicación para gestionar las prácticas. Ejecutaremos los siguientes comandos:
project-new --named autoescuela --topLevelPackage org.expertojava.paas
jpa-setup
servlet-setup
cdi-setup
rest-setup
scaffold-setup
constraint-setup
jpa-new-entity --named Alumno
jpa-new-entity --named Profesor
jpa-new-entity --named Vehiculo
jpa-new-field --named modelo --type String --length 100
jpa-new-field --named matricula --type String --length 7
constraint-add --onProperty modelo --constraint NotNull
constraint-add --onProperty matricula --constraint NotNull
constraint-add --onProperty matricula --constraint Size --max 7
cd ..
cd Profesor.java
jpa-new-field --named nombre --type String --length 100
jpa-new-field --named vehiculos --type org.expertojava.paas.model.Vehiculo --relationshipType Many-to-Many;
jpa-new-field --named alumnos --type org.expertojava.paas.model.Alumno --relationshipType One-to-Many;
constraint-add --onProperty nombre --constraint NotNull
cd ..
cd Alumno.java
jpa-new-field --named nombre --type String --length 100
jpa-new-field --named direccion --type String --length 300
jpa-new-field --named telefono --type String --length 9
constraint-add --onProperty nombre --constraint NotNull
constraint-add --onProperty telefono --constraint Size --max 9
scaffold-generate --provider Faces --overwrite --targets org.expertojava.paas.model.*
rest-generate-endpoints-from-entities --targets org.expertojava.paas.model.*
buildCon estas instrucciones habremos creado un nuevo proyecto autoescuela, definido las entidades que intervienen con sus atributos y generado tanto un API REST para su mantenimiento como las páginas JSF necesarias para implementar un CRUD de los datos. Por defecto esta aplicación utilizará el Datasource java:jboss/datasources/ExampleDS que viene definido por defecto en WildFly y que trabaja con una base de datos en memoria, H2.
| Por defecto genera un ID automático para todas las entidades. Para hacerlo transparente, la herramienta de scaffolding de JSF oculta automáticamente los campos que llevan la anotacion de Generated. Además de generar una interfaz en JSF, también es posible generar el Scaffolding AngularJS. |
| Forge no es una herramienta "neutra" en el sentido de que el proyecto Maven resultante tiene dependencias específicas de JBoss. Podéis sustituirlas por la especificación Java EE 7.0 como se explicaba en las primeras sesiones. Todos los servidores de aplicaciones tienen integrada una base de datos y un datasource por defecto. Podéis eliminar directamente la etiqueta <jta-data-source> de la unidad de persistencia para utilizarlo. |
7.7.3. Despliegue básico de la aplicación (0.2 punto)
Se pide:
-
Desplegar la aplicación en el servidor WildFly local de vuestra máquina virtual.
-
Añadir el perfil correspondiente para openshift y desplegarla en una aplicación OpenShift, de nombre , autoescuela.
7.7.4. Configuración de la aplicación OpenShift (0.6 puntos)
En este ejercicio debéis ajustar la configuración de la aplicación en OpenShift a unos requerimientos:
-
Queremos poder aplicar cambios en el menor tiempo posible, esto es evitar reiniciar WildFly en cada cambio que hagamos en la aplicación.
-
Por seguridad queremos mantener hasta 3 versiones de la aplicación por si en alguna modificación nos hemos equivocado y queremos deshacer los cambios.
-
Sustituir la BD utilizada por defecto H2, por una base de datos PostgreSQL. Debéis crear un Datasource llamado autoLocal que acceda a la base de datos y configurar la unidad de persistencia para que lo utilice.
Para acceder a PostgreSQL hay que modificar la configuración de la unidad de persistencia:
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>-
Configurar un sistema de copias de seguridad, queremos que de forma diaria a las 01:00 AM se haga un backup del contenido de la base de datos.
El script para esta tarea podría ser el siguiente:
#!/bin/bash
if [ `date +%H:%M` == "18:57" ]
then
DATE=`date +"%Y-%m-%d"`
FILE="$OPENSHIFT_APP_NAME-$DATE.sql.gz"
INIT_PATH=$OPENSHIFT_DATA_DIR/$FILE
BACKUP_DIR=$OPENSHIFT_DATA_DIR/sqlbackup
if [ ! -d "$BACKUP_DIR" ]; then
mkdir $BACKUP_DIR
fi
pg_dump $OPENSHIFT_APP_NAME | gzip > $INIT_PATH
mv $INIT_PATH $BACKUP_DIR/$FILE
fi-
Por ultimo, queremos mantener una copia sincronizada de los backups que hay en OpenShift con lo que debéis definir una instrucción que permita traerse los cambios que se detecten sobre la carpeta sqlbackup. Incluidla en un fichero llamado soluciones.txt.
7.7.5. Uso de una base de datos externa en Cloud (0.4 puntos)
Por último, vamos a probar a sustituir la base de datos PostgreSQL integrada en el Gear por una base de datos externa proporcionadad por otro proveedor. Para ello, debéis acceder al MarketPlace de OpenShift y crear una cuenta en ElephantSQL. El acceso gratuito proporciona una base de datos de 20Mb con hasta 7 conexiones concurrentes. Debéis crear un nuevo datasource en WildFly, de nombre autoRemoto, que apunte a esta base de datos.
Cuando os déis de alta en ElephantSQL, veréis que el proveedor os facilita una conexión con el siguiente formato:
postgres://sbdivvym:DBRXn9a3ewb8evi4qaFcRy5y_LpF9olh@babar.elephantsql.com:5432/sbdivvymSi utilizásemos el cliente de PostgreSQL podríamos utilizar esta cadena de conexión tal cual está definida. Sin embargo para crear un Datasource debemos descomponerla en sus partes básicas:
postgres://[usuario]:[password]@[hostname:[puerto]/[instancia BD]Por último y muy importante, la configuración del datasource la tenéis que hacer utilizando variables de entorno. Es decir, la configuración del datasource no estará definida directamente en WildFly sino que referenciará a variables que vais a tener que definir. Como sugerencias de nombres:
ELEPHANTSQL_USER
ELEPHANTSQL_PASSWORD
ELEPHANTSQL_HOSTNAME
ELEPHANTSQL_PORT
ELEPHANTSQL_DBINSTANCE7.7.6. Entrega
En esta sesión hay que presentar una copia del repositorio autoescuela eliminando la configuración de git como ya hemos hecho en sesiones anteriores y un fichero llamado soluciones.txt con el comando de descarga solicitado en el segundo ejercicio.